Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreIn a recent research publication: Building effective agents, Anthropic shared valuable insights about building effective Large Language Model (LLM) agents. What makes this research particularly interesting is its emphasis on simplicity and composability over complex frameworks. Let's explore how these principles translate into practical implementations using Spring AI.
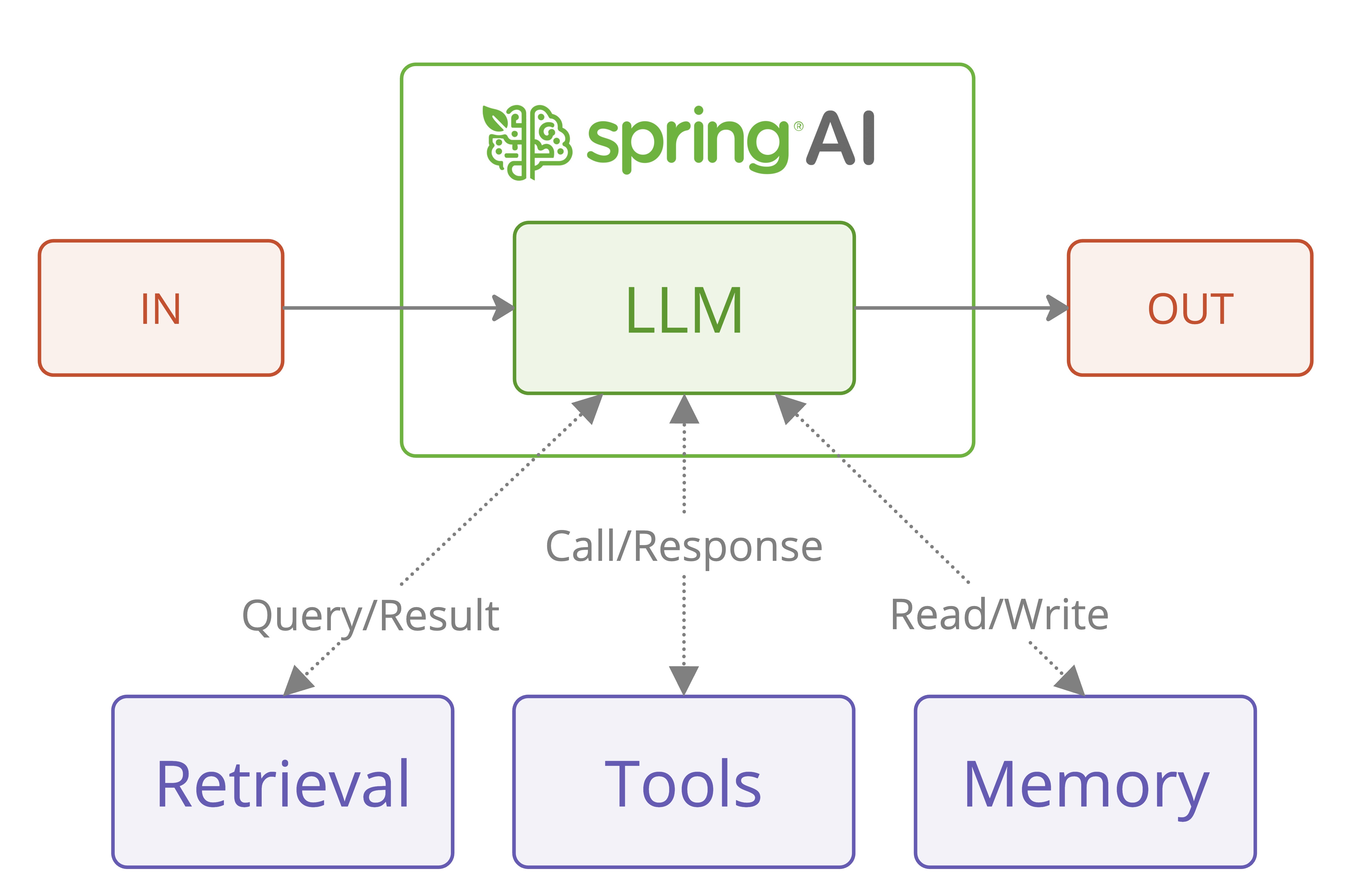
While the pattern descriptions and diagrams are sourced from Anthropic's original publication, we'll focus on how to implement these patterns using Spring AI's features for model portability and structured output. We recommend reading the original paper first.
The agentic-patterns project implements the patterns discussed below.
The research publication makes an important architectural distinction between two types of agentic systems:
The key insight is that while fully autonomous agents might seem appealing, workflows often provide better predictability and consistency for well-defined tasks. This aligns perfectly with enterprise requirements where reliability and maintainability are crucial.
Let's examine how Spring AI implements these concepts through five fundamental patterns, each serving specific use cases:
The Chain Workflow pattern exemplifies the principle of breaking down complex tasks into simpler, more manageable steps.
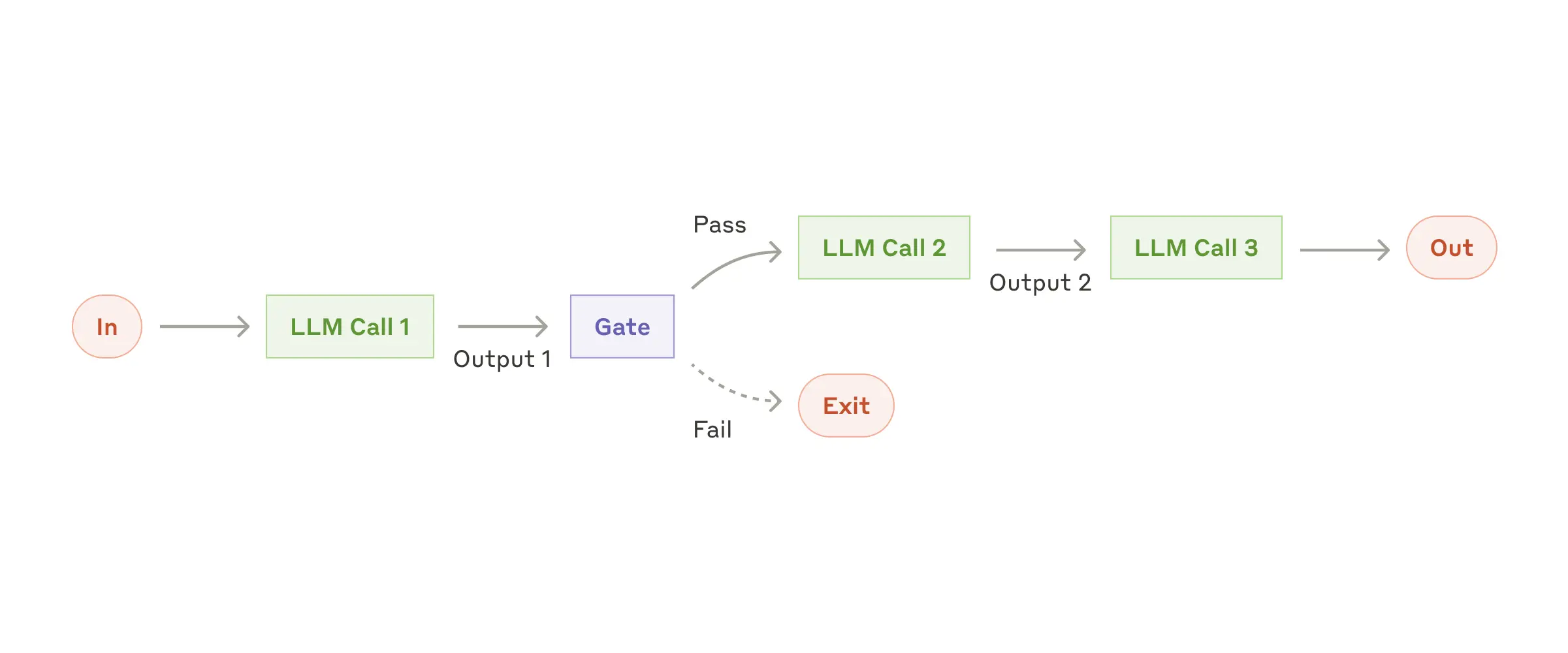
When to Use:
Here's a practical example from Spring AI's implementation:
public class ChainWorkflow {
private final ChatClient chatClient;
private final String[] systemPrompts;
// Processes input through a series of prompts, where each step's output
// becomes input for the next step in the chain.
public String chain(String userInput) {
String response = userInput;
for (String prompt : systemPrompts) {
// Combine the system prompt with previous response
String input = String.format("{%s}\n {%s}", prompt, response);
// Process through the LLM and capture output
response = chatClient.prompt(input).call().content();
}
return response;
}
}
This implementation demonstrates several key principles:
LLMs can work simultaneously on tasks and have their outputs aggregated programmatically. The parallelization workflow manifests in two key variations:
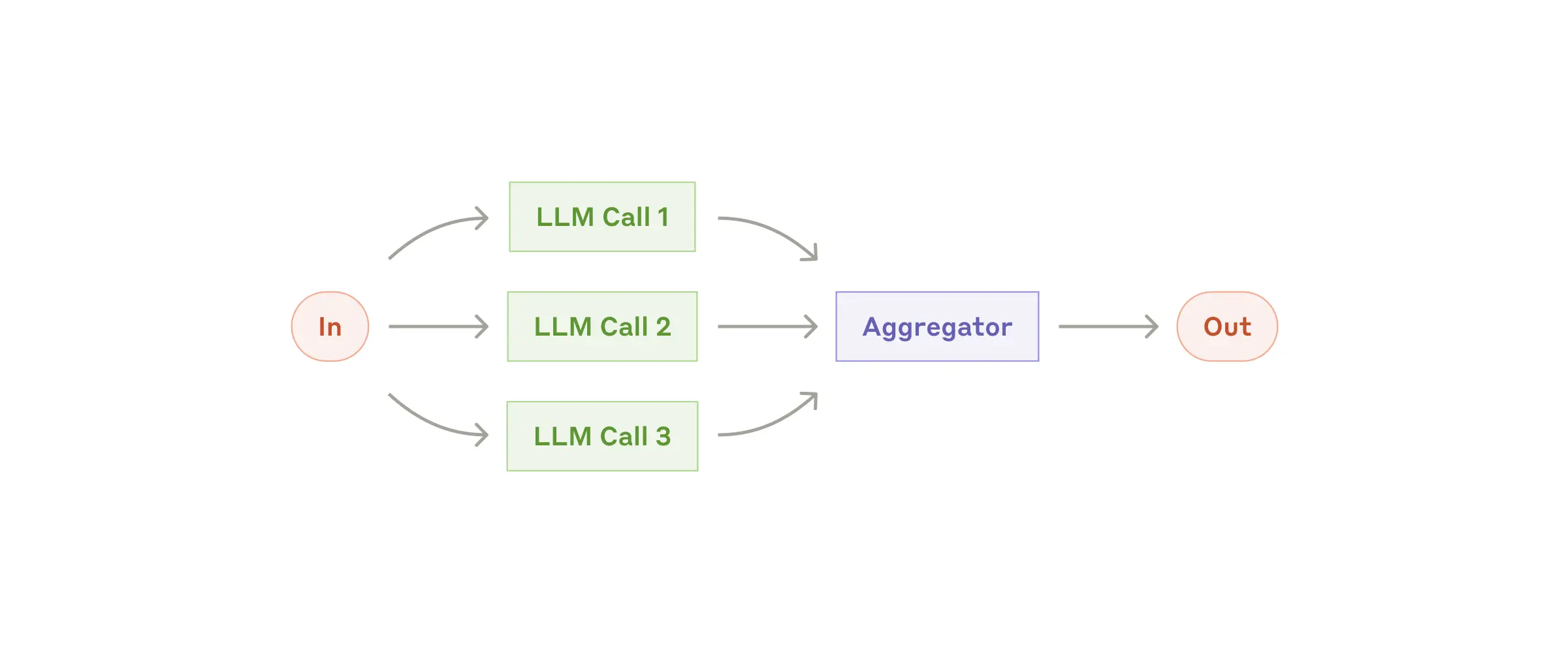
When to Use:
The Parallelization Workflow pattern demonstrates efficient concurrent processing of multiple Large Language Model (LLM) operations. This pattern is particularly useful for scenarios requiring parallel execution of LLM calls with automated output aggregation.
Here's a basic example of using the Parallelization Workflow:
List<String> parallelResponse = new ParallelizationWorkflow(chatClient)
.parallel(
"Analyze how market changes will impact this stakeholder group.",
List.of(
"Customers: ...",
"Employees: ...",
"Investors: ...",
"Suppliers: ..."
),
4
);
This example demonstrates parallel processing of stakeholder analysis, where each stakeholder group is analyzed concurrently.
The Routing pattern implements intelligent task distribution, enabling specialized handling for different types of input.
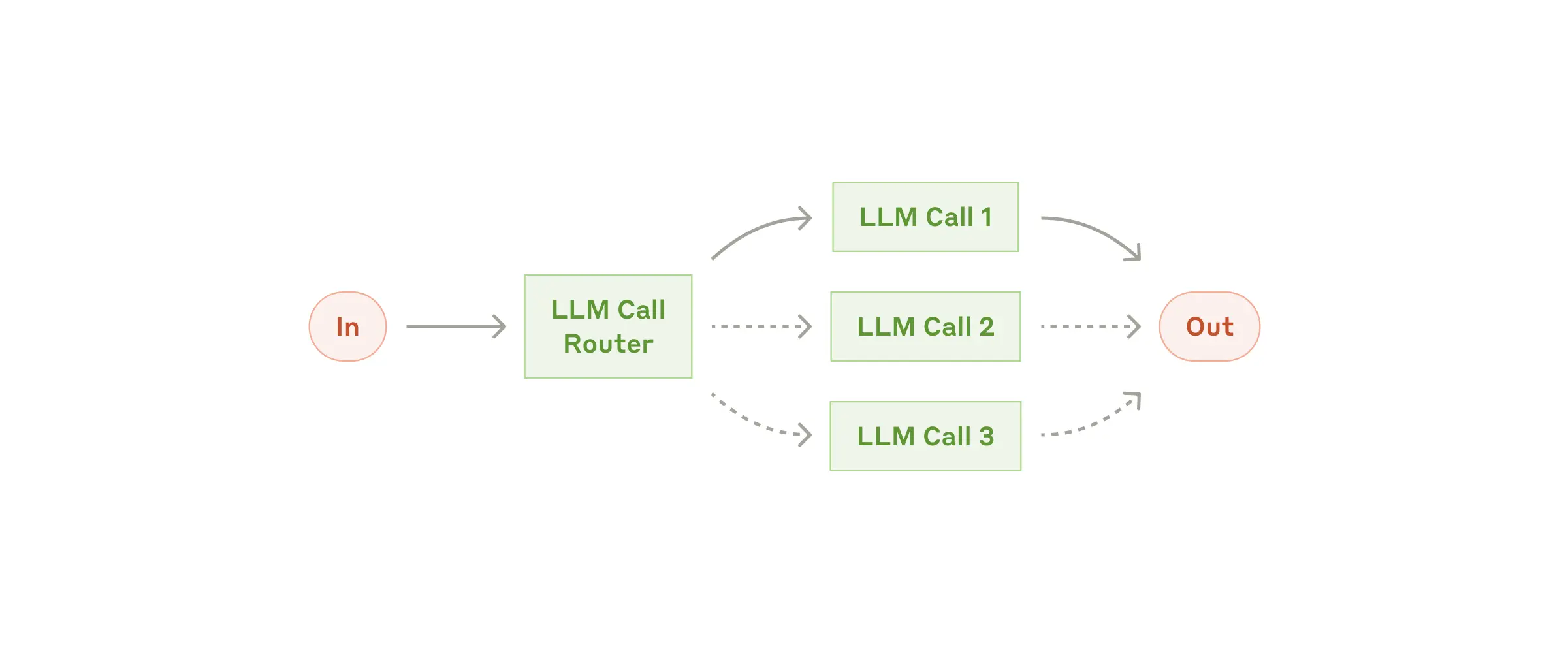
This pattern is designed for complex tasks where different types of inputs are better handled by specialized processes. It uses an LLM to analyze input content and route it to the most appropriate specialized prompt or handler.
When to Use:
Here's a basic example of using the Routing Workflow:
@Autowired
private ChatClient chatClient;
// Create the workflow
RoutingWorkflow workflow = new RoutingWorkflow(chatClient);
// Define specialized prompts for different types of input
Map<String, String> routes = Map.of(
"billing", "You are a billing specialist. Help resolve billing issues...",
"technical", "You are a technical support engineer. Help solve technical problems...",
"general", "You are a customer service representative. Help with general inquiries..."
);
// Process input
String input = "My account was charged twice last week";
String response = workflow.route(input, routes);
This pattern demonstrates how to implement more complex agent-like behavior while maintaining control:
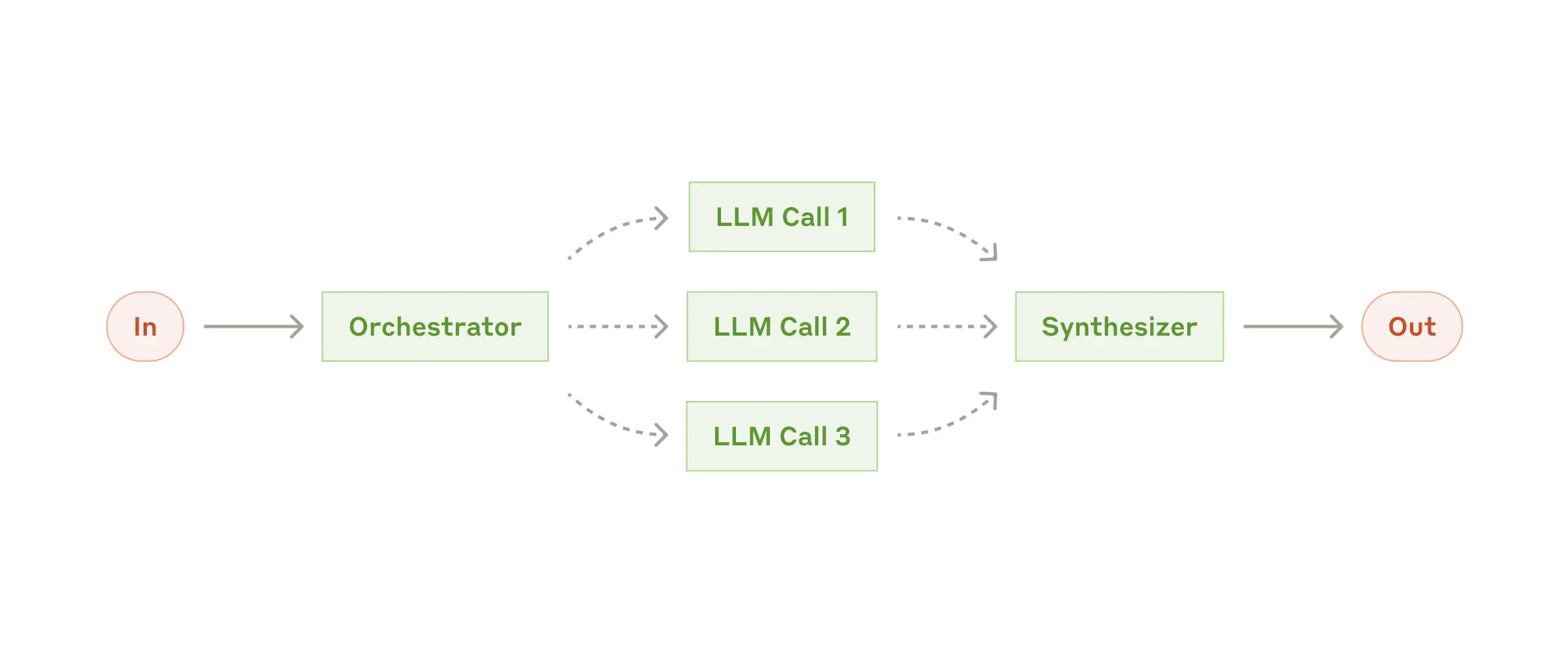
When to Use:
The implementation uses Spring AI's ChatClient for LLM interactions and consists of:
public class OrchestratorWorkersWorkflow {
public WorkerResponse process(String taskDescription) {
// 1. Orchestrator analyzes task and determines subtasks
OrchestratorResponse orchestratorResponse = // ...
// 2. Workers process subtasks in parallel
List<String> workerResponses = // ...
// 3. Results are combined into final response
return new WorkerResponse(/*...*/);
}
}
ChatClient chatClient = // ... initialize chat client
OrchestratorWorkersWorkflow workflow = new OrchestratorWorkersWorkflow(chatClient);
// Process a task
WorkerResponse response = workflow.process(
"Generate both technical and user-friendly documentation for a REST API endpoint"
);
// Access results
System.out.println("Analysis: " + response.analysis());
System.out.println("Worker Outputs: " + response.workerResponses());
The Evaluator-Optimizer pattern implements a dual-LLM process where one model generates responses while another provides evaluation and feedback in an iterative loop, similar to a human writer's refinement process. The pattern consists of two main components:
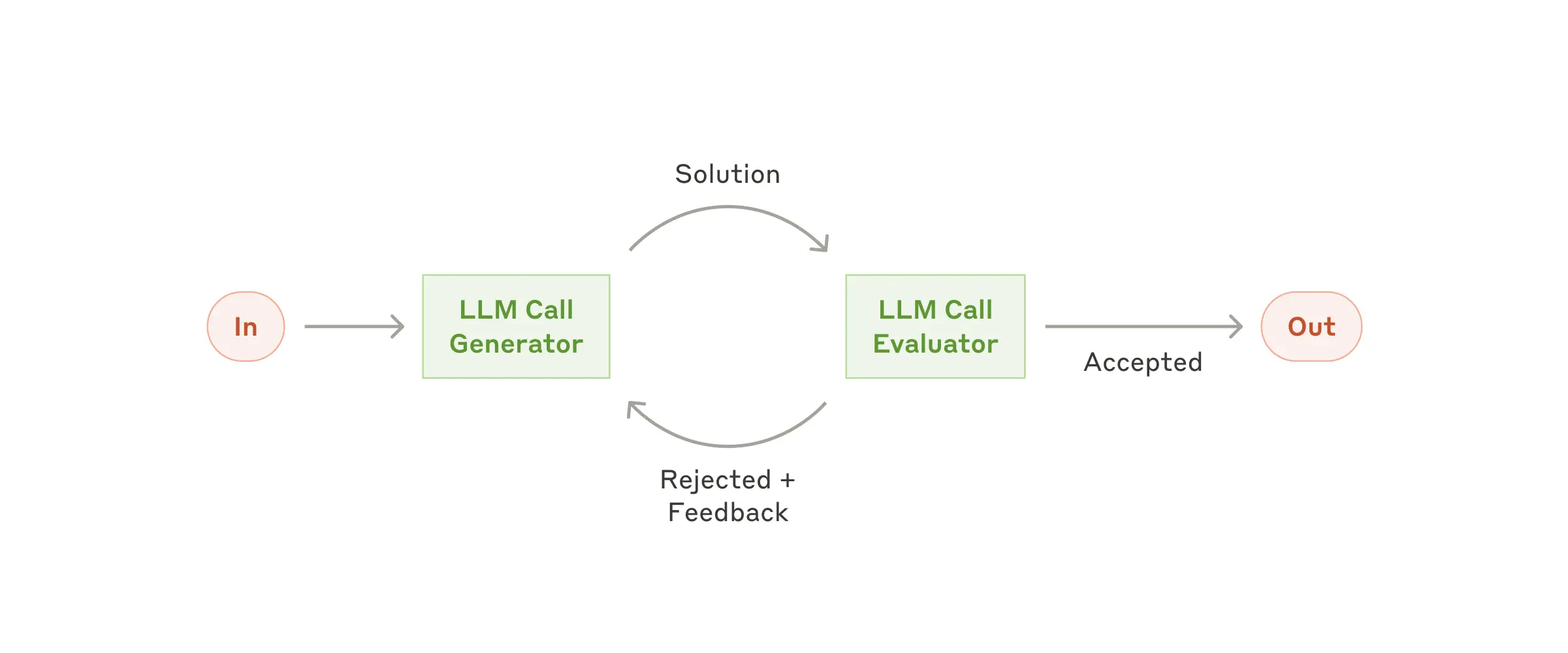
When to Use:
The implementation uses Spring AI's ChatClient for LLM interactions and consists of:
public class EvaluatorOptimizerWorkflow {
public RefinedResponse loop(String task) {
// 1. Generate initial solution
Generation generation = generate(task, context);
// 2. Evaluate the solution
EvaluationResponse evaluation = evaluate(generation.response(), task);
// 3. If PASS, return solution
// 4. If NEEDS_IMPROVEMENT, incorporate feedback and generate new solution
// 5. Repeat until satisfactory
return new RefinedResponse(finalSolution, chainOfThought);
}
}
ChatClient chatClient = // ... initialize chat client
EvaluatorOptimizerWorkflow workflow = new EvaluatorOptimizerWorkflow(chatClient);
// Process a task
RefinedResponse response = workflow.loop(
"Create a Java class implementing a thread-safe counter"
);
// Access results
System.out.println("Final Solution: " + response.solution());
System.out.println("Evolution: " + response.chainOfThought());
Spring AI's implementation of these patterns offers several benefits that align with Anthropic's recommendations:
<!-- Easy model switching through dependencies -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
// Type-safe handling of LLM responses
EvaluationResponse response = chatClient.prompt(prompt)
.call()
.entity(EvaluationResponse.class);
Based on both Anthropic's research and Spring AI's implementations, here are key recommendations for building effective LLM-based systems:
Start Simple
Design for Reliability
Consider Trade-offs
In Part 2 of this series, we'll explore how to build more advanced Agents that combine these foundational patterns with sophisticated features:
Pattern Composition
Advanced Agent Memory Management
Tools and Model-Context Protocol (MCP) Integration
Stay tuned for detailed implementations and best practices for these advanced features.
VMware Tanzu Platform 10 Tanzu AI Server, powered by Spring AI provides:
For more information about deploying AI applications with Tanzu AI Server, visit the VMware Tanzu AI documentation.
The combination of Anthropic's research insights and Spring AI's practical implementations provides a powerful framework for building effective LLM-based systems. By following these patterns and principles, developers can create robust, maintainable, and effective AI applications that deliver real value while avoiding unnecessary complexity.
The key is to remember that sometimes the simplest solution is the most effective. Start with basic patterns, understand your use case thoroughly, and only add complexity when it demonstrably improves your system's performance or capabilities.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all