Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThis is a guest blog post by Gerrit Meier from Neo4j who maintain(s) the Spring Data Neo4j module.
A few weeks ago version 1.2.0 of Spring (for) GraphQL was released with a bunch of new features. This also includes even better integration with Spring Data modules. Motivated by those changes, more support in Spring Data Neo4j has been added, to give the best experience when using it in combination with Spring GraphQL. This post will guide you on creating a Spring application with data stored in Neo4j and GraphQL support. If you are only partial interested in the domain, you can happily skip the next section ;)
For this example I have chosen to reach into the Fediverse. More concrete, to put some Servers and User into the focus. Why the domain was picked up for this, is now for the reader to discover in the following paragraphs.
The data itself is aligned to the properties that could be fetched from the Mastodon API. To keep the data set simple the data was created by hand instead of fetching everything. This results into an easier to inspect data set. The Cypher import statements looks like this:
Cypher import
CREATE (s1:Server {
uri:'mastodon.social', title:'Mastodon', registrations:true,
short_description:'The original server operated by the Mastodon gGmbH non-profit'})
CREATE (meistermeier:Account {id:'106403780371229004', username:'meistermeier', display_name:'Gerrit Meier'})
CREATE (rotnroll666:Account {id:'109258442039743198', username:'rotnroll666', display_name:'Michael Simons'})
CREATE
(meistermeier)-[:REGISTERED_ON]->(s1),
(rotnroll666)-[:REGISTERED_ON]->(s1)
CREATE (s2:Server {
uri:'chaos.social', title:'chaos.social', registrations:false,
short_description:'chaos.social – a Fediverse instance for & by the Chaos community'})
CREATE (odrotbohm:Account {id:'108194553063501090', username:'odrotbohm', display_name:'Oliver Drotbohm'})
CREATE
(odrotbohm)-[:REGISTERED_ON]->(s2)
CREATE
(odrotbohm)-[:FOLLOWS]->(rotnroll666),
(odrotbohm)-[:FOLLOWS]->(meistermeier),
(meistermeier)-[:FOLLOWS]->(rotnroll666),
(meistermeier)-[:FOLLOWS]->(odrotbohm),
(rotnroll666)-[:FOLLOWS]->(meistermeier),
(rotnroll666)-[:FOLLOWS]->(odrotbohm)
CREATE
(s1)-[:CONNECTED_TO]->(s2)
After running the statement, the graph forms this shape.
Graph view of data set

Noticeable information is that even all users follow each others, the Mastodon servers are only connected in one direction. Users on server chaos.social cannot search or explore timelines on mastodon.social.
Disclaimer: The federation of the servers is made up with a non-bidirectional relationship for this example.
To follow along with the example shown, you should use the following minimum versions:
Best is to head over to https://start.spring.io and create a new project with Spring Data Neo4j and Spring GraphQL dependency. If you are a little bit lazy, you could also download the empty project from this link.
To follow along the example 100%, you would need to have Docker installed on your system. If you don't have this option or don't want to use Docker, you could use either Neo4j Desktop or the plain Neo4j Server artifact for local deployment, or as hosted options Neo4j Aura or an empty Neo4j Sandbox. There will be a note later how to connect to a manual started instance. The use of the enterprise edition is not necessary and everything works with the community edition.
In this example the heavy lifting of configuration will be done by the Spring Boot autoconfiguration. There is no need to set up the beans manually. To find out more about what happens behind the scenes, please have a look at the Spring for GraphQL documentation. Later, specific sections of the documentation will be referenced.
First thing to do is to model the domain classes.
As already seen in the import, there are only Servers and Accounts.
Account domain class
@Node
public class Account {
@Id String id;
String username;
@Property("display_name") String displayName;
@Relationship("REGISTERED_ON") Server server;
@Relationship("FOLLOWS") List<Account> following;
// constructor, etc.
}
it is valid to assume, that the id is (server) unique.
Server, @Property is used to map the database field display_name to camel-case displayName in the Java entity.Server domain class
@Node
public class Server {
@Id String uri;
String title;
@Property("registrations") Boolean registrationsAllowed;
@Property("short_description") String shortDescription;
@Relationship("CONNECTED_TO") List<Server> connectedServers;
// constructor, etc.
}
With these entity classes, a AccountRepository can be created.
Account repository
@GraphQlRepository
public interface AccountRepository extends Neo4jRepository<Account, String> { }
Details why this annotation is used will follow later. Here for completeness of the interface.
To connect to the Neo4j instance, the connection parameters needs to be added to the application.properties file.
spring.neo4j.uri=neo4j://localhost:7687
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=verysecret
If not happened yet, the database can be started and the Cypher statement from above run to set up the data. In a later part of this article, Neo4j-Migrations will get used to be sure that the database is always in the desired state.
Before looking into the integration features of Spring Data and Spring for GraphQL,
the application will get set up with a @Controller stereotype annotated class.
The controller will get registered by Spring for GraphQL as a DataFetcher for the query accounts.
@Controller
class AccountController {
private final AccountRepository repository;
AccountController(AccountRepository repository) {
this.repository = repository;
}
@QueryMapping
List<Account> accounts() {
return repository.findAll();
}
}
Defining a GraphQL schema, that defines not only our entities but also the query with the same name as the method in the controller (accounts).
type Query {
accounts: [Account]!
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
Also, to browse the GraphQL data in an easy way, GraphiQL should be enabled in the application.properties. This is a helpful tool during development time. Usually this should be disabled for production deployment.
spring.graphql.graphiql.enabled=true
If everything is set up as described above, the application can be started with ./mvnw spring-boot:run.
Browsing to http://localhost:8080/graphiql?path=/graphql will present the GraphiQL explorer.
Querying in GraphiQL
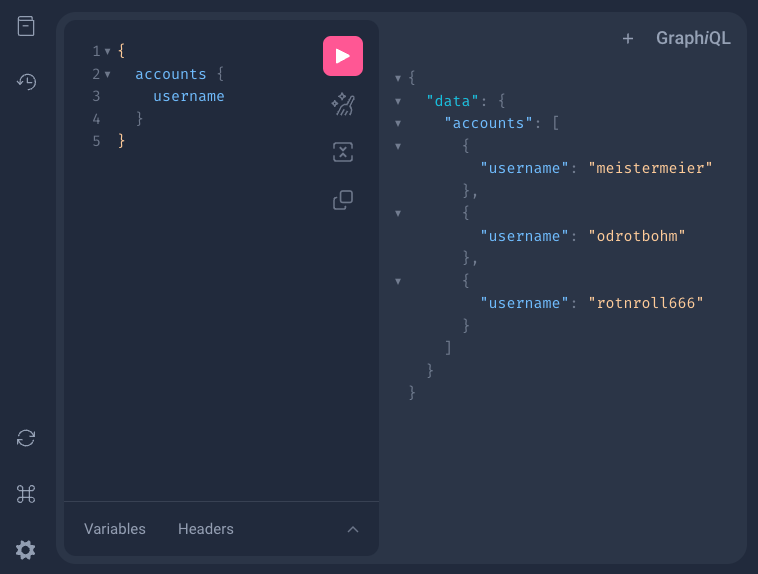
To verify that the accounts method is working, a GraphQL request is sent to the application.
First GraphQL request
{
accounts {
username
}
}
and the expected answer gets returned from the server.
GraphQL response
{
"data": {
"accounts": [
{
"username": "meistermeier"
},
{
"username": "rotnroll666"
},
{
"username": "odrotbohm"
}
]
}
}
Of course the method in the controller can be tweaked by adding parameters for respecting arguments with @Argument
or getting the requested fields (here accounts.username) to squeeze down the amount of data that gets transported
over the network.
In the previous example, the repository will fetch all properties for the given domain entity, including all relationships.
This data will get mostly discarded to return only the username to the user.
This example should give an impression of what can be done with Annotated Controllers. Adding the query generation and mapping capabilities of Spring Data Neo4j a (simple) GraphQL application was created.
But at this point both libraries seem to live in parallel in this application and not yet like an integration. How can SDN and Spring for GraphQL get really combined?
As a first step, the accounts method from the AccountController can be deleted.
Restarting the application and querying it again with the request from above will still bring up the same result.
This works because Spring for GraphQL recognizes the result type (array of) Account from the GraphQL schema.
It scans for eligible Spring Data repositories that matches the type.
Those repositories have to extend the QueryByExampleExecutor or QuerydslPredicateExecutor (not part of this blog post) for the given type.
In this example, the AccountRepository is already implicitly marked as QueryByExampleExecutor because it is extending the Neo4jRespository, that is already defining the executor.
The @GraphQlRepository annotation makes Spring for GraphQL aware that this repository can and should be used for the queries, if possible.
Without any changes to the actual code, a second Query field can be defined in the schema.
This time it should filter the results by username.
A username looks unique at the first glance but in the Fediverse this is only true for a given instance.
Multiple instances could have the very same usernames in place.
To respect this behaviour, the query should be able to return an array of Accounts.
The documentation about query by example (Spring Data commons) provides more details about the inner workings of this mechanism.
Updated query type
type Query {
account(username: String!): [Account]!
Restarting the app will now present the option to add a username interactively as a parameter to the query.
Query for an array of the same username
{
account(username: "meistermeier") {
username
following {
username
server {
uri
}
}
}
}
Obviously, there is only one Account with this username.
Response for query by username
{
"data": {
"account": [
{
"username": "meistermeier",
"following": [
{
"username": "rotnroll666",
"server": {
"uri": "mastodon.social"
}
},
{
"username": "odrotbohm",
"server": {
"uri": "chaos.social"
}
}
]
}
]
}
}
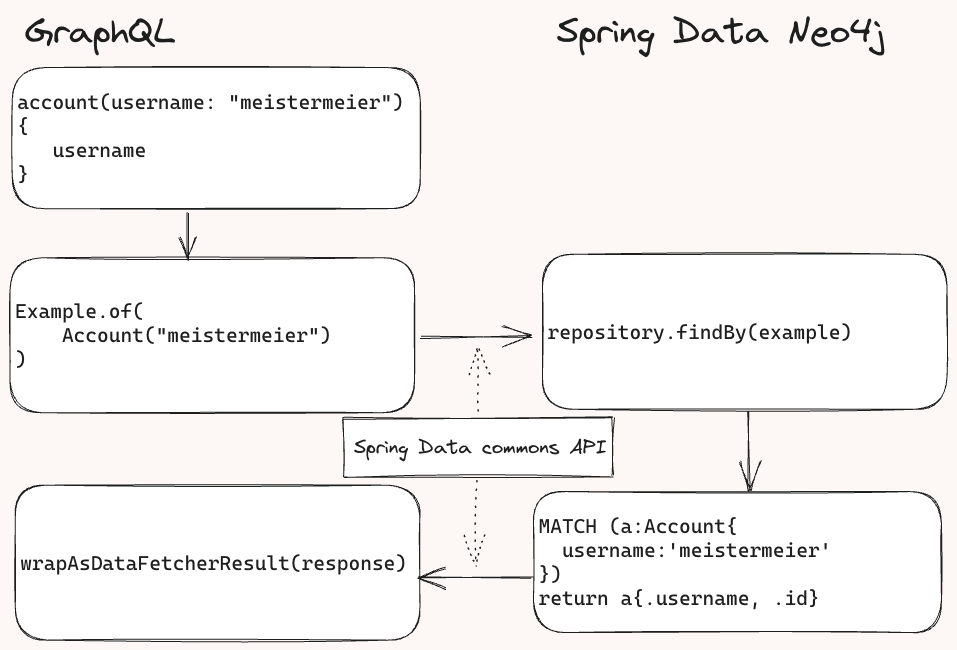
Behind the scenes Spring for GraphQL adds the field as a parameter to the object that gets passed to the repositories as an example. Spring Data Neo4j then inspects the example and creates matching conditions for the Cypher query, executes it and sends the result back to Spring GraphQL for further processing to shape the result into the right response format.
(schematic) API call flow
Although the example data set is not this huge, it's often useful to have a proper functionality in place that allows to request the resulting data in chunks. Spring for GraphQL uses the Cursor Connections specification.
A complete schema specification with all types looks like this.
Schema with cursor connections
type Query {
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
}
type AccountConnection {
edges: [AccountEdge]!
pageInfo: PageInfo!
}
type AccountEdge {
node: Account!
cursor: String!
}
type PageInfo {
hasPreviousPage: Boolean!
hasNextPage: Boolean!
startCursor: String
endCursor: String
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
Even though I personally like to have a complete valid schema, it is possible to skip all the Cursor Connections specific parts in the definition.
Just the query with the AccountConnection definition is sufficient for Spring for GraphQL to derive and fill in the missing bits.
The parameters read as following
first: the amount of data to fetch if there is no defaultafter: scroll position after the data should be fetchedlast: the amount of data to fetch before the before positionbefore: scroll position until (exclusive) the data should be fetchedOne question remains:
In which order is the result set returned?
A stable sort order is a must in this scenario, otherwise there is no guarantee that the database returns the data in a predictable order.
The repository needs also to extend the QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer and implement the customize method.
In there it is also possible to add the default limit for the query, in this case 1 to show the pagination in action.
Added sort ordering (and limit)
@GraphQlRepository
interface AccountRepository extends Neo4jRepository<Account, String>,
QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer<Account>
{
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.offset(), 1, true));
}
}
After the application has restarted, it is now possible to call the first pagination query.
Pagination for the first element
{
accountScroll {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
To get also the metadata for further interaction, some parts of the pageInfo got also requested.
Result for the first element
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "meistermeier"
}
}
],
"pageInfo": {
"hasNextPage": true,
"endCursor": "T18x"
}
}
}
}
Now the endCursor can be used for the next interaction.
Querying the application with this as the value for after and with a limit of 2...
Pagination for the last element
{
accountScroll(after:"T18x", first: 2) {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
...results in the last element(s).
Also, the marker that there is no next page (hasNextPage=false) indicates that the pagination reached the end of the data set.
Result for the last element
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "odrotbohm"
}
},
{
"node": {
"username": "rotnroll666"
}
}
],
"pageInfo": {
"hasNextPage": false,
"endCursor": "T18z"
}
}
}
}
It is also possible to scroll through the data backwards by using the defined last and before parameters.
Also, it is completely valid to combine this scrolling with the already known features of query by example
and define a query in the GraphQL schema that also accepts fields of the Account as filter criteria.
Filter with pagination
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
One of the big advantages in using GraphQL is the option to introduce federated data.
In a nutshell this means that data stored, e.g. in the database of the application, can be enriched, like in this case,
with data from a remote system / microservice /
This data federation can be implemented by making use of the already defined controller.
SchemaMapping for federated data
@Controller
class AccountController {
@SchemaMapping
String lastMessage(Account account) {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
)
.block();
}
}
Adding the field lastMessage to the Account in the schema and restarting the application,
gives now the option to query for the accounts with this additional information.
Query with federated data
{
accounts {
username
lastMessage
}
}
Response with federated data
{
"data": {
"accounts": [
{
"username": "meistermeier",
"lastMessage": "@taseroth erst einmal schauen, ob auf die Aussage auch Taten folgen ;)"
},
{
"username": "odrotbohm",
"lastMessage": "Some #jMoleculesp/#SpringCLI integration cooking to easily add the former[...]"
},
{
"username": "rotnroll666",
"lastMessage": "Werd aber das Rad im Rückwärts-Turbo schon irgendwie vermissen."
}
]
}
}
Looking at the controller again, it becomes clear that the retrieval of the data is quite a bottleneck right now.
For every Account a request gets issued after another.
But Spring for GraphQL helps to improve the situation of the ordered requests for each Account after another.
The solution is to use @BatchMapping on the lastMessage field in contrast to @SchemaMapping.
BatchMapping for federated data
@Controller
public class AccountController {
@BatchMapping
public Flux<String> lastMessage(List<Account> accounts) {
return Flux.concat(
accounts.stream().map(account -> {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
);
}).toList());
}
}
To improve this situation even more, it is recommended to also introduce proper caching to the result. It might not be necessary that the federated data gets fetched on every request but only refreshed after a certain period.
Neo4j-Migrations is a project that applies migrations to Neo4j. To be sure that always a clean state of the data is present in the database, an initial Cypher statement is provided. It has the same content as the Cypher snippet in the beginning of this post. In fact, the content is included directly from this file.
Putting Neo4j-Migrations on the classpath by providing the Spring Boot starter, it will run all migrations from the default folder (resources/neo4j/migrations).
Neo4j-Migrations dependency definition
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>${neo4j-migrations.version}</version>
<scope>test</scope>
</dependency>
Spring Boot 3.1 comes with a new features for Testcontainers.
One of this feature is the automatic setting of properties without the need to define @DynamicPropertySource.
The (to Spring Boot known) properties will get populated at test execution time after the container has started.
First the dependency definition for Testcontainers Neo4j is needed in our pom.xml.
Testcontainers dependency definition
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>neo4j</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
To make use of Testcontainers Neo4j, a container definition interface will be created.
Container configuration
interface Neo4jContainerConfiguration {
@Container
@ServiceConnection
Neo4jContainer<?> neo4jContainer = new Neo4jContainer<>(DockerImageName.parse("neo4j:5"))
.withRandomPassword()
.withReuse(true);
}
This can then be used with the @ImportTestContainers annotation in the (integration) test class.
Test annotated with @ImportTestContainers
@SpringBootTest
@ImportTestcontainers(Neo4jContainerConfiguration.class)
class Neo4jGraphqlApplicationTests {
final GraphQlTester graphQlTester;
@Autowired
public Neo4jGraphqlApplicationTests(ExecutionGraphQlService graphQlService) {
this.graphQlTester = ExecutionGraphQlServiceTester.builder(graphQlService).build();
}
@Test
void resultMatchesExpectation() {
String query = "{" +
" account(username:\"meistermeier\") {" +
" displayName" +
" }" +
"}";
this.graphQlTester.document(query)
.execute()
.path("account")
.matchesJson("[{\"displayName\":\"Gerrit Meier\"}]");
}
}
For completeness this test class also includes the GraphQlTester and an example how to test the application's GraphQL API.
It is also now possible to run the whole application directly from the test folder and use a Testcontainers image.
Application start with container from test class
@TestConfiguration(proxyBeanMethods = false)
class TestNeo4jGraphqlApplication {
public static void main(String[] args) {
SpringApplication.from(Neo4jGraphqlApplication::main)
.with(TestNeo4jGraphqlApplication.class)
.run(args);
}
@Bean
@ServiceConnection
Neo4jContainer<?> neo4jContainer() {
return new Neo4jContainer<>("neo4j:5").withRandomPassword();
}
}
The @ServiceConnection annotation also takes care that the application started from the test class knows
the coordinates the container is running at (connection string, username, password...).
To start the application outside the IDE, it is now also possible to invoke ./mvnw spring-boot:test-run.
If there is only one class with a main method in the test folder, it will get started.
In parallel to the QueryByExampleExecutor, support for QuerydslPredicateExecutor exists in the Spring Data Neo4j module.
To make use of it, the repository needs to extend the CrudRepository instead of the Neo4jRepository and also declare it
as a QuerydslPredicateExecutor for the given type.
Adding support for scrolling/pagination would require to also add the QuerydslDataFetcher.QuerydslBuilderCustomizer and implement its customize method.
The whole infrastructure presented in this blog post is also available for the reactive stack.
Basically prefixing everything with Reactive... (like ReactiveQuerybyExampleExecutor) will turn this into a reactive application.
Last but not least, the scroll mechanism used here is based on an OffsetScrollPosition.
There is also a KeysetScrollPosition that can be used.
It makes use of the sort property/properties in combination with the defined id.
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.keyset(), 1, true));
}
It's nice to see how convenient methods in Spring Data modules do not only provide a broader accessibility for users' use-cases, but also get used by other Spring projects to reduce the amount of code that needs to be written. This results in less maintenance for the existing code base and helps focussing on the business problem instead of infrastructure.
This post got a little bit longer because I explicitly want to touch at least the surface on what is happening when a query gets invoked without speaking just about the automagical result.
Please go ahead and explore more about what is possible and how the application behaves for different types of queries. It is next to impossible to cover every topic and feature that is available within one blog post.
Happy GraphQL coding and exploring. You can find the example project on GitHub at https://github.com/meistermeier/spring-graphql-neo4j.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all