Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreWe are happy to announce the 1.0.0 Milestone 3 release of Spring AI.
This release brings significant enhancements and new features across various areas.
This release introduces many refinements to the observability stack, particularly for streaming responses from Chat Models. Many thanks to Thomas Vitale and Dariusz Jedrzejczyk for all their help in this area!
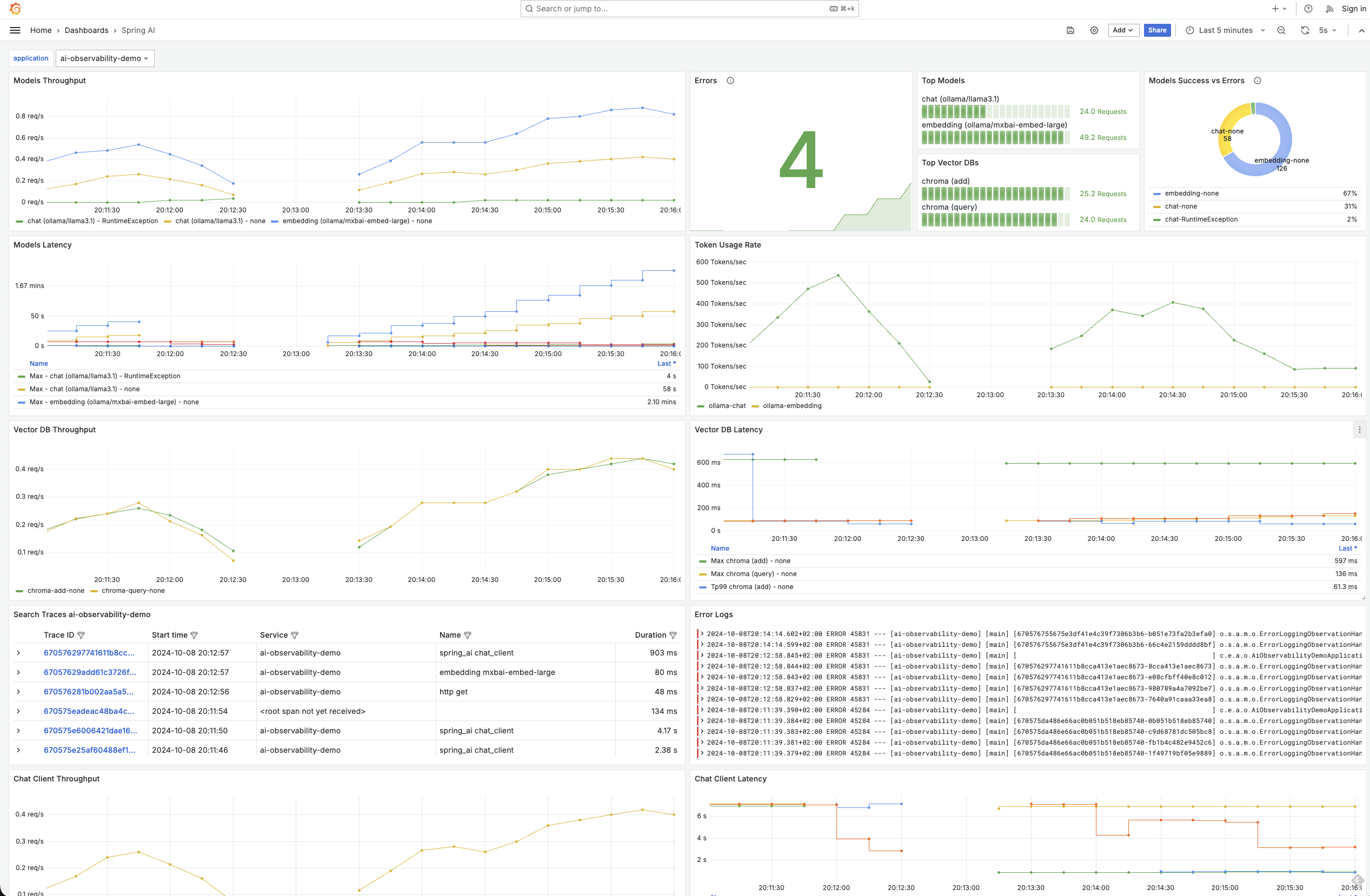
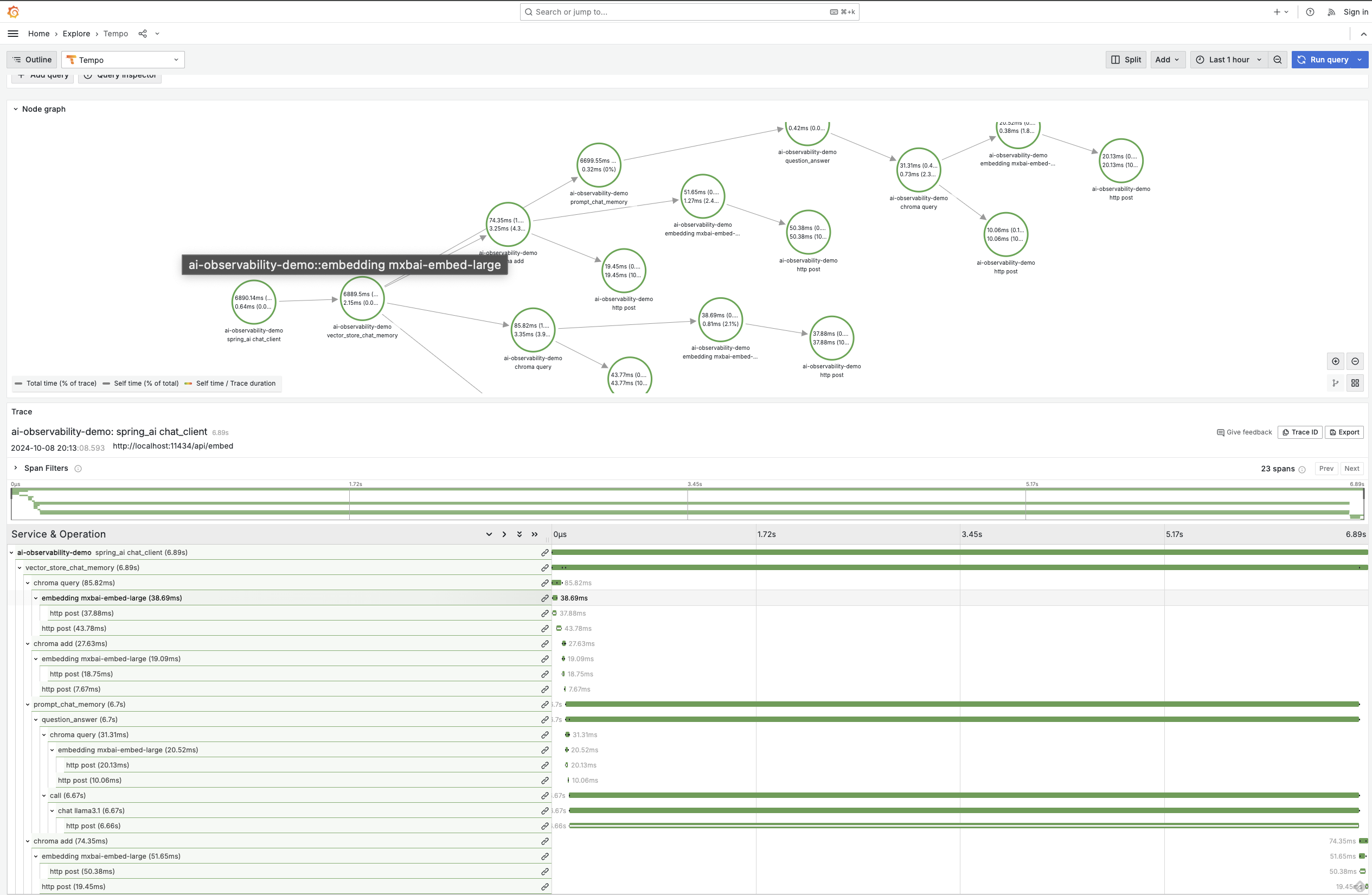
Observability covers the ChatClient, ChatModel, Embedding Models and Vector stores enabling you to view all touchpoints with your AI infrstructure in fine grained detail..
In the M2 release we introduced observability support for OpenAI, OIlama, Mistral and Anthropic models. Now we have expanded this to include support for
Thanks to Geng Rong for implementing observability to the Chinese models.
You can find more detailed information on the available metrics and traces that are available in the observability reference documentation. Here are some graphs to demonstrate what's possible.
Spring AI Advisors are components that intercept and potentially modify the flow of chat-completion requests and responses in your AI applications. Advisors can also choose to block the request by not making the call to invoke the next advisor in the chain.
The key player in this system is the AroundAdvisor, which allows developers to dynamically transform or utilize information within these interactions.
The main benefits of using Advisors include:
We have revisited the Advisor API model and made many design changes and improved it's ability to apply to streaming request and responses. You can also explicitly define the order of the advisor's using Spring's Ordered interface.
Depending on what areas of the API you have used, there can be breaking changes, see the docs for more details.
The flow of the around advisor is depicted below.

You can read Christian Tzolov's recent blog Supercharging Your AI Applications with Spring AI Advisors for more detials.
Spring AI now supports passing additional contextual information to function callbacks through a ToolContext class that contains key-value pairs.
This feature allows you to provide extra data that can be used within the function execution.
In this example we are passing in a sessionId, so that the context is aware of that value:
String content = chatClient.prompt("What's the weather like in San Francisco, Tokyo, and Paris?")
.functions("weatherFunctionWithContext")
.toolContext(Map.of("sessionId", "123"))
.call()
.content();
Also note that you can pass the user text in the prompt method as an alternative to using the user method.
The ToolContext is available by using a java.util.BiFunction. Here is the bean definition:
@Bean
@Description("Get the weather in location")
public BiFunction<WeatherService.Request, ToolContext, WeatherService.Response> weatherFunctionWithContext() {
return (request, toolContext) -> {
String sessionId = (String) toolContext.getContext().get("sessionId");
// use session id as appropriate...
System.out.println(sessionId);
return new WeatherService().apply(request);
};
}
If you prefer to handle the function calling conversation yourself, you can set the proxyToolCalls option.
PortableFunctionCallingOptions functionOptions = FunctionCallingOptions.builder()
.withFunction("weatherFunction")
.withProxyToolCalls(true)
.build();
And passing these optionsa call to the model via a ChatModel or ChatClient will return a ChatResponse that contains the first message sent at the start of the AI model’s function calling conversation.
There have been some notable innovations in the area of factual evaluation with a new leaderboard named LLM-AggreFact. A model currently leading the benchmark is “bespoke-minicheck” developed by Bespoke Labs. Part of what makes this model compelling is that is much smaller and cheaper to run as compared to so called “flagship” models such as GPT4o. You can read more into the research behind this model in the paper “MiniCheck: Efficient Fact-Checking of LLMs of Grounding Documents.
The Spring AI FactCheckingEvaluator is based on that work and can be used with the Bespoke-minicheck model deployed on Ollama. See the documentation for more information. Thanks to Eddú Meléndez for his work in this area.
Previously, embedding a list of documents required making calls item by item, which was not very performant. Spring AI now supports batching multiple documents together so that multiple embeddings can be computed in a single call to the model. Since embedding models have token limits, documents are grouped such that each batch doesn't exceed the token limit for the embedding model.
The new class TokenCountingBatchingStrategy takes into account the token size and allocates a 10% reserve buffer, as token estimation isn't an exact science. You can customize your own implementations of the BatchingStrategy interface.
Additionally, JDBC-based embedding models can now more easily customize the batch size to use when doing bulk inserts.
Thanks to Soby Chacko for his work in this area and other contributions as a new member of the Spring AI team.
Azure AI
Vertex AI
Many refactoring, bug fixing, documentation enhancements across the board by a wide range of contributors. If we haven’t gotten to your PR yet, we will, please be patient. Thanks to

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all