Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreOn behalf of the Spring Batch team, I am pleased to announce the release of Spring Batch 4.2.0.RC1. We have been working on some performance improvements in the core framework, and this post highlights the major changes.
We have made some performance improvements, including:
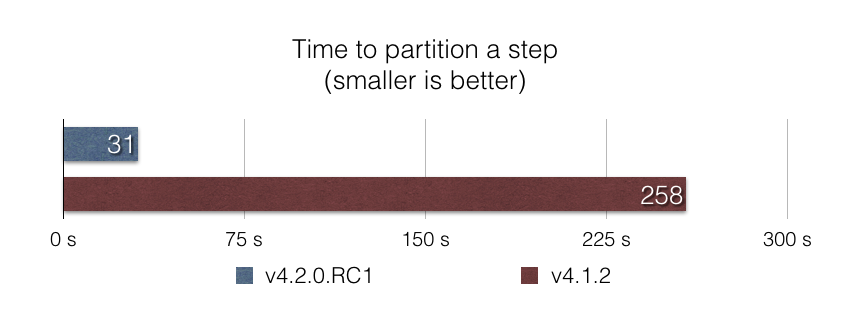
JpaItemWriterBeanWrapperFieldSetMapperStarting a partitioned step is an area where the framework wasn't well optimized. In this version, we have dug deep into the partitioning process to figure out the root cause of this performance issue. One of the main steps of the partitioning process is to find the last step execution (to see if the current execution is a restart). We found that looking up the last step execution involved loading all step executions from all job executions for a given job instance in-memory, which is obviously inefficient!
We replaced this code with a SQL query that does the lookup at the database level, to return only the last step execution. The results are outstanding: Partitioning a step execution into 5000 partitions is almost 10x faster with this approach, according to our benchmark partitioned-step-benchmark:
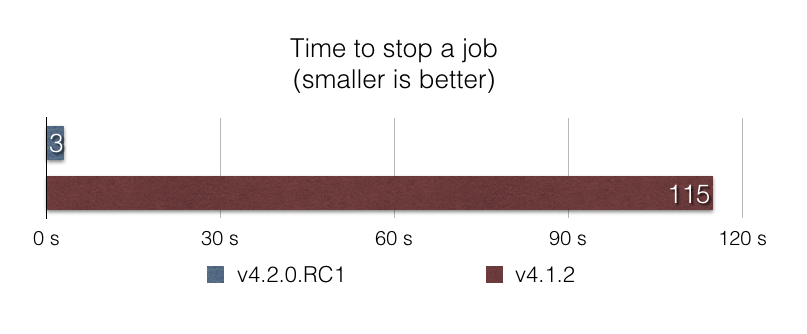
Things can go wrong when running a job.. and gracefully stopping a destructive job should be fast and efficient in order to avoid data corruption. Up until v4.1, stopping a job using the CommandLineJobRunner suffered from a poor performance, due to loading all job executions in memory in order to find whether a job execution is currently running. With this approach, stopping a job can take minutes with a production database that has thousands of job executions in it!
In this release, we optimized the stop process by using a SQL query that does the filtering at the database level. Again, the results are impressive: With 100.000 job executions of a given job in the database, stopping the job is almost 40x faster with this approach, according to our benchmark stop-benchmark:
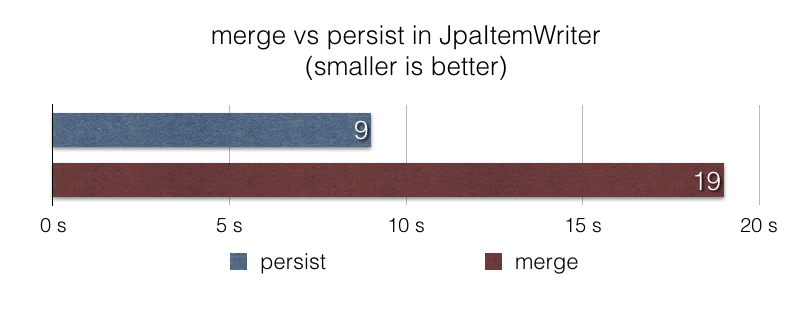
JpaItemWriterThe JpaItemWriter uses the javax.persistence.EntityManager#merge function to write items in a JPA persistence context. This makes sense when the persistent state of items is unknown or known to be an update. However, in many file ingestion jobs where data is known to be new and should be considered as inserts, using javax.persistence.EntityManager#merge is not efficient.
In this release, we introduced a new option in the JpaItemWriter to use persist rather than merge in such scenarios. With this new option, a file ingestion job that uses the JpaItemWriter to insert 1 million items in a database is 2x faster according to our benchmark jpa-writer-benchmark:
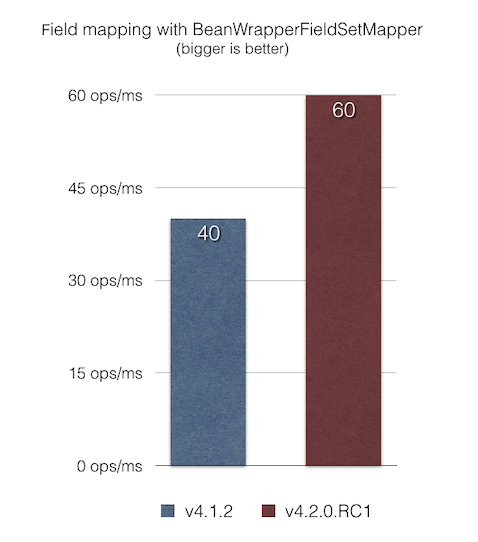
BeanWrapperFieldSetMapperThe BeanWrapperFieldSetMapper provides a nice feature that lets us use fuzzy matching of field names of a given JavaBean (Camel case, nested properties, and so on). However, when field names match column names, exact matching can be enabled by setting the distanceLimit parameter to 0.
In this release, we fixed a performance issue in the BeanWrapperFieldSetMapper that was introspecting field names by using reflection on each iteration, even when exact matching was requested (by setting distanceLimit=0). The result is that item mapping is now 1.5x faster than the previous version according to our JMH benchmark bean-mapping-benchmark:
Please note that these numbers may vary in your case. We encourage you to try out Spring Batch 4.2.0.RC1 (which can be consumed with Spring Boot 2.2.0.M6) and share your feedback. Please refer to the change log of version 4.2.0.RC1 and 4.2.0.M3 for the complete list of changes.
Feel free to ping @michaelminella or @b_e_n_a_s on Twitter or to ask your question on StackOverflow or Gitter. If you find any issue, please open a ticket on Jira.
We plan to stabilize this new release candidate for the upcoming Spring Batch 4.2.0.RELEASE planned for September 30th, 2019. Stay tuned!
All benchmarks have been performed on a Macbook Pro 16Go RAM, 2.9 GHz Intel Core i7 CPU, MacOS Mojave 10.14.5, Oracle JDK 1.8.0_201. You can find the source code of all benchmarks in the following links:
Spring Batch Home | Source on GitHub | Reference Documentation

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all