Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreYou've no doubt read Jennifer Hickey's amazing blog posts introducing Cloud Foundry workers, their application in setting up Ruby Resque background jobs, and today's post introducing the Spring support.
vmc with gem update vmc.public static void main jobs. That is, a Cloud Foundry worker is basically a process, lower level than a web application, which maps naturally to many so-called back-office jobs.java incantation you'd like it to use, but it's far simpler to ship a shell script, and have Cloud Foundry run that shell script for you, instead. The command you provide should employ $JAVA_OPTS, which Cloud Foundry has already provided to ensure consistent memory usage and JVM settings. org.codehaus.mojo:appassembler-maven-plugin plugin will help you create a startup script and package your .jars for easy deployment, as well as specifying an entry point class. vmc push on a Java .jar project, Cloud Foundry will ask you whether the application is a standalone application. Confirm, and it'll walk you through the setup from there. So, let's look at a few common architectures and arrangements that are easier and more natural with Cloud Foundry workers. We'll look at these patterns in terms of the Spring framework and two surrounding projects, Spring Integration and Spring Batch, both of which thrive in, and outside of, web applications. As we'll see, both of these frameworks support decoupling and improved composability. We'll disconnect what happens from when it happens, and we'll disconnect what happens from where it happens, both in the name of freeing up capacity on the front end.
One common question I get is: How do I do job scheduling on Cloud Foundry? Cloud Foundry supports Spring applications, and Spring of course has always supported enterprise grade scheduling abstractions like Quartz and Spring 3.0's @Scheduled annotation. @Scheduled is really nice because it is super easy to add into an existing application. In the simplest case, you add @EnableScheduling to your Java configuration or <task:annotation-driven/> to your XML, and then use the @Scheduled annotation in your code. This is a very natural thing to do in an enterprise application - perhaps you have an analytics or reporting process that needs to run? Some long running batch process? I've put together an example that demonstrates using @Scheduled to run a Spring Batch Job. The Spring Batch job itself is a worker thread that works with a web service whose poor SLA make it unfit for realtime use. It's safer, and cleaner, to handle the work in Spring Batch, where its recovery and retry capabilities pick up the slack of any network outages, network latency, etc. I'll refer you to the code example for most of the details, we'll just look at the the entry point and then look at deploying the application to Cloud Foundry.
// set to every 10s for testing.
@Scheduled(fixedRate = 10 * 1000)
public void runNightlyStockPriceRecorder() throws Throwable {
JobParameters params = new JobParametersBuilder()
.addDate("date", new Date())
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(job, params);
BatchStatus batchStatus = jobExecution.getStatus();
while (batchStatus.isRunning()) {
logger.info("Still running...");
Thread.sleep(1000);
}
logger.info(String.format("Exit status: %s", jobExecution.getExitStatus().getExitCode()));
JobInstance jobInstance = jobExecution.getJobInstance();
logger.info(String.format("job instance Id: %d", jobInstance.getId()));
}
This method will be invoked at a frequency prescribed by the @Scheduled annotation: every 10 seconds, in this case. After the Job has been launched using the JobLauncher, the application blocks (this can be avoided, but in this case, it's OK since we're expecting it to). Depending on the data, and on the type of the batch process, it may block for a few minutes, ...or for a week! Spring Batch is a robust batch processing engine, and it was made to safely handle large data sets. A Batch process doesn't usually belong in the same pipeline as an HTTP request - it is determinant, and long running, so being able to use long running workers in Cloud Foundry is a real win here.
Let's deploy the application to Cloud Foundry. The example applications are Maven projects. To build them, go to the root of the code base, and run mvn clean install using the Maven build tool.
Deployment of the application is easy from here, assuming you've already set up the vmc command line tool and updated to the latest revision as Jennifer explained in the first post. The application comes with a manifest.yml at the root of the code. Cloud Foundry manifest.yml files fully describe everything the application expects to have provided for it by the Platform-as-a-Service, including which databases to use, how much RAM to appropriate, and more. Cloud Foundry reads this manifest and fulfills it when it deploys the application. So, by the sheer act of deploying this application, you will also be given the PostgreSQL database instance that this application needs to store the sample data, as well as the tables that Spring Batch maintains for its runtime state.
jlongmbp17:cf-workers-batch jlong$ vmc --path target/appassembler/ push
Pushing application 'batch'...
Creating Application: OK
Creating Service [stock_batch]: OK
Binding Service [stock_batch]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (55K): OK
Push Status: OK
Staging Application 'batch': OK
Starting Application 'batch': OK
jlongmbp17:cf-workers-batch jlong$ vmc apps
+---------------------+----+---------+----------------------------------+----------------+
| Application | # | Health | URLS | Services |
+---------------------+----+---------+----------------------------------+----------------+
| batch | 1 | RUNNING | | stock_batch |
...
The scheduled method runs every ten seconds, so wait ten seconds before following the next steps. Next, we'll login to the database to see what our little process has done. The Spring Batch job takes all the stock ticker symbols in the STOCKS table, and then looks up their current pricing information and inserts that snapshot data into the STOCKS_DATA table. The vmc tunnel command creates a tunnel directly into the database managed by the cloud. I use it to get into our PostgreSQL instance and run a query (SELECT * FROM STOCKS_DATA) on the STOCKS_DATA table.
jlongmbp17:cf-workers-batch jlong$ vmc tunnel stock_batch
Binding Service [stock_batch]: OK
Stopping Application 'caldecott': OK
Staging Application 'caldecott': OK
Starting Application 'caldecott': OK
Getting tunnel connection info: OK
Service connection info:
username : u59993cf15bc0461a1d2648f7eab27f2da15f
password : p1be9035f3c764817809ac81f3267
name : d5c5a80838d7bcd79dc7eefa6c1b04d22
Starting tunnel to stock_batch on port 10002.
1: none
2: psql
Which client would you like to start?: 2
Launching 'psql -h localhost -p 10002 -d d5c5aefa6c1b04d2280838d7bcd79dc7e -U u59993cf15bc04817809ac861a1d2648f -w'
psql (9.0.5, server 9.0.4)
Type "help" for help.
d5c5aefa6c1b04d2280838d7bcd79dc7e=> select * from stocks_data;
id | date_analysed | high_price | low_price | closing_price | symbol
----+---------------+------------+-----------+---------------+--------
1 | 2012-05-08 | 613 | 602.3 | 602.3 | GOOG
2 | 2012-05-08 | 30.78 | 30.25 | 30.25 | MSFT
3 | 2012-05-08 | 27.87 | 27.56 | 27.56 | ORCL
4 | 2012-05-08 | 32.41 | 32.06 | 32.06 | ADBE
5 | 2012-05-08 | 107.38 | 103 | 103 | VMW
...
It worked! Before we press on, now would be a great time to shut down the application. It will do you absolutely no good to look up those stocks every ten seconds, inserting new records each time! In a few hours that data set might very well become overwhelming. I suggest you change the frequency (see the comments for a cron expression that you can use in the @Scheduled annotation that runs every weekday at 11PM) and then do a vmc --path target/appassembler/ update, or just leave it stopped.
jlongmbp17:cf-workers-batch jlong$ vmc stop batch
So, batch processing and job scheduling are two very common use cases that Spring and Spring Batch and Cloud Foundry handle with aplomb. Another (different, but equally common) use case is architecting for ease of scalability. After all, what does it really mean to scale when your next big application is Oprah'd or /.'d? Let's look at that, now...
It's slightly counter intuitive, but a system with lots of small, singly focused components is easier to scale out than one monolithic application because individual workloads can be scaled and tuned independent of other parts of the application. Suppose you have a resource starved front-end web application that shouldn't be straddled with slower, perhaps I/O burdened, functionality. An easy way to decouple the main thread from the slower back office process is to introduce a message queue, like RabbitMQ. In messaging, we talk about the aggressive consumer pattern, where work is enqueued and workers dequeue this work as fast as they're able to complete it. If the workers aren't keeping pace with the availability of new work, it's easy enough to add new workers to pick up the slack: simply vmc instances my-backend +10! Each individual request may still take a fixed amount of time, but the over all throughput of the system is increased.
For our next example - which has little to do with our last example except that it's another way to use standalone worker processes on Cloud Foundry - we'll look at building a messaging-oriented service. We'll use RabbitMQ, a world-class message queue that's available on Cloud Foundry as a service. Messaging systems are just well known mailboxes. They accept messages and they distribute messages. By reducing your API to a messaging broker like RabbitMQ, which is itself based on a protocol - AMQP - you give your application as friendly as interface as possible. Messaging systems are also asynchronous by their very nature, so they don't impose notions of request/reply exchanges, though that is supported, too. If you want to take advantage of RabbitMQ to integrate with other workers, you can still expose a facade, or gateway to consumers of your service so that they don't need to know how the service is implemented, if you don't want them to. We'll use Spring Integration, which supports the Enterprise Integration patterns, to build a messaging gateway from a Java interface type.
```java
public interface StockSymbolLookupClient { StockSymbolLookup lookupSymbol (String symbol) throws Throwable; }
<P>With Spring Integration's help, calls to this method will result in a message being sent to RabbitMQ where, on the other side, our service will dequeue the message, process it, and then, eventually send a reply back to RabbitMQ, which the caller of this method will receive as the reply value. </P> <P> To configure the client, I used a little bit of Spring Integration to setup the gateway, which then forwards the request to the outbound AMQP gateway adapter.</P>
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans ...>
...
<gateway
service-interface="org.cloudfoundry.workers.stocks.integration.client.StockClientGateway"
default-request-channel="outboundSymbolsRequests"
default-reply-channel="outboundSymbolsReplies"
/>
<amqp:outbound-gateway
request-channel="outboundSymbolsRequests"
reply-channel="outboundSymbolsReplies"
routing-key="tickers"
amqp-template="amqpTemplate"
/>
</beans:beans>
I've omitted the details of the RabbitMQ-specific connection machinery (which, of course, is all being done using the cloudfoundry-runtime API) - please refer to the client example. This snippet shows the important bit: Spring will synthesize an implementation at runtime based on the StockClientGateway interface which we can inject and then use from our client code to invoke the service.
On the service side, we need some code to dequeue messages from RabbitMQ, and then forward them to the workhorse, and then ferry the results back through RabbitMQ as the replies. The service side, of course, we can scale out independently of the client side. You might have one client per web application, but ten service implementations running, taking up the slack and absorbing the extra demand. Here's what our service implementation looks like, again omitting RabbitMQ-specific connection beans (consult the example):
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans ...>
...
<amqp:inbound-gateway request-channel="inboundSymbolsRequests"
queue-names="tickers"
message-converter="mc"
connection-factory="connectionFactory"/>
<service-activator ref="client" input-channel="inboundSymbolsRequests" requires-reply="true"/>
</beans:beans>
This approach is very powerful. In my example, I'm simply deferring the admittedly trivial cost of a RESTful web service call. But you might imagine doing more lengthy things -image processing, batch jobs, large analytics, etc., in this manner.
Deployment of this example is slightly more complicated, because there are two pieces. The gateway implementation is a simple bean that Spring Integration makes available as a sort of client-side proxy for the messaging system. We could use the gateway from another background job, or a web application, or anything else. In our case, our client - a Spring MVC application - uses the gateway to invoke the service. The service is what provides the interesting functionality, receiving requests from the provisioned RabbitMQ instance and invoking the stock ticker lookup bean and then returning the results back through RabbitMQ to the requester. We need to deploy the service first. As before, you need to build the whole code base by running mvn clean install at the root, if you haven't already. Then, from the root of the cf-workers-integration-service folder, run the following commands:
jlongmbp17:cf-workers-integration-service jlong$ vmc --path target/appassembler/ push
Pushing application 'integration-service'...
Creating Application: OK
Creating Service [stock_rabbitmq]: OK
Binding Service [stock_rabbitmq]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (44K): OK
Push Status: OK
Staging Application 'integration-service': OK
Starting Application 'integration-service': OK
With the service in place, let's test it out by calling it once from our web client. Return the the cf-workers-integration-webclient directory. Then, run the same command as with the service.
jlongmbp17:cf-workers-integration-webclient jlong$ vmc --path target/cf-workers-integration-webclient-1.0-SNAPSHOT push
Pushing application 'integration-webclient'...
Creating Application: OK
Binding Service [stock_rabbitmq]: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (3K): OK
Push Status: OK
Staging Application 'integration-webclient': OK
Starting Application 'integration-webclient': OK
Once the application's been deployed (you can confirm that both are running happily by running vmc apps). Now, let's open up the client and give our service a try: Open up the URL of the webclient application. In my case, the URL is integration-webclient.cloudfoundry.com. It should give you a pedestrian looking form. Enter a stock symbol (I test with VMW...) and then hit Enter. You should see data manifest on the page.
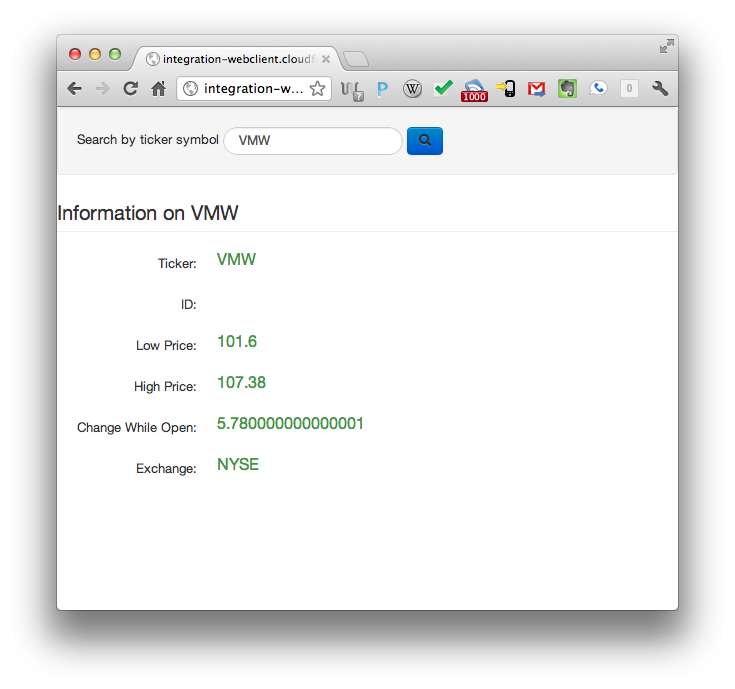
integration-service, you should see console output reflecting the very same information as you saw in the client. If so, congratulations!
At this point, you've got a lot of power at your fingertips. Cloud Foundry workers are ideal places to handle the work that doesn't naturally fit inside of an HTTP request processing pipeline. In my experience, this encompasses a good many things: batch processing, integration and messaging code, analytics, reporting, big data and compensatory transactions, and indeed systems exposed over other protocols besides HTTP.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all