Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreOne of Spring Data JPA’s handy features is letting you plugin in custom JPA queries through its @Query annotation.
This allows some flexiblity because you are still able to offer sort parameters to the consumers of your app. Check out the example below:
interface SampleRepository extends CrudRepository<Employee, Long> {
@Query("select e from Employee e where e.firstName = :firstName")
List<Employee> findCustomEmployees(String firstName, Sort sort);
}
Spring Data JPA will turn this custom query into a JPA query when provided not just with a criteria (firstName) but also a custom sort via findCustomEmployees("Alice", Sort.by("lastName")), into the following fully fledged query:
select e
from Employee e
where e.firstName = :firstName
order by e.lastName
On top of that, Spring Data JPA supports paging, which requires the ability to count result sets.
In the past, with more and more complex queries, our ability to "do the right thing" and apply "order by" clauses that properly point to the primary SELECT clause's alias value has been challenging to say the least.
It is also tricky to wrap the projection with a proper count() function. Imagine doing this when there subqueries, case statements, and other deep queries!
We are excited to announce the release of both HQL and JPQL parsers, which will make it easier for you to customize queries in your Spring Data JPA applications.
Using both the JPA and Hibernate specifications, we have developed ANTLR-based query parsing engines and use them to more properly apply the customizations needed to serve you.
Not only can we spot the "right place" to put that count() function and also harvest the primary FROM expression's alias, it becomes possible to detect semantic situations.
With a query parser, it is much easier spot valid vs. invalid queries. Sometimes, we spend MORE time working out whether a query is even correct before figuring out how to handle it properly.
Good news...it's automatically applied.
When using the @Query annotation, there is a key parameter: isNative. This boolean flag lets you signal whether you are writing native SQL (isNative=true) or a JPA query (isNative=false by default).
If you have a JPA query (isNative=false) and Hibernate is on the classpath, it will use our new HQL parser. If Hibernate is NOT on the classpath, it will fallback to the somewhat limited JPQL parser. (Limited by specification, not our implementation.)
And thus, all you must do is either pick up our latest snapshot release of the Spring Data release train (Spring Data 3.1 snapshots) or pick up the next milestone release of Spring Boot.
There are more features to add. For example, it's possible to have more complex aliasing, such as:
select AVG(e.timeToCloseTickets) as avg
from Employee e
This type of query when you apply a Sort.by("avg") should NOT yield an order by e.avg, but instead simply order by avg. There are other scenarios we are looking into adding support. But with these query parsers in place, it becomes much easier to support these situations.
We also have a backlog of tickets related to query parsing that we can now work through.
As a bonus, if you are wanting to pre-check our own custom queries, it's possible with today's tooling to get a peek.
If you use IntelliJ IDEA, there is an ANTLR plugin (https://plugins.jetbrains.com/plugin/7358-antlr-v4) that when installed, lets you run any ANTLR grammar file and test against it.
src/main/antlr4/org/springframework/data/jpa/repository/query/Hql.g4.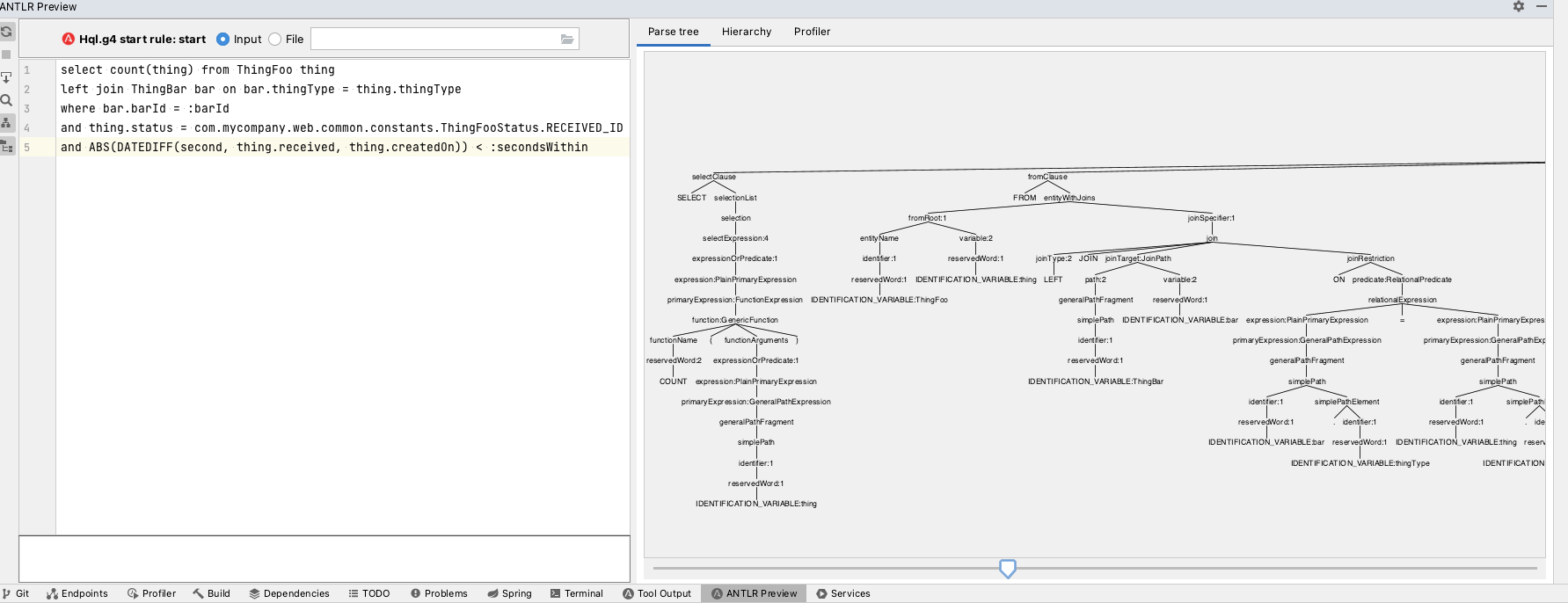
(We recently asked for people to send in their craziest JPA queries and this is one of them. At a glance, the query is valid and you can even zoom in to see more of it.)
Cheers, --Greg Turnquist

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all