Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreLarge language models are text-in, text-out systems — their interface is natural language.
![]()
Natural language is a great interface for humans and a poor one for software. The moment downstream code needs to route on a field, persist a value, or branch on a result, the conversation has to become a record. Structured output bridges that gap. The model is steered to produce text conforming to a schema; the application parses it back into a typed object the rest of the codebase can treat like any other domain type.
Spring AI has supported structured output since day one through ChatClient.call().entity(...). Spring AI 2.0 adds two new dials to it — provider-native structured output and self-correcting schema validation. Defaults are unchanged, so existing code keeps working.
This post walks through structured output, starting with a simple, working case first, then add reliability piece by piece.
Define a Java record for the shape you want back:
record ActorsFilms(String actor, List<String> movies) {}
Ask ChatClient to populate it. Instead of finishing the call with .content() — which returns the raw text reply — finish with .entity(...) and pass your target type:
ActorsFilms films = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorsFilms.class);
That's it. The result is a typed ActorsFilms you can pass to the rest of your code:
System.out.println(films.actor()); // "Tom Hanks"
System.out.println(films.movies()); // ["Forrest Gump", "Cast Away", ...]
.entity(...)is.call()-only. Typed parsing requires the complete response, so it isn't available on the streaming path (.stream()returns text chunks, not typed objects). This applies to every variant covered below —Class,ParameterizedTypeReference, custom converter, with or without the new dials.
Behind the scenes, Spring AI did three things: a schema generator turned your ActorsFilms record into a JSON schema, that schema was appended to the prompt's system context, and the model's JSON answer was then handed to a type converter that parsed it back into your record.
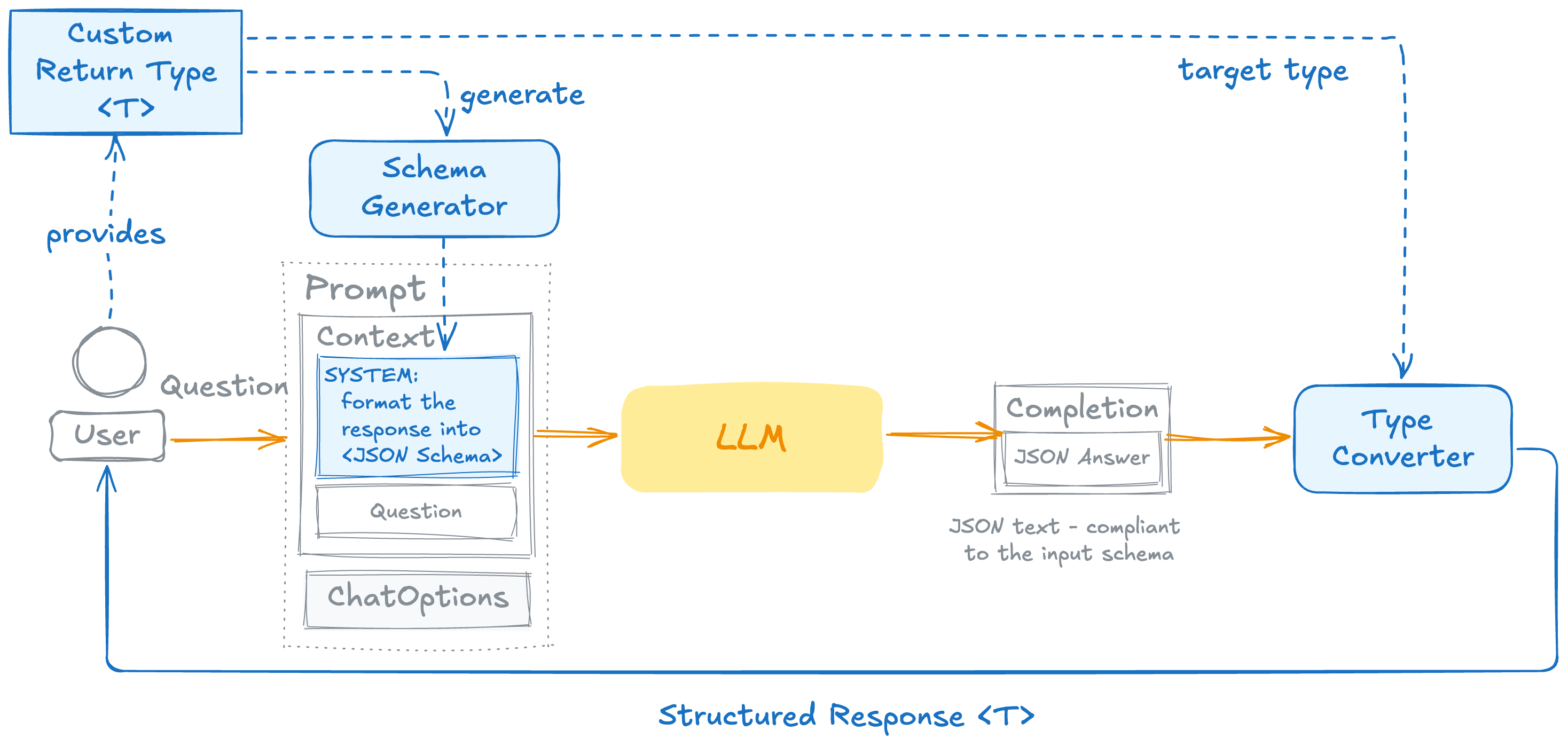
This works on every model Spring AI supports — there's nothing provider-specific about it.
It also has no guarantees. The model is asked to produce JSON matching the schema, not forced to. Most of the time it complies. Sometimes it doesn't — it returns an extra field, omits a required one, or wraps the JSON in prose. When that happens, the parser throws.
The next two sections fix that, one approach at a time.
validateSchema()The simplest way to handle malformed output is to detect it and retry. Spring AI 2.0 does this automatically with a single switch:
ActorsFilms films = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorsFilms.class, spec -> spec.validateSchema());
The spec -> spec.validateSchema() consumer turns on a self-correcting retry loop:
ActorsFilms.actor", "expected array, got string") is appended to the user prompt, and the call is re-issued — up to 3 attempts by default.The model sees the specific error on each retry. The second attempt isn't a blind re-try; the model knows what was wrong and can correct it.
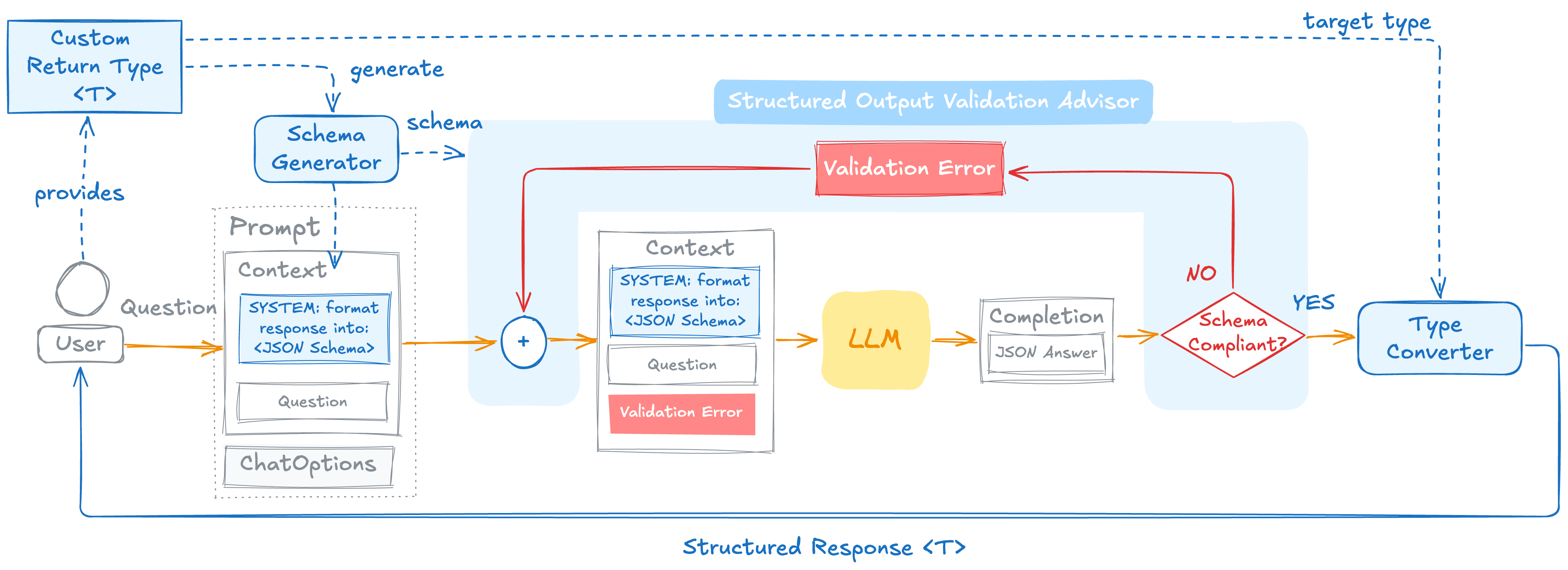
This is powered by StructuredOutputValidationAdvisor, a recursive advisor that's auto-registered when you call validateSchema(). You don't have to wire anything; the switch is the entire configuration.
StructuredOutputValidationAdvisor defaults to 3 retry attempts and uses Spring AI's default JsonMapper. To customize — for example, more attempts, a pre-supplied schema, or a different mapper — build your own instance and register it on the ChatClient. An explicitly registered advisor replaces the auto-registered one:
var validationAdvisor = StructuredOutputValidationAdvisor.builder()
.outputType(ActorsFilms.class)
.maxRepeatAttempts(5)
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(validationAdvisor)
.build();
useProviderStructuredOutput()validateSchema() is a response-side safety net — it catches bad output after the fact and retries. The complementary approach is a request-side constraint: tell the model's provider, at the API level, that the response must conform to a schema. Most modern providers support this (OpenAI's Structured Outputs, Anthropic's structured output extension, Gemini's responseSchema, Mistral's response_format).
Spring AI exposes it portably with another switch on the same consumer:
ActorsFilms films = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorsFilms.class, spec -> spec.useProviderStructuredOutput());
What changes at the wire level:
Supported providers as of 2.0: OpenAI, Anthropic, Google GenAI , Mistral AI, Ollama (model-specific). The same .useProviderStructuredOutput() call works regardless of which is wired in.
Spring AI detects support by checking whether the model's chat options implement the StructuredOutputChatOptions interface. If not, the flag is silently ignored and the call falls back to the prompt-based default.
Compatibility. Older or non-supporting models would reject the request, and the prompt-based default works everywhere. A few known limitations are worth mentioning even on supported providers:
$ref, deeply nested arrays, allOf/anyOf/oneOf, regex patterns, and recursive types are common limitations. The shape drift this can cause is exactly what validateSchema() (next section) is good at catching.qwen may emit their internal reasoning trace as plain text instead of JSON, causing parse errors. Use a non-reasoning model, or combine native output with validateSchema() so misbehaving responses are retried.record FilmographyList(List<ActorsFilms> films) {}).The two switches solve different problems and compose naturally:
ActorsFilms films = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorsFilms.class, spec -> spec
.useProviderStructuredOutput()
.validateSchema());
useProviderStructuredOutput() minimizes the chance of malformed output by constraining the model at the API level. validateSchema() catches the residual cases — provider edge cases, the Ollama reasoning quirk above — and corrects them automatically.
Reach for both when downstream code can't tolerate shape drift — when a missing field or wrong type would corrupt state, throw later, or silently misroute.
.entity(Class) is for concrete classes. For generic types — List<ActorsFilms>, Map<String, ActorsFilms> — use ParameterizedTypeReference:
List<ActorsFilms> films = chatClient.prompt()
.user("Generate filmographies for three random actors.")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});
The same EntityParamSpec consumer works:
List<ActorsFilms> films = chatClient.prompt()
.user("Generate filmographies for three random actors.")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {},
spec -> spec.validateSchema());
One thing to watch out for: OpenAI's Structured Outputs API doesn't accept a top-level array. If you combine List<...> with .useProviderStructuredOutput() on OpenAI, the call will fail. The fix is a one-line wrapper record:
record FilmographyList(List<ActorsFilms> films) {}
FilmographyList result = chatClient.prompt()
.user("Generate filmographies for three random actors.")
.call()
.entity(FilmographyList.class, spec -> spec.useProviderStructuredOutput());
The default prompt-based flow has no such restriction — top-level arrays work fine without useProviderStructuredOutput().
.entity(...) returns only the parsed object. If you also need the underlying ChatResponse — for token usage, observability metadata, or anything beyond the entity — use .responseEntity(...):
ResponseEntity<ChatResponse, ActorsFilms> result = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.responseEntity(ActorsFilms.class);
ActorsFilms films = result.entity();
ChatResponse raw = result.response();
long totalTokens = raw.getMetadata().getUsage().getTotalTokens();
It has the same overload set as .entity(...) — Class, ParameterizedTypeReference, and the EntityParamSpec consumer all apply.
The built-in BeanOutputConverter is strict: it expects the model's response to be parseable JSON, full stop. But models often wrap their JSON in markdown code fences:
Here's the filmography:
```json
{ "actor": "Tom Hanks", "movies": ["Forrest Gump", "Cast Away"] }
```
BeanOutputConverter will throw on the first H of "Here's". The common fix is a custom converter that strips fences and extracts the JSON before delegating to the default parser:
public class LenientJsonOutputConverter<T> implements StructuredOutputConverter<T> {
private static final Pattern FENCE = Pattern.compile("```(?:json)?\\s*([\\s\\S]*?)```");
private final BeanOutputConverter<T> delegate;
public LenientJsonOutputConverter(Class<T> targetType) {
this.delegate = new BeanOutputConverter<>(targetType);
}
@Override public String getFormat() { return delegate.getFormat(); }
@Override public String getJsonSchema() { return delegate.getJsonSchema(); }
@Override
public T convert(String source) {
var matcher = FENCE.matcher(source);
String json = matcher.find() ? matcher.group(1).trim() : source.trim();
return delegate.convert(json);
}
}
Pass it to .entity(...) instead of a Class:
ActorsFilms films = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(new LenientJsonOutputConverter<>(ActorsFilms.class));
Because this converter delegates getJsonSchema() to the underlying BeanOutputConverter, both new dials still work — validateSchema() and useProviderStructuredOutput() operate against the same schema the default converter would use. You get resilient parsing plus self-correction with no extra wiring.
The role of
getJsonSchema(). Added in 2.0 as a default method onStructuredOutputConverter,getJsonSchema()is the bridge that lets a converter participate inuseProviderStructuredOutput()andvalidateSchema(). Implement it to return your schema (typically by delegating to aBeanOutputConverter) and the new dials work; leave it at the default and both dials become no-ops for that converter.
For formats outside JSON's reach — YAML for config generators, CSV for data extraction — implement StructuredOutputConverter from scratch: write your own getFormat() prompt and your own convert(...) parser. Leave getJsonSchema() at its default, and both new dials sit out — the prompt-based path runs as it does for the built-ins.
| You need | Use |
|---|---|
| Default — works on every provider | .entity(Type.class) |
Generic types like List<T>, Map<K,V> |
.entity(new ParameterizedTypeReference<...>() {}) |
| Don't fail on malformed output | .entity(Type.class, spec -> spec.validateSchema()) |
| Stronger upstream guarantees from the provider | .entity(Type.class, spec -> spec.useProviderStructuredOutput()) |
| Both — request constraint + response retry | .entity(Type.class, spec -> spec.useProviderStructuredOutput().validateSchema()) |
| Token usage / metadata alongside the entity | .responseEntity(...) (same overloads) |
| Model wraps JSON in markdown fences, or non-JSON format | Implement StructuredOutputConverter<T> and pass it to .entity(...) |
| Streaming responses | Not supported — .entity(...) is .call()-only; .stream() returns text chunks, not typed objects |
Structured output in Spring AI 2.0 is the same .entity(...) call you already know, with two new switches: validateSchema() for response-side self-correction, useProviderStructuredOutput() for request-side enforcement. Each is independently useful; together they constrain the request and self-correct the response. Existing code keeps working unchanged; new code can opt in per call without rewiring the application.
StructuredOutputValidationAdvisor
VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all