Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreWith Spring Framework 6.1 and Spring Boot 3.2 general availability approaching, we would like to share an overview about several efforts the Spring team is pursuing to allow developers to optimize the runtime efficiency of their applications.
We are going to cover the following technologies and use cases:
If you prefer watching a video than reading a blog post, we recommend the “Spring Framework 6: Strategic Themes” presentation from Devoxx Belgium 2023:
Let’s begin with the most important question: why should we care about improving runtime efficiency of our Cloud workloads? The first reason is probably cost optimization. We all want to run our applications in a cheaper way. Cheaper hosting usually means using less CPU, less memory, less resources, which makes our workloads more sustainable. We are also in a world where running your application will probably involve Kubernetes and containers one way or another, which usually requires extra care with the Java Virtual Machine startup time, warm-up time and memory management.
The goal of the Spring team is to allow various options (some of them can be combined) to optimize the runtime footprint and the scalability of the millions of Spring workloads in production. Our goal is to minimize as much as possible the amount of changes required in your Spring application to take advantage of those improvements, but of course there are usually trade-offs involved, trade-offs that we are going to make as explicit as possible. Hopefully, that should give you enough information to get a clearer picture of how that applies to your organization, your applications, and see which trade-offs are worth it for your context.
A common requirement to take advantage of those runtime efficiency improvements is to upgrade to Spring Boot 3, based on Spring Framework 6, which has a Java 17 baseline and requires transitioning from Java EE (javax package) to Jakarta EE (jakarta package). When you do such an upgrade, a set of new runtime efficiency features are made available to you.
Let’s begin with a technology just released, available as of Java 21. Virtual Threads intend to reduce the cost of server applications written in the simple and popular thread-per-request style to scale with near-optimal hardware utilization.
Virtual Threads make blocking on I/O cheap and are therefore an ideal fit for Spring Web MVC applications on a Servlet stack. Spring MVC can take full advantage of those new runtime characteristics on e.g. Tomcat or Jetty with a Virtual Threads setup. This does not require code changes in most use cases and adapts naturally to provide optimal performance without having to fine-tune a thread pool configuration.
We have also heard the feedback from the Spring community asking us to not only give the choice between RestTemplate in maintenance mode and a reactive WebClient.
So we took the decision to introduce a “Virtual Threads friendly modern HTTP client” named RestClient (also an attractive option without Virtual Threads of course) in Spring Framework 6.1. Spring Cloud Gateway and related infrastructure across the Spring portfolio can equally benefit from a Virtual Threads setup along with Spring MVC, providing a consistent overall experience.
So, what does that mean for WebFlux and the reactive stack?
We, on purpose, chose to have distinct blocking and reactive stacks to take full advantage of reactive in WebFlux server, and to keep the Spring Web MVC stack (by far the most frequently used web stack on start.spring.io) as lean as possible with a regular blocking thread architecture. Spring MVC on a Servlet container is ideally positioned for Virtual Threads as an appealing solution for improving the scalability of traditional web applications. WebFlux server on the other hand provides an optimized reactive stack as an ideal fit with a Netty I/O setup, delivering equivalent runtime benefits through a different programming model.
When you need application-level concurrency (for example sending multiple remote HTTP requests, potentially streamed, and combine the result), Project Loom structured concurrency may provide an interesting low-level building block in the future, but this is not the kind of API that developers typically need in Spring applications (and it is still in preview). For such a use case, WebFlux and reactive APIs like Reactor have an unmatched added value for the time being, as well as Kotlin Coroutines and their Flow type which provides an interesting combination of imperative and declarative programming models. RSocket is another example of great added value of a reactive interaction model.
Note that you do not have to choose one or the other since Spring MVC provides optional reactive support as well. So if you need to deal with concurrency just for a few use cases in your server application, you can simply use a Spring MVC stack with a Virtual Threads setup and seamlessly include e.g. reactive WebClient interactions in your web controllers, with Spring MVC adapting reactive return values to Servlet async responses. This reactive support in Spring MVC is entirely optional, with Reactor and Reactive Streams only needed in the stack when actually using reactive endpoints, and with the HTTP stack being based on a Servlet container such as Tomcat or Jetty (rather than Netty).
For typical web scenarios, we expect Virtual Threads to become a common choice with Spring MVC as a lean web server stack for Spring developers on Java 21+. The wider Java ecosystem has to fully adapt to Virtual Threads still, avoiding any thread pinning e.g. in common JDBC driver implementations, but even that is expected to be resolved soon. Make sure to use Spring Boot 3.2 or higher, to set the property spring.threads.virtual.enabled to true, and to use the latest library and driver versions available for your evaluation of Virtual Threads.
We continue to refine the GraalVM native support introduced in Spring Boot 3. The main use case is building an optimized container image with Buildpacks that contains a tiny operating system base layer and your application compiled to a native executable thanks to Spring AOT (Ahead Of Time) transformations and GraalVM native image compiler. No JVM distribution needed.
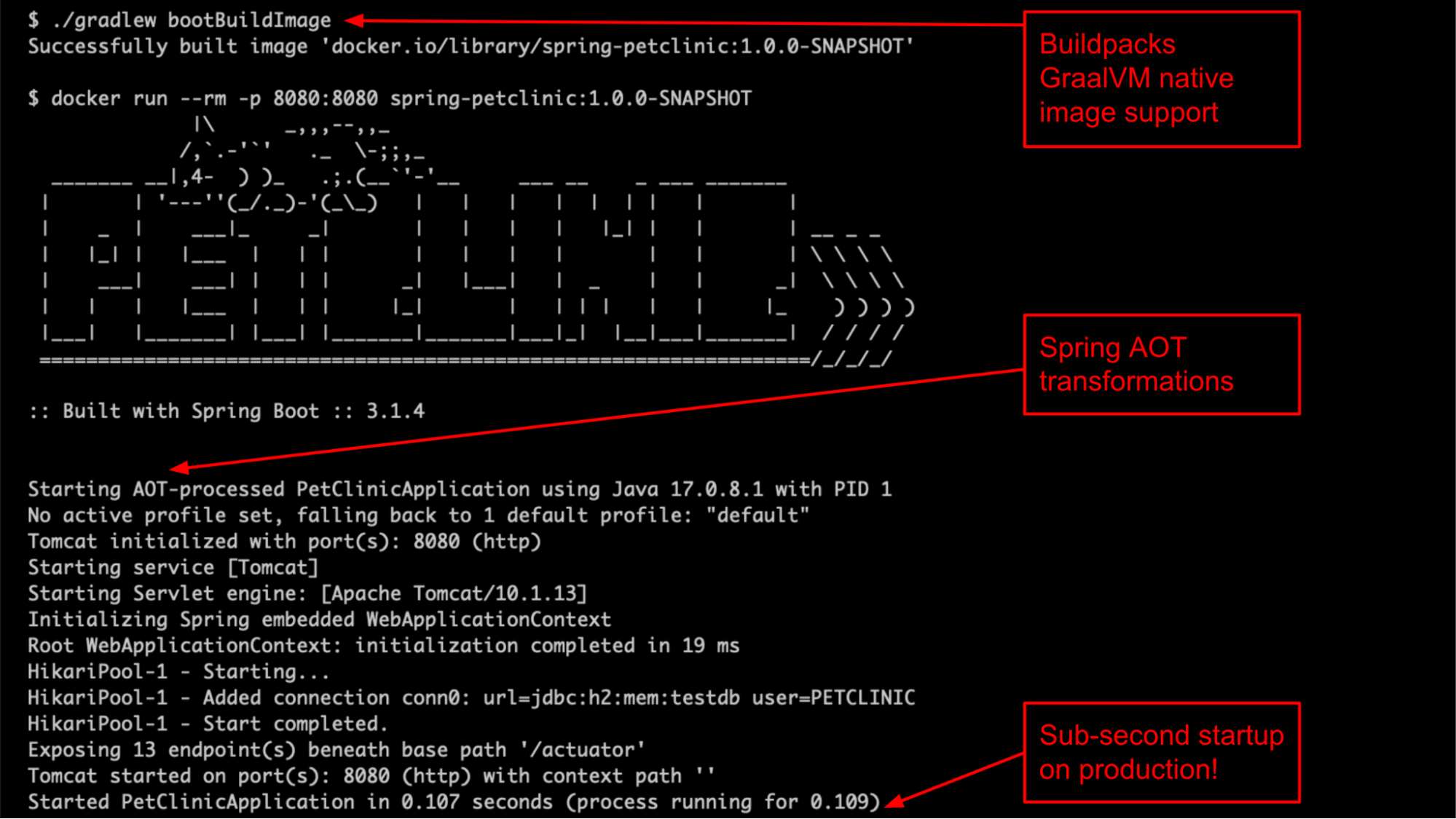
That allows the deployment of tiny containers that start in dozens of milliseconds (typically 50x faster than the startup time on a regular JVM) with lower memory consumption for your application infrastructure and peak performance available immediately.
GraalVM follows new Java features very closely, and for example already provides first-class Virtual Threads support: see Josh Long’s recent All together now blog post.
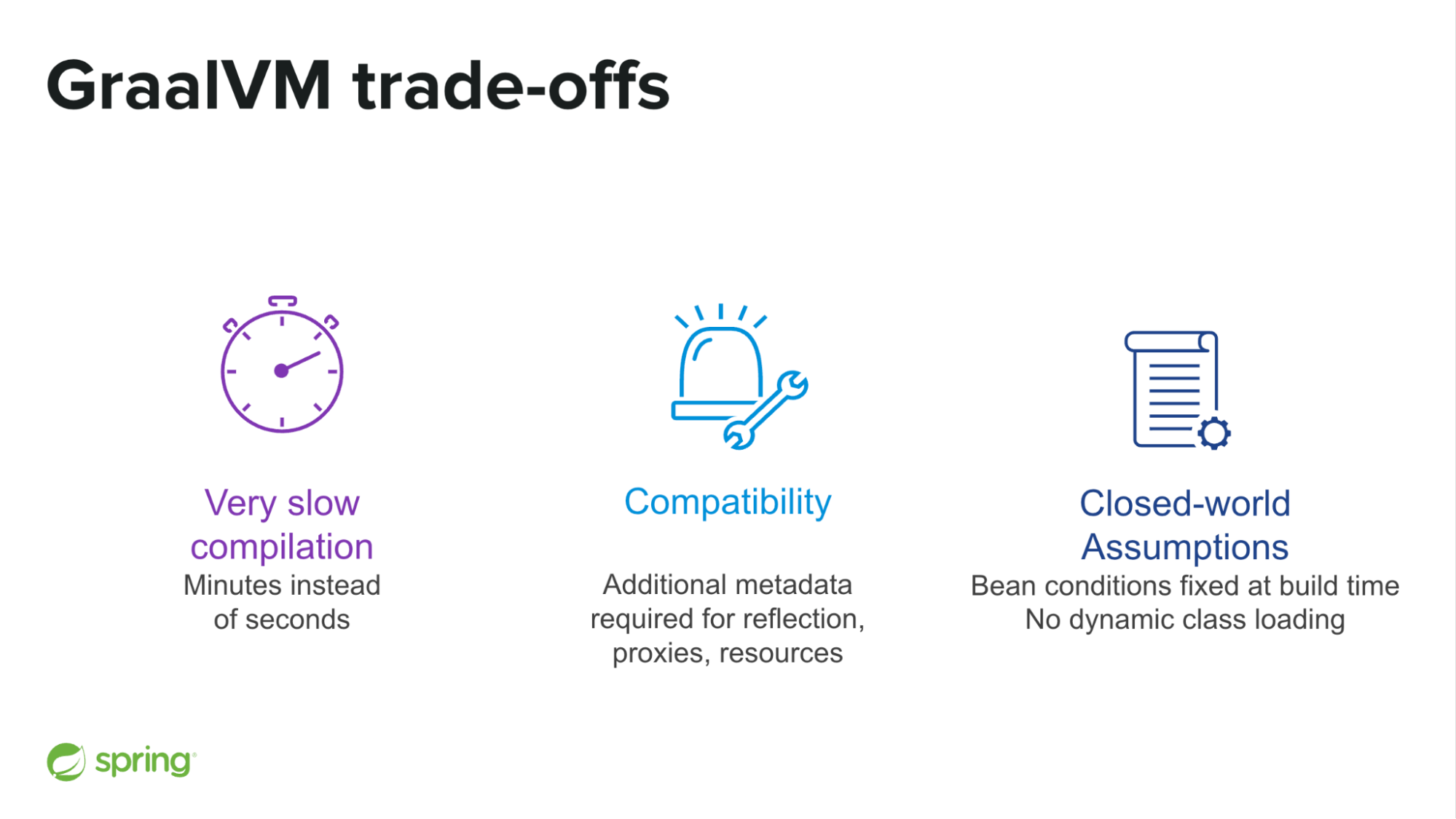
GraalVM’s excellent runtime characteristics are possible due to different trade-offs compared to the JVM. A native image compilation takes minutes instead of seconds. It requires additional metadata in order to properly handle reflection, proxies and other dynamic behaviors of the JVM. Spring infers a lot of those metadata, but any real project will likely require some additional hints to work properly (for your organization dependencies for example). Finally, the combination of Spring AOT transformations and GraalVM native image requires us to freeze the classpath and the Spring Boot bean conditions at build time. You will typically be able to change the URL or the password of your database in the runtime configuration, but not to change the database type or do something that changes the structure of the Spring beans.
Historically, another drawback has been the limited peak performance due to the lack of just-in-time compilation, but the release of Oracle GraalVM under the GraalVM Free Terms and Conditions license (see related restrictions) challenges this assumption. You can subscribe to this related Buildpacks RFC to follow its potential upcoming support, and you can already try it with your Spring Boot workloads using this simple Dockerfile as a starting point.
With instant startup and peak performance available immediately, Spring Boot native applications can scale to zero. Let’s explore what that means.
Scale to zero is a kind of generalization of serverless. Workloads can be deployed not only to serverless cloud platforms, but also to any Kubernetes or cloud platform providing the capability to scale to zero when there is no request to process. With Kubernetes, you can use solutions like Knative or KEDA to scale to zero. And you are not limited to functions, you can scale to zero with any kind of application, any kind of programming model, traditional web applications included. The most important characteristic of serverless is not technical, it is the pay-as-you-use billing model it enables.

There are various use cases where scaling to zero can be interesting. The JVM is amazing at developing high traffic websites, but let’s be honest, we also develop a lot of small back-office applications, typically not used all of the time. Why should we pay when nobody is using them? There are also staging environments which typically need to be up a small fraction of the time, and microservices where caching allows shutting down a few of them most of the time. And let’s not forget high availability which forces us to maintain two instances for each service always up in case of emergency because our application startup time is too long to recover from hazards.
But how to scale to zero for projects that can’t accept the trade-offs that GraalVM native image requires?
CRaC is an OpenJDK project that defines a new Java API to allow you to checkpoint and restore an application on the HotSpot JVM, developed by Azul Systems and also supported by AWS Lambda and IBM OpenLiberty in the meantime. It is based on CRIU, a project that implements checkpoint/restore functionality on Linux.
The principle is the following: You start your application almost as usual but with a CRaC enabled version of the JDK. Then at some point, potentially after some workloads that will make your JVM hot by executing all common code paths, you trigger a checkpoint using an API call, a jcmd command, an HTTP endpoint, or another mechanism.
A memory representation of the running JVM, including its warmness, is then serialized to disk, allowing a very fast restoration at a later point, potentially on another machine with a similar operating system and CPU architecture. The restored process retains all the capabilities of the HotSpot JVM, including further JIT optimizations at runtime.
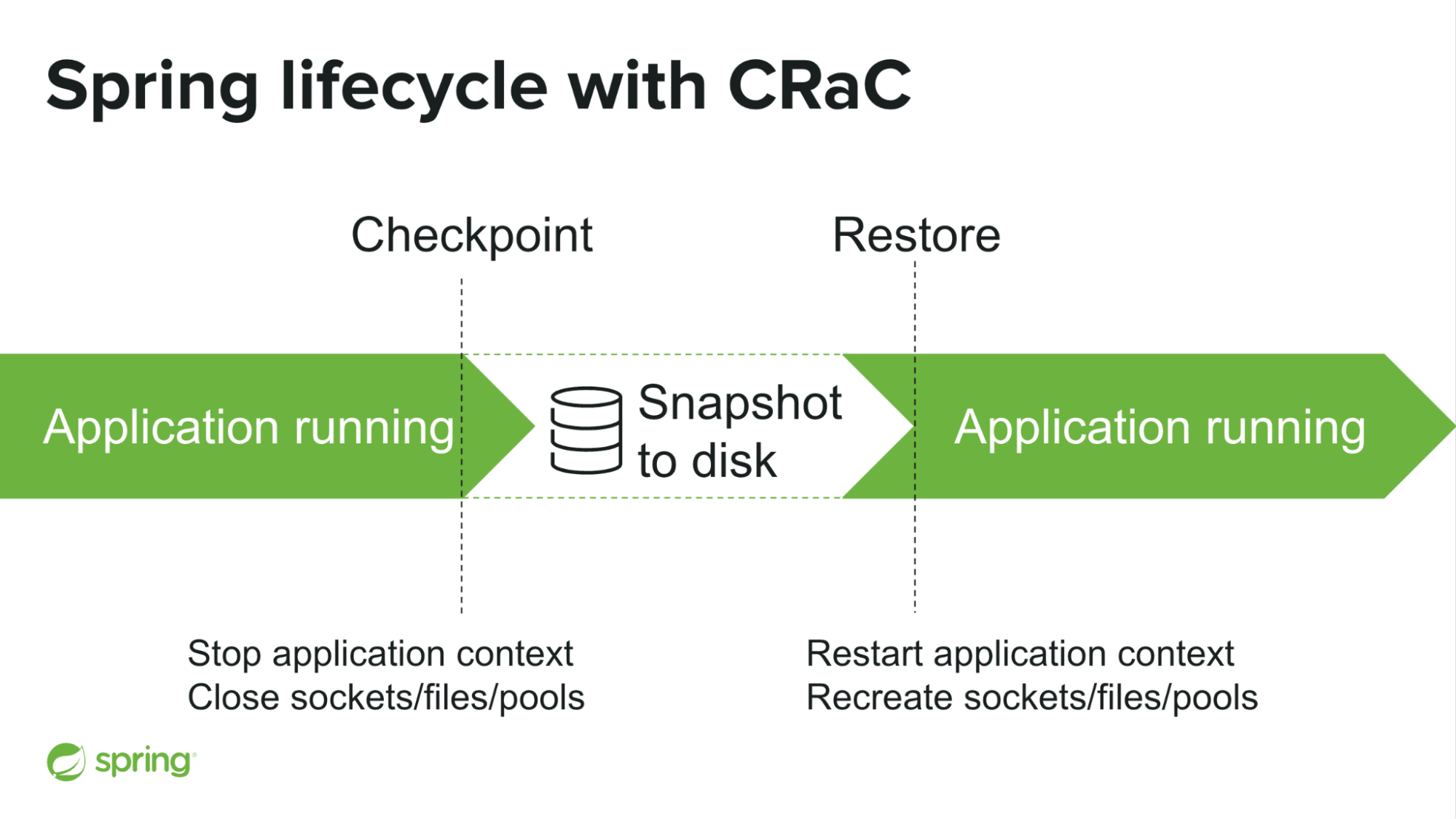
It is interesting to notice that “Checkpoint” and “Restore” match very well with the Spring application context lifecycle stop and start phases. Spring Framework 6.1 CRaC support is mainly about mapping CRaC and Spring lifecycle together, the rest of the support is not tied to CRaC and is mainly about Spring lifecycle refinements designed to properly close and recreate socket, files and pools. The goal here, in addition to the regular start and stop lifecycle, is to support multiple stop and restart cycles.
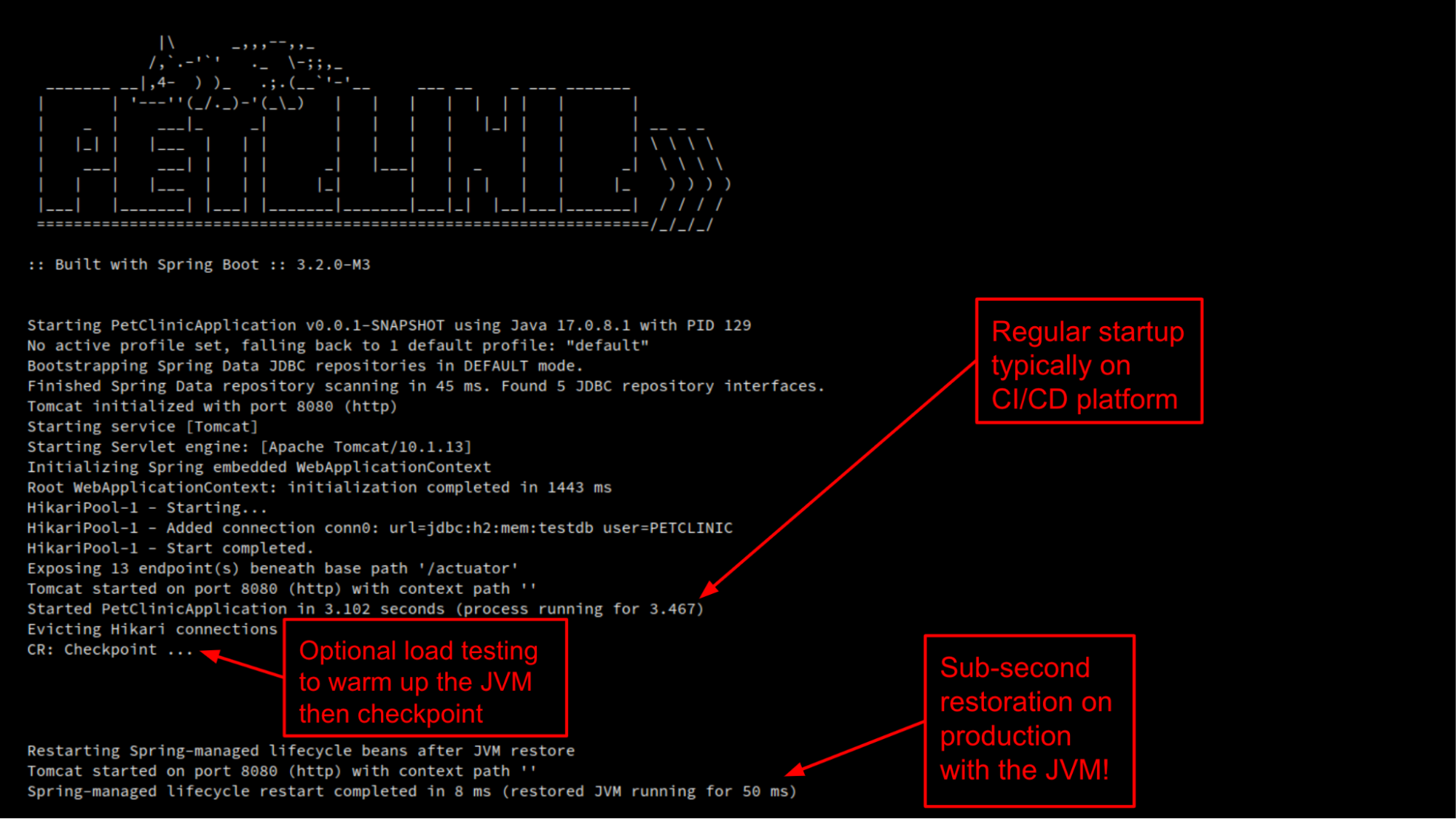
Like GraalVM, Project CRaC allows an application to scale to zero with instant startup of a few dozens of milliseconds even on small servers. That’s 50x faster than a regular JVM cold start and similar to GraalVM native image. But let’s explore the trade-offs involved.
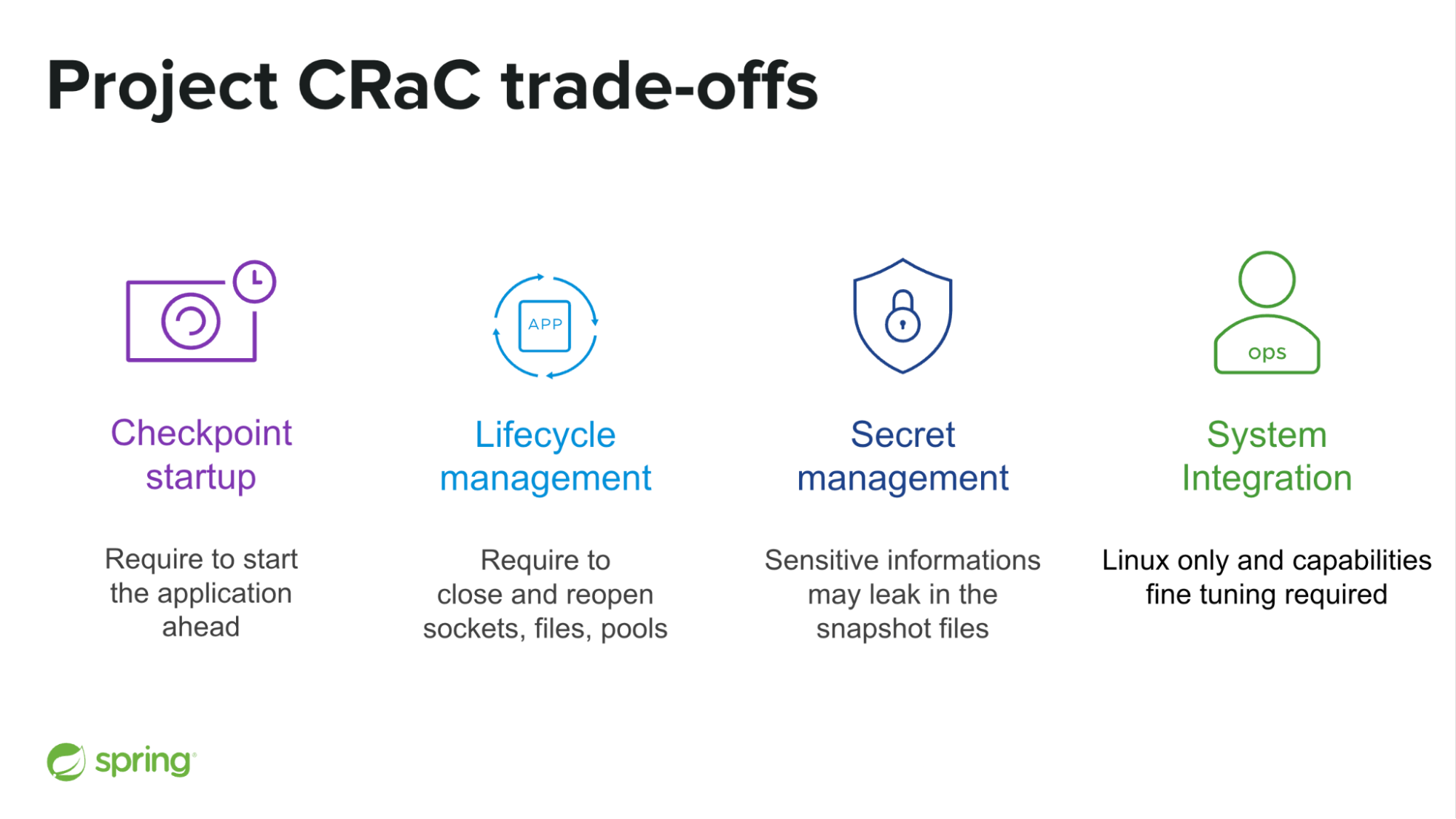
The first trade-off is that CRaC requires you to start your application ahead of time, before going to production. So should you start it on your CI/CD platform? With or without your production remote services? That raises a bunch of non-trivial questions.
The second trade-off is the need for any feature involving sockets, files and pools to be closed and then to properly recreate those resources based on the CRaC lifecycle. Spring Boot takes care of that for you for the supported scope. But some libraries simply don’t support that yet, so it may take some time before all of your stack is fully supported.
The third trade-off is in our opinion the most tricky one. It may be tempting to create a self-contained ready-to-restore container image. But any secret loaded in memory during the checkpoint startup will be serialized to the snapshot files, leaking potentially sensitive information like your production database password.
A potential solution could be to perform the checkpoint startup without the production environment configuration, and update your application configuration at restoration time. It is possible to do that using Spring Cloud Context and @RefreshScope annotations. The Spring team may explore that topic in the future to see if more built-in support makes sense. You can also adopt the strategy to create and store the snapshot files on encrypted volumes directly on your Kubernetes platform, even if that requires deeper platform integration.
The last key characteristic is that CRaC is Linux specific, and requires some Linux capabilities fine tuning to work without the privileged mode.
Keep in mind that we are in the early days of Project CRaC, and that Spring Boot 3.2 is the first release to support it. Some of those limitations will probably be lifted as the checkpoint restore technology evolves along with Spring’s support. And check the Spring Framework related documentation and https://github.com/sdeleuze/spring-boot-crac-demo if you want to try this technology by yourself.
We have seen two ways for your Spring workloads to scale to zero with GraalVM and CRaC but involving non-trivial trade-offs. What if there was another way to improve your Spring Boot runtime characteristics with fewer constraints?
You may have heard about Project Leyden, a new OpenJDK project that intends to improve the startup time, time to peak performance, and footprint of Java programs. We recommend watching this related talk by Brian Goetz himself if you want to learn more.
Project Leyden has recently introduced “premain” optimizations (basically Class Data Sharing + AOT on steroids) and interestingly, the Java Platform team identified a great synergy with the Spring Ahead-Of-Time optimizations, originally created to allow GraalVM native image support, but already capable of providing a 15% faster startup time on the JVM.
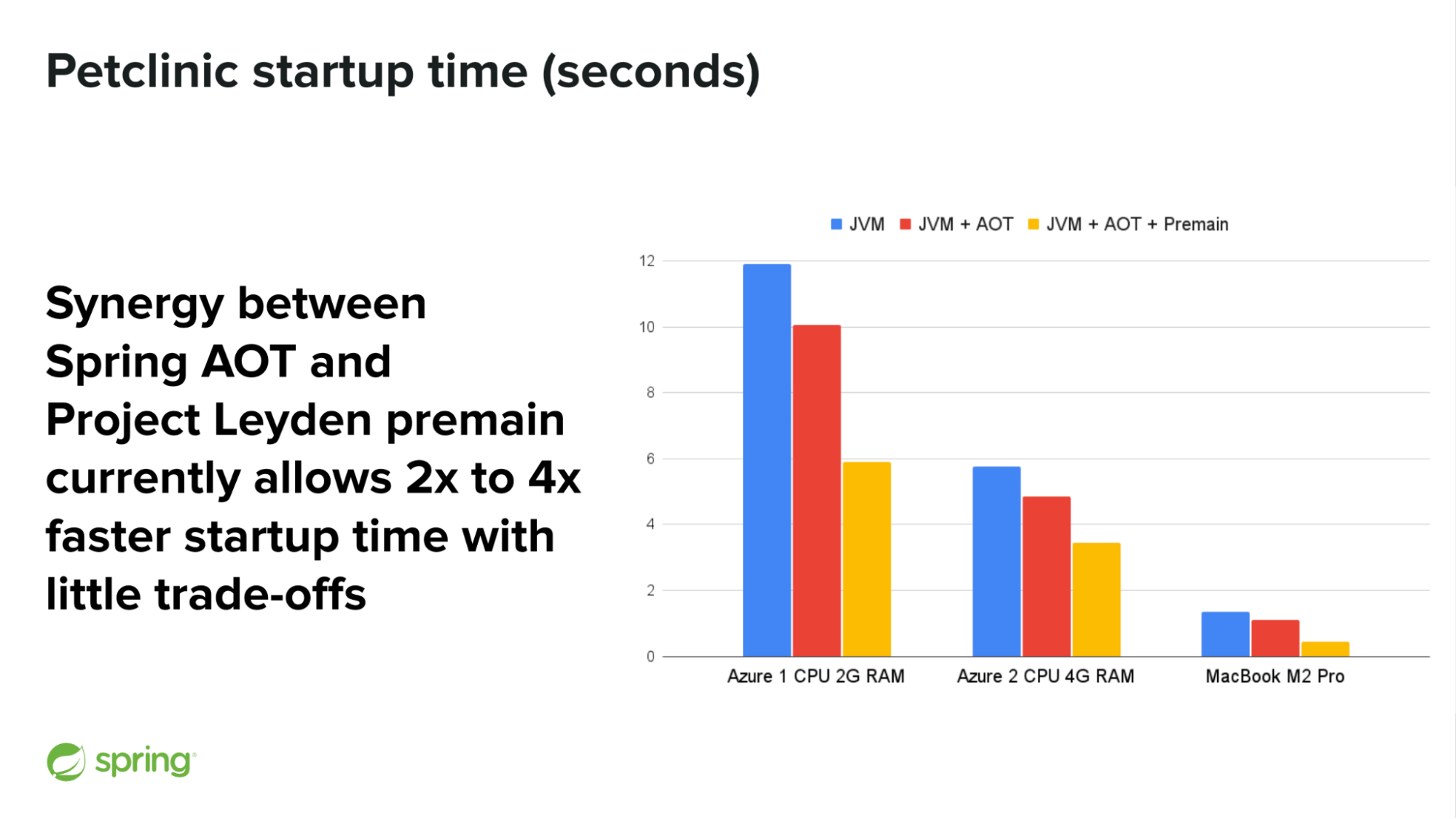
While “premain” optimizations are highly experimental (for now it is an experimental branch of the Leyden repository on GitHub), the Spring team has recently been able to measure 2x to 4x faster startup time for the Spring Petclinic sample application by combining Spring AOT on the JVM and those optimizations from Project Leyden, as well as faster warm-up with hardly any trade-off.
In their current form, unlike GraalVM and CRaC, those optimizations do not enable scaling to zero because they don’t allow applications to start in dozens of milliseconds in production. But well, if we get a significant improvement of the JVM startup and warm-up time with hardly any constraints, it has the potential to go mainstream and to be combined with other upcoming Leyden features that you could choose à la carte.
We are happy to share that we have started a collaboration between the Java Platform Group and the Spring team to see how far we can push the boundaries of what is possible using Project Leyden’s premain approach. In combination with Spring AOT refinements specifically designed for the JVM, we expect further optimizations applicable to a wide range of Spring applications. We will share more in the upcoming months.
Check the https://github.com/sdeleuze/spring-boot-leyden-demo repository if you want to try it yourself.
Listening to feedback from the Spring community across the world has proven to be a key source of inspiration for the Spring team, as well as pragmatic collaborations with companies such as Oracle, Bellsoft, Azul, and many others.
We are working hard on supporting those new capabilities while minimizing the impact for Spring application development, providing straightforward upgrade paths for the many kinds of applications out there. This is the most challenging but also the most rewarding aspect of our strategic infrastructure efforts.
Last but not least, we are looking for feedback on what you are most excited about for your organization and your projects. Do you think scale-to-zero and the pay-as-you-use billing model are worth the trade-offs required by GraalVM or CRaC? Is the reduced memory consumption provided by GraalVM native image a key advantage for you? Do you think Spring AOT on the JVM combined with Project Leyden has high potential? What is your perspective on Virtual Threads? Please let us know!

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all