Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreAs a Java developer exploring the world of generative AI, you’re probably aware of several frameworks that promise to make AI integration easy. I believe Spring AI stands out as the natural choice, especially for developers already working within the Spring ecosystem. Built on the same foundation as Spring Boot and Spring Data, Spring AI makes adding AI capabilities to your applications seamless and intuitive, without requiring you to learn an entirely new set of paradigms.
One of Spring AI’s most significant advantages is its deep integration with the Spring ecosystem. If you’re already familiar with developing Spring Boot applications, Spring AI will feel like an extension of what you already know. The same concepts that drive Spring Data—such as dependency injection, annotations, and clean abstractions—apply to Spring AI as well. This consistency means you can dive into AI without needing to rethink how you develop your application.
Unlike some tools, Spring AI doesn’t require complex configurations or workflow setups to get started. It fits neatly alongside your existing codebase, allowing you to reuse your existing beans, services, and repositories. Instead of bolting on an external AI platform, Spring AI integrates directly with the business logic and enterprise services you’ve already built, leveraging your investment in the Spring ecosystem.
Spring AI focuses on simplifying AI operations for enterprise-grade applications. It’s ideal for developers who need to add straightforward AI features—like text generation, embeddings, and function calling—into their business applications. The beauty of Spring AI lies in its simplicity: you get the power of generative AI without the overhead of managing complex workflows or orchestrating multi-step processes. For most enterprise use cases, where AI serves to enhance features rather than power entire workflows, Spring AI delivers exactly what’s needed.
Another key strength of Spring AI is its integration with vector stores. Whether you’re using Postgres with pgVector, Redis, or any of the other supported vector-capable databases, Spring AI extends Spring’s well-known capabilities to handle vector embeddings and other AI-driven data storage needs.
Spring AI makes it incredibly easy to switch between different vector store implementations. Using the same dependency injection patterns familiar to Spring developers, you can swap out one vector store for another simply by changing a Spring Boot Starter dependency—without touching your core application logic. This flexibility is a significant advantage for developers building AI-enhanced applications that require scalable, efficient storage and retrieval of embeddings or other AI-generated data.
Embedding source data into a vector store is a powerful capability, but how do you handle different data structures before embedding? With Spring AI, you have access to ready-to-use document readers that allow you to process various formats, including PDF, Markdown, Microsoft Word and PowerPoint documents, HTML, and more. The Document Reader feature ensures that you can work with a wide variety of source formats. If a particular format isn't supported, creating your own implementation is straightforward.
One of the standout features of Spring AI is its support for metadata filtering on embeddings, which is agnostic to the underlying vector store implementation. In typical RAG (Retrieval-Augmented Generation)-based applications, a similarity search is performed on a vector store, calculating a distance metric (e.g., cosine similarity) between a query and each data point in the dataset. While this approach can be manageable with smaller datasets, it becomes increasingly challenging as the volume of data grows. To address this, vector stores implement various performance-enhancing algorithms, such Approximate Nearest Neighbor (ANN), Locality-Sensitive Hashing (LSH), or Hierarchical Navigable Small World (HNSW).
To further address this challenge, an additional effective strategy is to reduce the amount of data to be queried before performing the similarity search in the first place. For instance, if you're only interested in customers located in Boston, you can filter the dataset down to just the customers who live there. This reduction process is known as metadata filtering.
Many vector stores provide their own implementations of metadata filtering, each with its strengths and limitations. However, Spring AI offers a vendor-neutral solution that bridges the gap between various vector stores. This capability is particularly valuable in enterprise applications where semantics alone may not suffice, and certain Personal Identifiable Information (PII) data must be excluded from a similarity search. By leveraging metadata filtering, the similarity search can be performed only on the relevant subset of documents, rather than scanning the entire dataset.
Here is a simple example, with more detailed information available in the Spring AI reference documentation:
public void example() {
// Assume we have a large dataset of customers.
// Embedding the data is computationally expensive
// but it is typically a one-time / ETL process
List<Document> allMyCustomers = new ArrayList<>();
allMyCustomers.add(new Document("""
{
"customerId": 12345,
"name": "John Doe",
"email": "[email protected]",
"phone": "+1234567890",
"address": "123 Main St, Boston, MA"
}
""", Map.of("city", "Boston"))); // Metadata filter!
// Add more customers...
allMyCustomers.add(...);
// Add all embedded documents and their
// associated metadata to the vector store
vectorStore.add(allMyCustomers);
// Prepare a search query, for example:
// "Which customers are named John?"
SearchRequest searchRequest =
SearchRequest.query("Which customers are named John?");
// This similarity search is computationally intensive
List<Document> results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll());
// Instead, we'll first filter by city to reduce the dataset size,
// then perform the similarity search on the filtered results
results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll()
.withFilterExpression("city == 'Boston'"));
}
One of Spring AI’s standout features is its function-calling capability, which simplifies AI interaction in enterprise applications by solving its biggest challenge: integrating with your own APIs!
I recently read a LinkedIn post by Jonathan Schneider that caught my attention. He wrote that function calling to Retrieval-Augmented Generation (RAG) is like what IoC was to Java development. IoC allowed developers to focus on business logic while Spring managed object creation and dependency wiring. In a similar fashion, function calling in Spring AI allows developers to focus on what their functions do, while the Large Language Model (LLM) takes care of the complex interactions behind the scenes.
You describe what your function does in natural language, and Spring AI ensures that the LLM understands and executes it when needed. This dramatically reduces the amount of boilerplate code typically required for interacting with AI models, letting you focus on building features rather than managing the intricacies of AI processes.
Here’s a simple example from the Spring AI Reference documentation:
@Configuration
static class Config {
@Bean
@Description("Get the current weather in location")
public Function<WeatherService.Request, WeatherService.Response> currentWeather() {
return new MockWeatherService();
}
}
public class WeatherService implements Function<Request, Response> {
public enum Unit { C, F }
public record Request(String location, Unit unit) {}
public record Response(double temp, Unit unit) {}
public Response apply(Request request) {
// Logic goes here!
}
}
There are no AI models trained to provide real-time weather data for a specific location at this exact moment. As a result, an LLM might respond that it doesn't know the answer—or worse, it could return a hallucinated response.
However, by registering a function like the one above, Spring AI allows the LLM to infer from the @Description annotation that this function can provide real-time weather data. The LLM can then construct a request in the correct format for WeatherService.Request, based on the user's input. For instance, if a user asks, "What’s the weather in Boston?", the LLM would automatically populate the Request object with the location and unit, ask Spring AI to invoke the function, retrieve the actual weather data from the WeatherService, and then format a human-readable response for the user based on that data.
Here’s a step-by-step breakdown of the call flow:
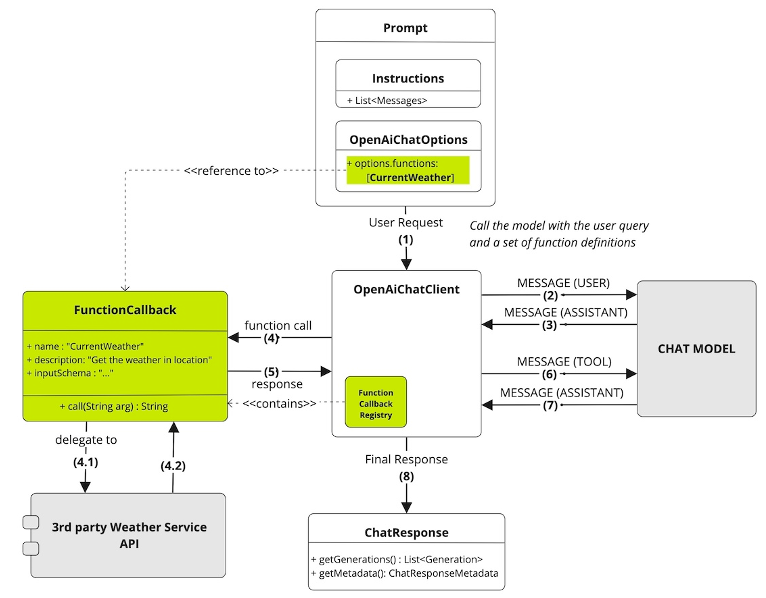
While vector stores pre-process your data by embedding it in a format that the LLM can understand, function calling enables the LLM to interact with your existing transactional APIs in real-time, allowing it to generate meaningful responses as needed.
Spring AI introduces Advisors, a powerful mechanism for handling cross-cutting concerns in AI applications. If you’re familiar with Aspect-Oriented Programming (AOP) interceptors, or Spring MVC Interceptors, the concept is similar. However, recognizing that not all developers may be familiar with these terms, the Spring AI team chose to use "Advisor" to emphasize its purpose—enhancing the request/response prompt flow—rather than the technical details of its operation, which involves intercepting requests/responses and applying filters. Advisors simplify the management of tasks such as logging, message transformations, and chat memory management, all while keeping your application code clean and uncluttered.
By offloading these routine tasks, Advisors ensure that your application remains focused on business logic while essential AI-related operations run seamlessly in the background. This approach maintains clarity in your codebase while effectively addressing necessary operational concerns.
Here’s a simple example:
this.chatClient = builder
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
new SimpleLoggerAdvisor())
.build();
This chat client integrates two advisors: a memory advisor, which appends previous user prompts to the current message for context and continuity, and a logging advisor, which captures both the request and response to and from the LLM, and outputs them to the application’s log, for effective troubleshooting.
One challenge that often arises when working with generative AI models is that each model has its own set of quirks. For example, asking for a structured response—such as JSON—from a Large Language Model is not as straightforward as it may seem. LLMs are trained to generate conversational text, and often they love to "chat" in a more human-like manner. This can lead to unpredictable or overly verbose outputs, which aren't ideal when you’re expecting a machine-readable format.
Spring AI abstracts away these nuances for you. It automatically handles these variations by appending the appropriate user prompts or instructions depending on the specific LLM in use. So, whether you're working with OpenAI's GPT4-o, Anthropic’s Claude, or a different LLM, Spring AI ensures the response you receive is in the desired structure. This capability eliminates the need for trial-and-error prompt engineering on the developer’s part, allowing you to focus on leveraging AI instead of wrestling with its quirks.
Here’s an example from Spring AI’s BeanOutputConverter implementation, designed to retrieve a response from the LLM in JSON format that adheres to the schema of a given data class. Notice how detailed and specific the prompt to the LLM needs to be to achieve the desired result:
@Override
public String getFormat() {
String template = """
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Do not include markdown code blocks in your response.
Remove the ```json markdown from the output.
Here is the JSON Schema instance your output must adhere to:
```%s```
""";
return String.format(template, this.jsonSchema);
}
Spring AI does the heavy lifting so you don’t have to.
Observability is crucial in any enterprise application, and applications enhanced with generative AI are no exception. Spring AI offers built-in observability features, enabling seamless monitoring of your AI services' health and performance. This includes comprehensive metrics, tracing, and logging for end-to-end visibility into your generative AI application. This is not just for the chat model - it's for the entire stack, including the embedding model and the vector database. This capability highlights once again the power of an integrated solution like Spring, since observability features are enabled by micrometer, just like in other Spring projects:
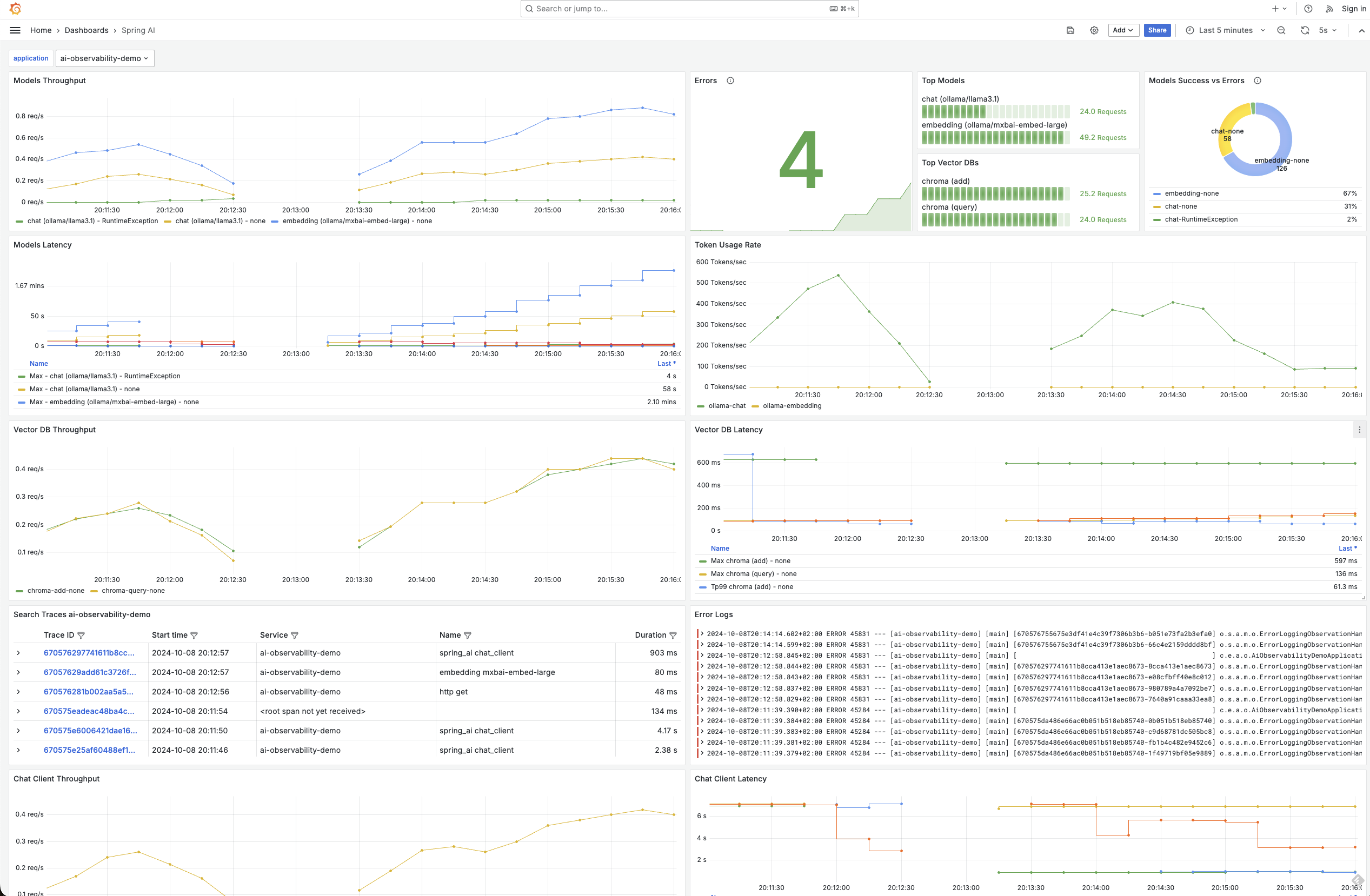
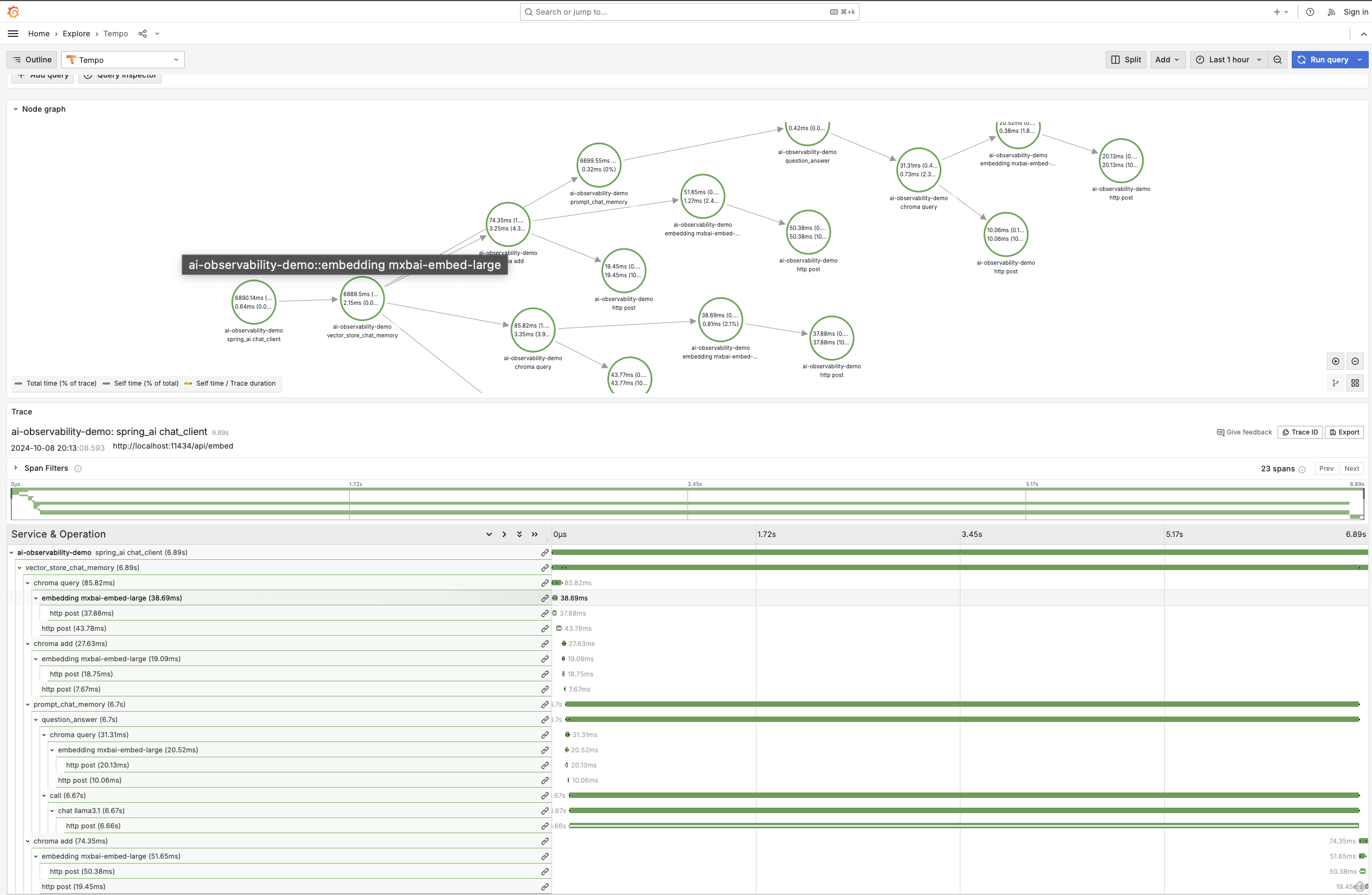
With Spring AI, you gain insights into critical metrics like token usage rate, which is essential for managing cost when interacting with models that charge based on the number of tokens processed. Additionally, you can monitor vector store latency, error rates, and even trace how requests flow through your AI-enhanced services. This level of observability ensures that you can quickly identify performance bottlenecks or potential issues before they impact your application, just like you're accustomed to doing with other Spring-based services.
Another significant advantage of using Spring AI is the ease with which you can conduct A/B testing between different LLM providers. In the quest for the best balance of cost and quality of response, being able to compare multiple models is invaluable.
With Spring AI, you can easily switch between various LLMs simply by replacing the Spring Boot Starter dependency and changing a couple of lines in a property file. This straightforward approach allows you to evaluate the performance of different models without extensive reconfiguration or coding overhead. Whether you're assessing accuracy, response time, or cost-efficiency, Spring AI provides the tools to facilitate these comparisons seamlessly.
By integrating A/B testing directly into your workflow, you can make data-driven decisions about which LLM provider best suits your application's needs. This capability not only enhances the overall effectiveness of your AI implementations but also allows for continuous optimization as new models and capabilities emerge in the generative AI landscape.
Spring AI is purpose-built to provide Java developers with a seamless and efficient way to integrate AI into their applications. It’s not just about adding AI capabilities—it’s about doing so in a way that naturally fits into your existing system. Applying generative AI to applications is primarily an integration challenge, and this is where the Spring framework excels. Spring AI is a natural extension of the Spring ecosystem, designed to handle the complexities of enterprise application integration effortlessly.
If your goal is to enhance enterprise applications with generative models, function calling, and vector embeddings, Spring AI stands as the ideal choice. Its deep integration with the Spring ecosystem, along with access to a broad selection of large language models and vector stores, makes it both powerful and straightforward for AI development. Perfect for incorporating AI alongside existing business logic, it eliminates the complexity of managing multi-step workflows or chaining models.
To recap, some standout advantages of Spring AI are:
Seamless Integration: Embed AI capabilities within existing Spring applications effortlessly.
Built for RAG: Simplifies the process of embedding data and running similarity searches, while supporting powerful metadata filters.
Function Calling: Enable real-time interactions with transactional APIs.
Advisors: Handle cross-cutting concerns with the built-in advisors, or write your own when needed.
Vendor-Agnostic: Utilize various vector stores and LLM providers without being locked into a specific solution, providing flexibility in your data and model management.
A/B Testing: Easily conduct A/B testing to optimize AI performance.
Built-in Observability: Access monitoring, logging and tracing features for greater transparency.
By choosing Spring AI, you empower your enterprise applications with advanced AI capabilities, driving innovation and enhancing user experience.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all