Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThis is the first in a series of blog posts in which we will look at how stream processing applications are written using Spring Cloud Stream and Kafka Streams.
The Spring Cloud Stream Horsham release (3.0.0) introduces several changes to the way applications can leverage Apache Kafka using the binders for Kafka and Kafka Streams. One of the major enhancements that this release brings to the table is first class support for writing apps by using a fully functional programming paradigm. This blog post gives an introduction to how this functional programming model can be used to develop stream processing applications with Spring Cloud Stream and Kafka Streams. In the subsequent blog posts in this series, we will look into more details.
This is often a confusing question: Which binder should I use if I want to write applications based on Apache Kafka. Spring Cloud Stream provides two separate binders for Kafka - spring-cloud-stream-binder-kafka and spring-cloud-stream-binder-kafka-streams. As their names indicate, the first one is the one that you want to use if you want to write standard event-driven applications in which you want to use normal Kafka producers and consumers. On the other hand, if you want to develop stream processing applications with the Kafka Streams library, use the second binder. Once again, in this blog post, we will focus on the second binder for Kafka Streams.
One general note about this blog series. This is mainly looking at the touchpoints between Spring Cloud Stream and Kafka Streams and does not go into the details of Kafka Streams itself. In order to write non-trivial stream processing applications that use Kafka Streams, a deeper understanding of Kafka Streams library is highly recommended. This series only stays at the periphery on the actual Kafka Streams library and mainly focuses on how you can interact with it from a Spring Cloud Stream vantage point.
At the heart of it, all Spring Cloud Stream applications are Spring Boot applications. In order to bootstrap a new project, go to the Spring Initializr and then create a new project. Select “Cloud Stream” and “Spring for Apache Kafka Streams” as dependencies. This will generate a project with all the components that you need to start developing the application. Here is a screenshot from the initializr with the basic dependencies selected.
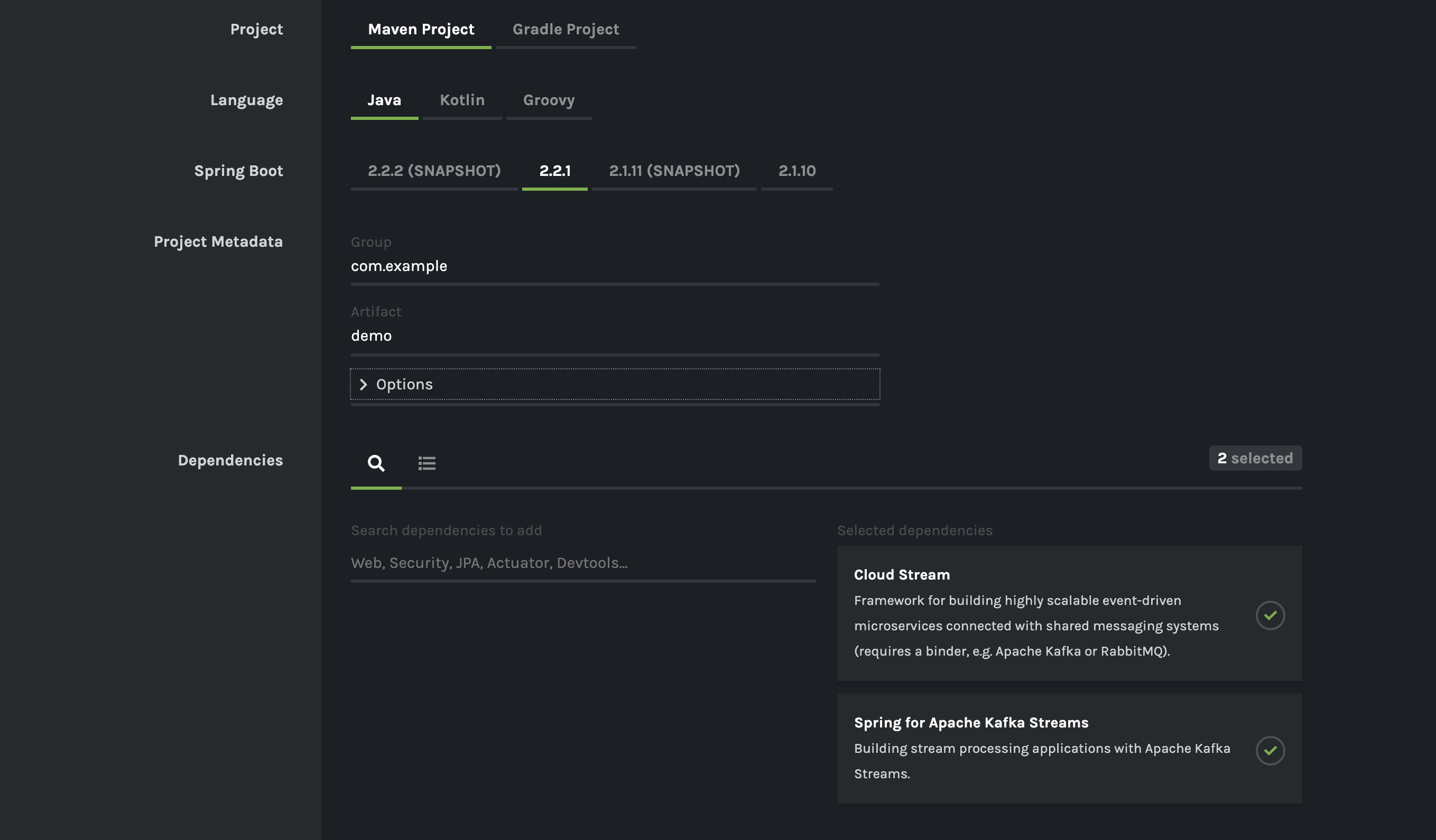
Here is a very basic, but functional, Kafka Streams application that is written by using Spring Cloud Stream’s functional programming support:
@SpringBootApplication
public class SimpleConsumerApplication {
@Bean
public java.util.function.Consumer<KStream<String, String>> process() {
return input ->
input.foreach((key, value) -> {
System.out.println("Key: " + key + " Value: " + value);
});
}
}
As you can see, this is a very trivial application that just prints to standard output but is, nonetheless, a full-blown Kafka Streams application. At the outer layer, we indicate that this is a boot application by using the @SpringBootApplication annotation. Then we provide a java.util.function.Consumer bean where we encapsulate our application’s logic through a lambda expression. The consumer takes a KStream as its input with both the key and the value represented as String types.
That’s it. You can run this application against a Kafka broker and see it in action. Behind the scenes, the Kafka Streams binder for Spring Cloud Stream will convert this into a proper Kafka Streams application with a StreamsBuilder, Kafka Streams topology, and so on. One of the prime tenets for Spring Cloud Stream is hiding the complexity and boilerplate away from the user so that the application developer can focus on the business issue at hand. Binder will take care of creating the Kafka Streams topology, connecting to a Kafka Cluster, binding to a topic and consuming data from that Kafka topic, which is bound as KStream in this case. Usually, it is the responsibility of the application developer to do all these things if they are not using a framework such as Spring Cloud Stream.
If you know Kafka Streams internals, you might be wondering if what is presented above will work or not. We haven’t provided a number of basic things that Kafka Streams requires (such as the cluster information, application id, the topic to consume, Serdes to use, and so on). The short answer is that this is going to work without providing a single configuration property. This is because the binder will use a lot of reasonable defaults and make opinions as to what topics to consume from and so on. Nevertheless, for production use, we recommend providing all the applicable properties if the defaults used by the binder do not make sense.
Let’s look at some of these basic things that Kafka Streams requires and how the binder provides default values for them.
By default, the binder will try to connect to a cluster that is running on localhost:9092. If that is not the case, you can override that by using configuration properties available through Spring Cloud Stream. See the Spring Cloud Stream Reference Guide.
In a Kafka Streams application, application.id is a mandatory field. Without it, you cannot start a Kafka Streams application. By default, the binder will generate an application ID and assign it to the processor. It uses the function bean name as a prefix. For e.g, if you have a consumer as above, the binder will generate the application ID as process-applicationId. You can override this using the strategies outlined here. See the Spring Cloud Stream Reference Guide.
For the above processor, you can provide the topic to consumes, as follows
spring.cloud.stream.bindings.process-in-0.destination: my-input-topic
In this case, we are saying that, for the function bean (process) and its first input (in-0), it shall be bound to a Kafka topic named my-input-topic. If you don’t provide an explicit destination like this, the binder assumes that you are using a topic that is the same as the binding name (process-in-0, in this case).
Kafka Streams uses a special class called Serde to deal with data marshaling. It is essentially a wrapper around a deserializer on the inbound and a serializer on the outbound. Normally, you have to tell Kafka Streams what Serde to use for each consumer. Binder, however, infers this information by using the parametric types provided as part of Kafka Streams. For example, in the case of KStream<String, String>, the binder assumes that it needs to use String deserializers. As always, you can override these in a number of ways.
Yes, you can. Spring Cloud Stream binder for Kafka Streams will make it easy to provide multiple processors expressed as java.util.function.Function or java.util.function.Consumer beans within a single application. The binder will isolate each such processor to its own application ID and StreamsBuilder. It ensures that there won’t be any interference with each other. From a Kafka Streams angle, they are multiple processors with their own dedicated topology. Although this is a legitimate use-case when it comes to things like testing and trying out something really quick, having several processors within a single application can have the potential of making it a monolith that is harder to maintain.
In this blog post, we saw a quick introduction to how Spring Cloud Stream’s functional programming support can be used to write stream processing applications that use Kafka Streams. We saw that the binder takes care of a lot of infrastructure and configuration details, which lets you focus on the business logic at hand. In the next blog post, we are going to further explore this programming model to see how more non-trivial stream processing applications are developed with Spring Cloud Stream and Kafka Streams.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all