Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn more#Introduction#
A common question when developing streaming applications is, “How many events per second can you process?”. The primary purpose of this blog post is to answer that question without falling into the classic benchmarking conundrum of benchmarking versus "benchmarketing". The common approach with 'native' benchmarking applications provide by messaging middleware vendors is to focus on raw data transport speed, without serialization or deserialization of the message data and without any data processing. In Part 1 of the series, we will follow this approach.
Our tests used direct binding (in-memory) and Apache KafkaⓇ transports in Spring XD in the scenario where the producer and consumer are running simultaneously. This test scenario simulates real-time stream processing versus having a producer only or consumer only suite of tests. The test scenarios use a single container for direct binding and multiple containers when using the Kafka transport. Each test varied the event (message) size and the results are shown in total messages and MB’s consumed per second. In the case of the Kafka transport tests, we used Kafka’s provided performance tools to provide to us a baseline benchmark for the infrastructure that was provisioned. ##What is Spring XD?## Spring XD is a unified, distributed, and extensible system for data ingestion, real time analytics, batch processing, and data export. The project's goal is to simplify the development of big data or Enterprise streaming/batch applications. More information on XD can be found here. ##Architecture## All tests were run using RackSpace OnMetal servers to guarantee network speed for all services and provide appropriate disk write speed for our Kafka based tests. See below for additional details on this choice. The specs for the servers used are as follows: ###Server Instance Types###
###Network:###
All of the tests ran Spring XD on a 10 Gigabit Network with an average speed of 1117 MB/s or 8.936 Gbps. We used iperf to determine network performance using the following command for the client iperf -c and iperf -s for the server.
###Disk:###
All tests that required high performance disk writes were implemented on the OnMetal IO data disks. The average disk write speed for these devices was approx. ~934 MB/s. The command used to verify the disk write speed was dd if=/dev/zero of=/data1/largefile bs=1M count=10000 conv=fdatasync. The fdatasync on the dd command requires a complete “sync” right before it exits, thus verifying data is written completely on the disk versus the cache.
##Tools##
The two primary tools used to test transports were the load-generator source and throughput sink modules that can be found on github in the spring-xd-modules project. The load-generator source module generates data in-memory and can be configured to send a specific number of messages of a certain size. The throughput module is a sink that counts received messages and periodically reports the witnessed throughput to the log.
#Transport Tests#
##Direct Binding Transport##
To eliminate network latency, it is sometimes desirable to allow co-located, contiguous modules to communicate directly, rather than by using the configured remote transport. Spring XD creates direct bindings by default only in cases where every "pair" of producers and consumers (modules bound on either side of a pipe) are guaranteed to be co-located in the same JVM. The purpose of this benchmark is to show message throughput of a single XD-Container using direct binding. In this scenario we sent and consumed 500 million messages in a single container. The following stream definition was used to capture the results results for the 1000 byte message test:
stream create directBindingTest --definition "load-generator --messageCount=500000000 --messageSize=1000 | throughput"
stream deploy directBindingTest --properties module.*.count=0
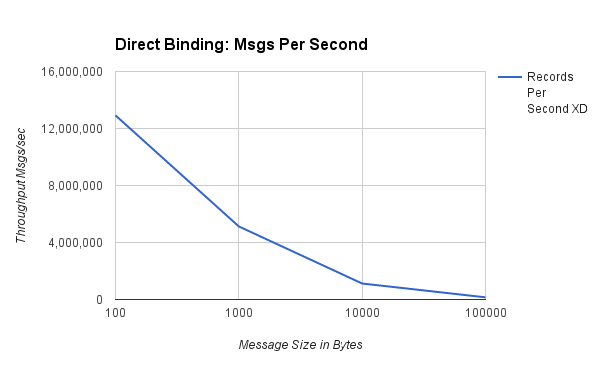
The diagrams below show the Messages/MB per second with message sizes of 100, 1000, 10000 and 100000 bytes:
###Messages Per Second###
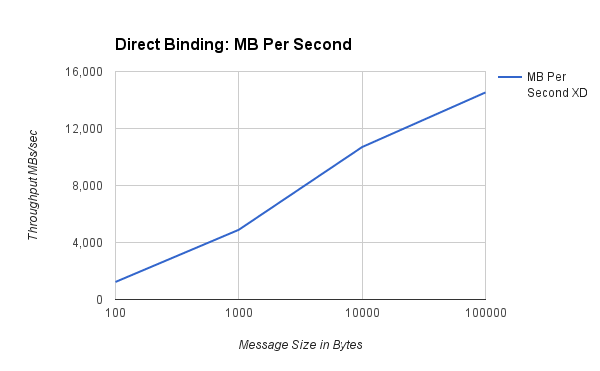
 ###Megabytes Per Second###
###Megabytes Per Second###
| Message Size | Messages Per Second XD | MB Per Second XD |
|---|---|---|
| 100 | 12,919,560 | 1,232 |
| 1,000 | 5,126,920 | 4,893 |
| 10,000 | 1,121,921 | 10,699 |
| 100,000 | 152,364 | 14,530 |
The graphs show that rates decrease as message size increases, but overall data throughput increases. For typical size payloads in the range of 100 to 1,000 bytes we are able to push 5-12 million events second using a single thread. The cost of doing small operations at this scale, such as accessing data in a hashtable, means that any data processing will bring the rates down significantly.
##Kafka Transport## ###Testing Topology###
For testing with Kafka we created the following topology:
A three broker Kafka cluster was set up on the three OnMetal I/O instances. Each Kafka instance has two SSDs with no RAID. One Zookeeper instance was shared between the Kafka brokers and XD and was deployed on an Compute v1 Rackspace instance. The XD Cluster was deployed on 2 OnMetal Compute instances. RS(RackSpace) Instance One hosted, one XD-Admin, one HSQLDB and one xd-container. RS(RackSpace) Instance Two hosted one xd-container.
####Instance Type Selection#### Instance types were selected based on processor speed, disk write speed, and a network that could handle the volume of data. Originally the tests were slated for EC2 but we found that the ephemeral disk write speeds were too slow (approx. ~75 MB/s) for Kafka to perform at its peak. We plan to re-run tests on the newly released D2 instance types. We decided to use Rackspace OnMetal I/O to take advantage of the high performance SSD’s (approx. ~934 MB/s). ####Tests#### The purpose of this benchmark is to show message throughput of a source (publisher) and sink (consumer) running on two different XD containers on different machines using Kafka as a transport. The goal for this benchmark was to capture the native statistics from Kafka’s own testing tools and compare them to Spring XD's results for the same set of tests. This comparison is important in that XD does not use the standard Kafka Consumer API but rather the Spring Integration Kafka Adapter that adds additional capabilities such as control over what offset to consume from and which partitions to consume from a topic. In each case a topic would be created with six partitions with a replication factor of three. The producer would be placed on RS Instance One and the consumer would be on RS Instance Two. All payloads for these tests operate only with byte array data. Thus for these tests Spring XD has the Kafka transport mode set to raw. Raw mode indicates Spring XD will not embed headers and will leave the handling of serialization to the user.
Using Kafka’s performance tools in the same manner as demonstrated in Benchmarking Apache Kafka: 2 Million Writes Per Second we wished to identify the base speed of the Kafka cluster. In the example below the following producer/consumer commands were used for these results for the 1000 byte message test:
Producer:
./bin/kafka-topics.sh --zookeeper
./bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance $1 300000000 1000 -1 acks=1 bootstrap.servers=
Consumer:
./bin/kafka-run-class.sh ./bin/kafka-consumer-perf-test.sh --zookeeper
Spring XD 1.2 uses the new Spring Integration Kafka adapter, which offers a richer set of features than that of the standard Kafka client library. The configuration for XD was out of the box except we set the following configurations in the servers.yml to match those used in the native tests:
To read more about these configurations please review our documentation located here.
The following stream was used for these results for the 1000 byte message test:
stream create myTest --definition "load-generator --messageCount=300000000 --messageSize=1000 | throughput"
stream deploy myTest
####Throughput####
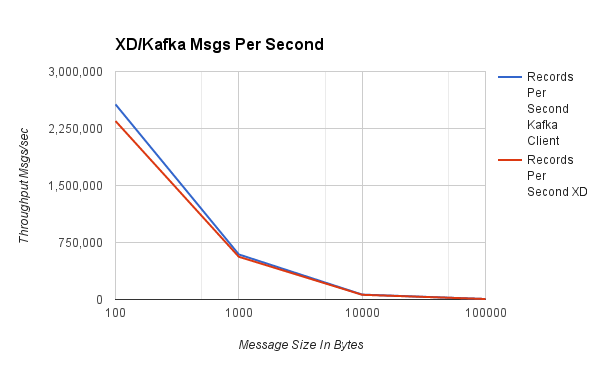
#####Messages Per Second#####
| Message Size | Messages Per Second Kafka Client | Messages Per Second XD |
|---|---|---|
| 100 | 2,567,657 | 2,348,289 |
| 1,000 | 592,881 | 562,113 |
| 10,000 | 64,806 | 61,985 |
| 100,000 | 6,505 | 6,341 |
| #####Messages Per Second##### |
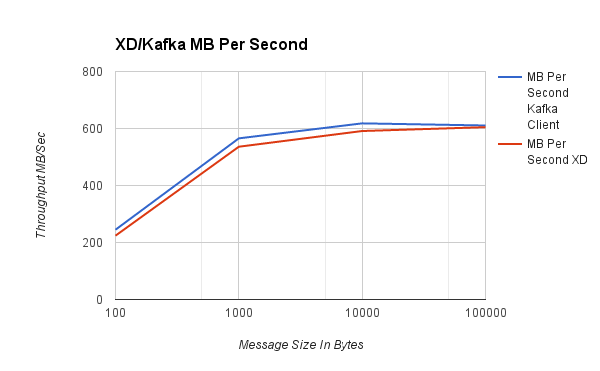
| Message Size | Mb Per Second Kafka Client | Mb Per Second XD |
|---|---|---|
| 100 | 245 | 224 |
| 1,000 | 565 | 536 |
| 10,000 | 618 | 591 |
| 100,000 | 611 | 605 |
As in the direct binding benchmark, the graphs show that as message size increases, rates decrease but overall data throughput increases. For typical size payloads in the range of 100 to 1,000 bytes we are able to push 600K to ~2 million events per second using a single thread. It is important to note that Spring XD’s benchmarks - based on a more feature rich consumer library - were within 8% of the Kafka native client API’s benchmarks. Also note that between 1000 and 10,000 byte message sizes a single producer can reach about half of the 10Gb network capacity. In future tests we will show benchmarks of multiple producers and consumers to show how XD scales up and how other tuning parameters such as batch size impact performance.
#Conclusion#
The benchmarks above show that Spring XD can meet high performance streaming use-case requirements. They also show that Spring XD which uses the Spring Integration Kafka (SIK) client library introduces very little overhead as compared to the native Kafka high level consumer library, while providing added functionality such as control over offsets and partitions. Thus you can take advantage of using the Spring XD programming model as well as functionality in the SIK consumer API with minimal impact to performance.
#Next steps#
While there are some use-cases that are mostly data passthrough-centric, most use cases will involve some processing of the payload. Also, we only used a single processing thread. In future blog posts we will show how XD scales up with more container instances, how message rates are impacted while deserializing/serializing objects using popular libraries and how multiple threads and reactive programming can also help to increase rates per JVM process. Stay tuned!
Editor’s Note: ©2015 Pivotal Software, Inc. All rights reserved. Apache and Apache Kafka, are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all