Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThe Spring Cloud Data Flow team is pleased to announce the 1.5.0 GA release. Follow the Getting Started guides for Local Server, Cloud Foundry, and Kubernetes.
UI Improvements
Spring Boot, Spring Cloud Stream 2.0, and Spring Cloud Task 2.0 Support
Updated Application Starters
Metrics Improvements
Nested splits for Composed Tasks
Kubernetes Improvements
Updated File Ingest sample
We have continued to improve the UI/UX of the Dashboard. We hope that you will immediately notice an overall lighter weight design. The Tasks tab has been rewritten to match the UX styling of the other tabs. A new paginator component has been added to all the list pages. Switching from a list of 20, 30, 50, or 100 items per page is possible. This further simplifies the bulk operation workflows.
The updated Stream Builder tab makes is easy to deploy Stream Definitions and update deployed streams. You can edit application and deployment properties as well as change the version of individual applications in the stream and re-deploy. Data Flow’s integration with Skipper handles the upgrade process, allowing for easy rollback in case the upgrade doesn’t go as planned. The Stream Builder tab also includes many optimizations, including better form validation and eager error reporting. Try it out!
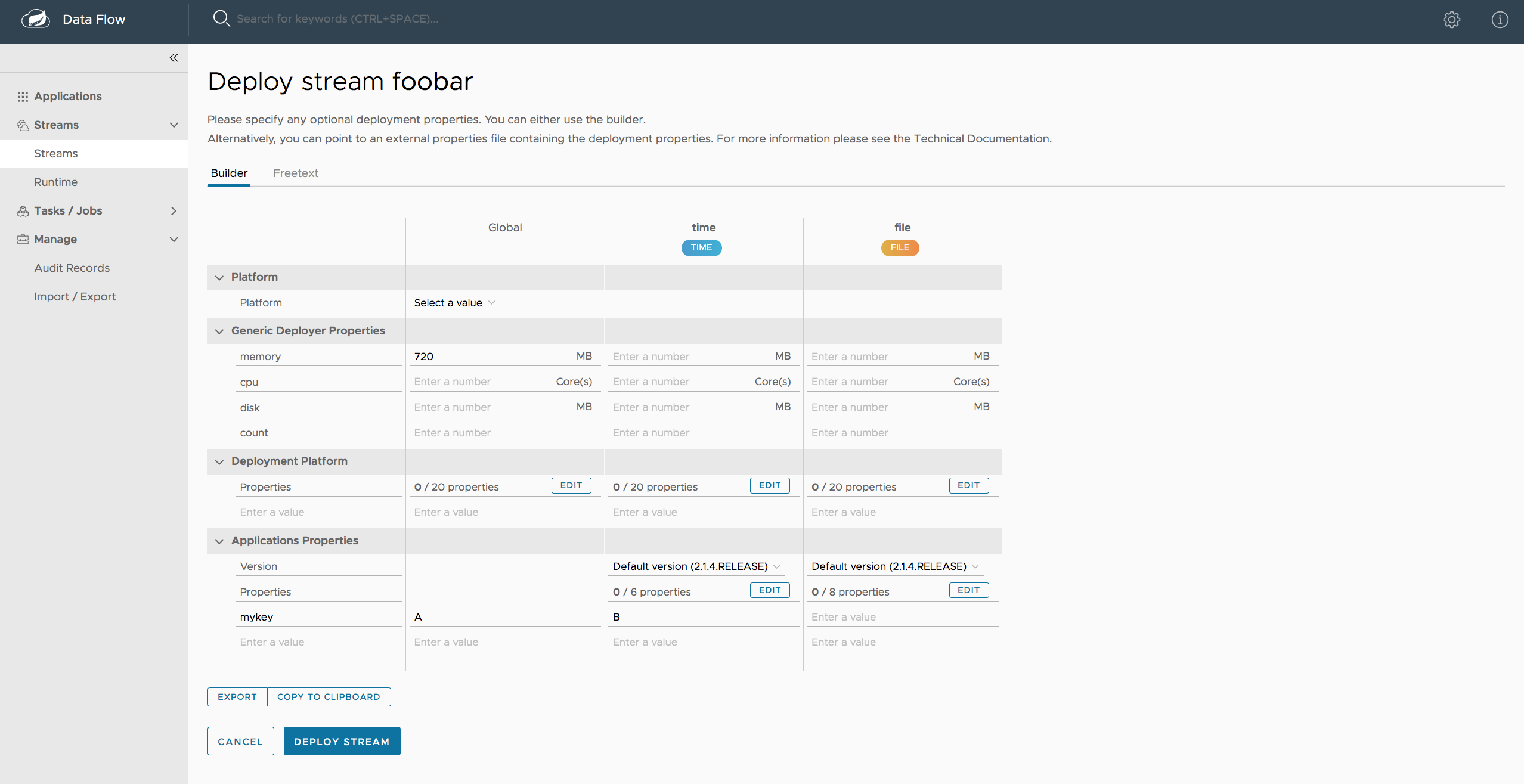
There has also been a significant amount of refactoring to optimize the code base and prepare for future extensions and feature additions. End-to-end testing with Selenium and SauceLabs has also been added.
We now support deploying Spring Boot 2.0 and Spring Cloud Stream 2.0-based applications. Read the section on Metrics for related features.
A new GA release of the Stream App Starters - Celsius.SR2 fixes a bug using Rabbit source/sink apps on PCF and updates the python apps. A new GA release of Task App Starters - Clark SR1 removes some outdated tasks and includes a new release of the composted task runner.
The release train Darwin RC1 updates the stream application starters to be based on Spring Boot & Spring Cloud Stream 2.0. A gRPC processor has been added. Import URLs can be found here.
The release train Dearborn M1 updates the task application starters to be based on Spring Boot & Spring Cloud Task 2.0.
The Spring Cloud Stream Application Initializr has been updated to support customizing Darwin-based apps.
The Spring Cloud Stream Application Starters library provides a couple utility classes to enrich micrometer-based monitoring by adding tags to identify streams and the Cloud Foundry environment.
An updated Spring Cloud Stream Application Initializr now lets you add micrometer libraries to both Boot 1.5- and 2.0-based applications.
Two new sample applications showcase using Micrometer with Data Flow. The first sample uses InfluxDB and Grafana. The second sample uses Prometheus and Grafana.
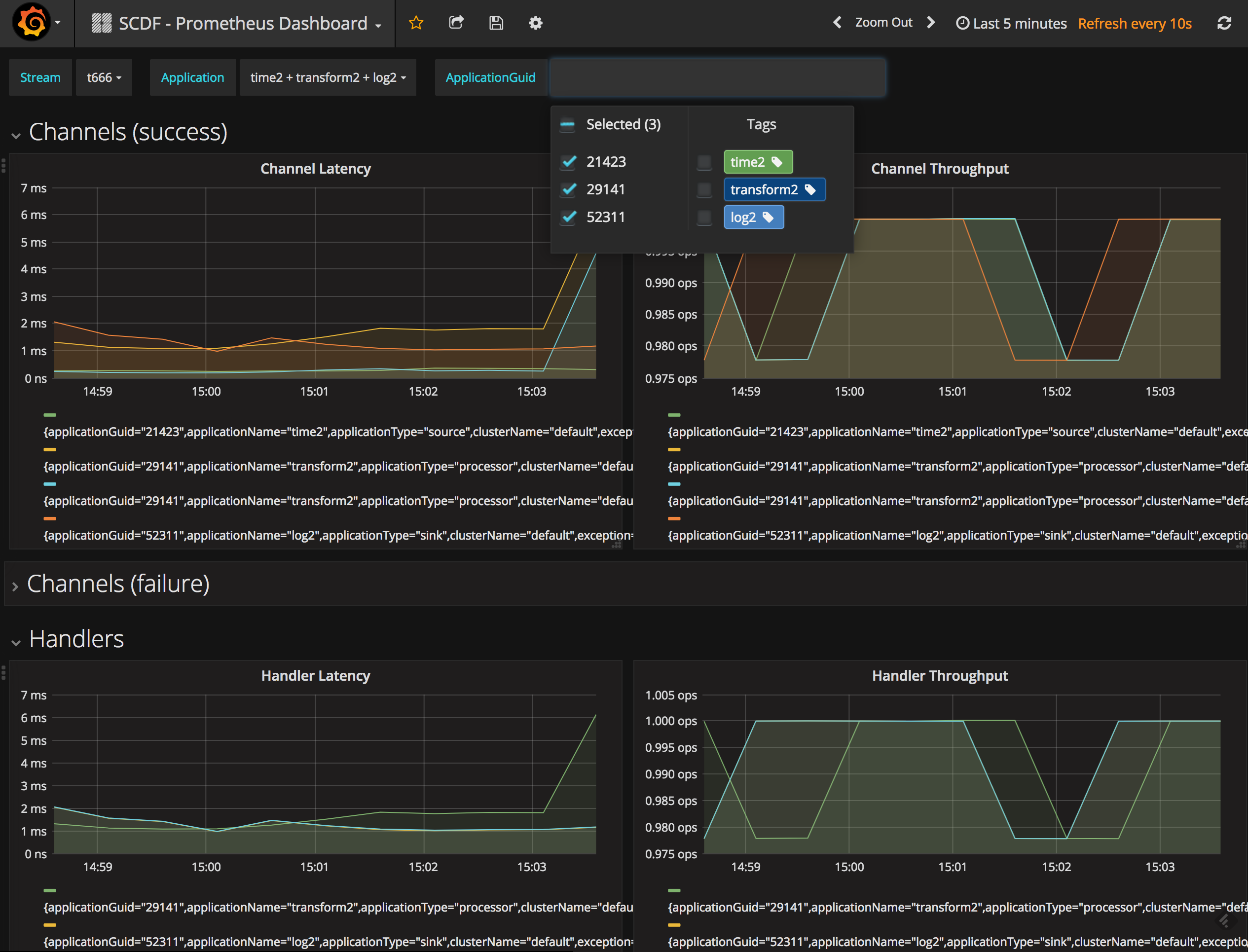
Another work in progress that is quite interesting to follow is the use of the Promregator project to monitor applications deployed on Cloud Foundry by using Prometheus. Follow these instructions to kick the tires.
The 2.0 RC1 release of Metrics Collector is based on Spring Boot 2.0 and Spring Cloud Stream 2.0. The Metrics Collector server supports collecting metrics from streams that contain only Boot 1.x or 2.x apps as well as streams that contain a mixture of Boot versions. A consistent representation of the throughput rates will be captured and propagated over to Data Flow’s Dashboard.
Due to popular demand, this release added DSL support to interpret “nested splits” in composed tasks. The Flo Dashboard and Shell tooling automatically adapt to nested splits.
Here is how it looks in the Flo Dashboard for the DSL expression:
<<extractFromFTP && cleanseFiles || extractFromS3 && splitTransform> && merge || extractfromOracle>
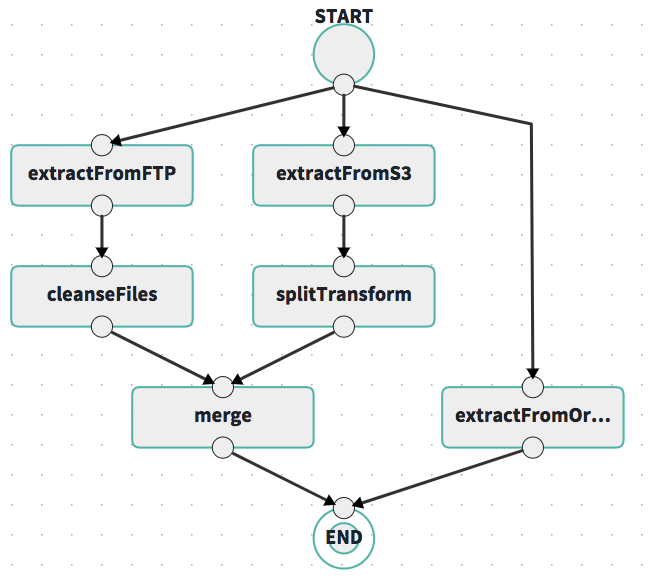
To use this feature, you have to register the 1.1.1.RELEASE version of the Composed Task Runner in SCDF.
For Maven users
maven://org.springframework.cloud.task.app:composedtaskrunner-task:1.1.1.RELEASE
and for Docker users
docker:springcloudtask/composedtaskrunner-task:1.1.1.RELEASE
The client and the cluster version compatibility have improved due to Core Workload APIs going GA. For example, a StatefulSet deployment for a partitioned streaming-pipeline dynamically resolves the version compatibility.
Extending the annotation support added to the “pod” configurations, it is now also possible to add custom annotations to “jobs” deployment.
Deploying with custom liveness and readiness probe ports is now supported.
While using Skipper with Data Flow, it is already possible to target application deployment to multiple platform backends. However, we did not support targeting multiple Kubernetes platforms. Now you can. :)
The Kubernetes server now supports using a private Docker registry on a per-application basis.
A common use case is to detect new files on an FTP site, download them, and launch a batch job. We have added a new File Ingest sample for this use case. In the coming months, we will continue to improve the design and features. You can follow along here.
A growing number of new issues dealt with the ability to individually and globally override JAVA_OPTS for applications running on Cloud Foundry. We added a deployer property (deployer.yourapp.cloudfoundry.javaOpts) to support setting this specific environment variable.
Switched to Hikari connection pool and restructure code to use fewer connections.
Several bug fixes in underlying deployer libraries.
As always, we welcome feedback and contributions, so please reach out to us on Stackoverflow or GitHub or via Gitter.
Please try it out, share your feedback, and consider contributing to the project!

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all