Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThe initial introduction of the null safety support in Spring dates back to 2017 and the release of Spring Framework 5.0. In 2025, we are evolving that story to bring more added value for Spring developers, either in Java or Kotlin. But before having a deeper look to the changes we are working on, let me explain why we do that and what are the expected benefits.
Let's take a concrete example, and say we are using a library that provides a TokenExtractor interface defined as follow:
interface TokenExtractor {
/**
* Extract a token from a {@link String}.
* @param input the input to process
* @return the extracted token
*/
String extractToken(String input);
}
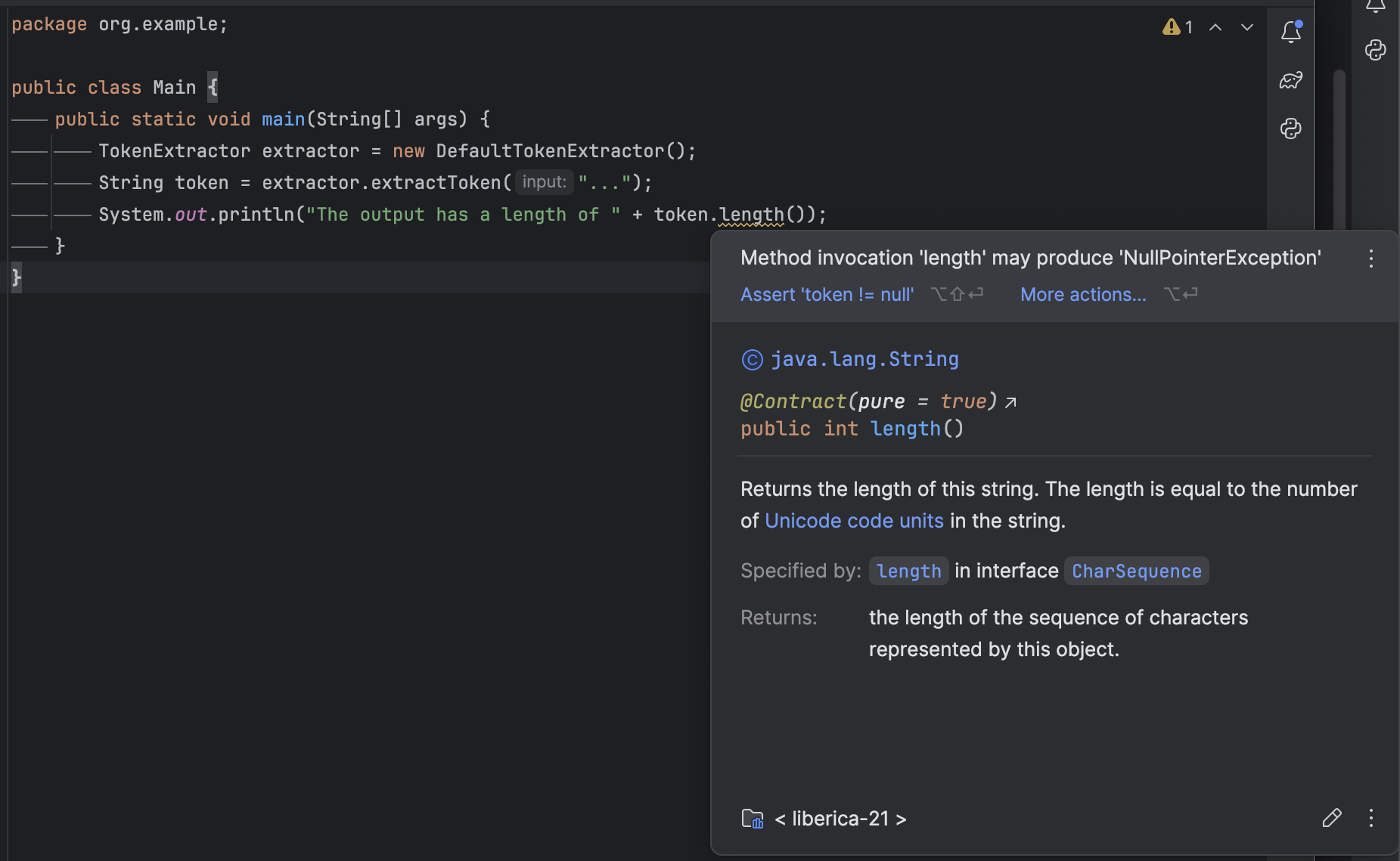
If for some reason the implementation returns null, the access to a null reference in token.length() like below causes a NullPointerException which typically ends up at runtime in producing an HTTP response with a 500 Internal Server Error status code.
package com.example;
String token = extractor.extractToken("...");
System.out.println("The token has a length of " + token.length());
Since this error could happen only in some cases (for example with very specific inputs that have not been tested), this can be detected pretty late in production, generating end-user frustration or even preventing transactions to happen, reducing your company revenue, damaging your brand and involving latency and cost to fix.
This kind of error is so frequent that the inventor of null references himself, Tony Hoare, hyperbolically apologized for inventing it and called it "my billion-dollar mistake". But as brilliantly demonstrated by Kotlin, the root issue is not null references by themselves, but the fact that they are not explicitly specified in the type system.
In Java, non primitive type usage nullness is unspecified. A parameter may accept or not a null argument. A return value could be nullable or non-null. You don't know and have to rely on reading the Javadoc or analyzing the implementation to figure out. But even if the library author document it, it is usually not consistent across all the APIs, there are usually no automated checks and you can't really know if a parameter/return value is really non-null or if the library author just forgot to document it is nullable. This is by design error prone, and you have no proper way to fix this issue.
The solution to this insidious problem is to make the nullness of type usages explicit for all APIs, and to have related automatic checks for consistency in our IDE and our builds. Since Java does not provide null-restricted and nullable types yet, we need a way to specify the nullness of Spring APIs.
In 2017, we chose to introduce Spring nullability annotations, which were built on top of JSR 305 (a dormant but widespread JSR) semantics and annotations. It was far from perfect due to technical limitations, unclear status, lack of proper specification, but it was the best pragmatic choice we identified at that point. The Spring team then joined a working group led by Google bringing together several companies invested in the JVM ecosystem like JetBrains, Oracle, Uber, VMware/Broadcom and others in order to design and contribute a better solution not tied to a specific verification tool. This was the beginning of JSpecify.
A misunderstanding I observe frequently about nullness is that at first, you may have the feeling it is mainly about choosing one of the numerous @Nullable variants, but it is just the small visible part of the iceberg. Those annotations need to come with a proper specification, tooling support, etc. Agreeing on a common nullness specification in a collaborative way is the reason why it took multiple years for JSpecify to reach 1.0.
JSpecify is a set of annotations, specifications and documentation designed to ensure the null safety of Java applications and libraries in the IDE or during the compilation thanks to tools like NullAway.
A key point to understand is that by default, the nullness of type usages is unspecified in Java, and that non-null type usages are by far more frequent than nullable ones. In order to keep codebases readable, we typically want to define that by default, on a specific scope, type usages are non-null unless marked as nullable. This is exactly the purpose of @NullMarked that is typically set at package level via a package-info.java file, for example:
@NullMarked
package org.example;
import org.jspecify.annotations.NullMarked;
This annotation changes the default nullness for type usages from "unspecified" (Java default) to "non-null" (JSpecify @NullMarked default). So we can now refine our API and documentation accordingly.
package org.example;
interface TokenExtractor {
/**
* Extract a token from a {@link String}.
* @param input the input to process
* @return the extracted token or {@code null} if not found
*/
@Nullable String extractToken(String input);
}
The IDE now properly warns us of a potential NullPointerException when invoking a method on the return value, and would also complain if we were passing a null argument since this null-marked code default is non-null.
While we could ignore or miss those IDE warnings, the consistency of the nullness annotations across the codebase can be checked at build time with NullAway configured to throw errors. If an inconsistency is found, the build breaks, preventing by design to ship null unsafe APIs (except for non annotated types coming from third-party dependencies).
> Task :compileJava FAILED
/Users/sdeleuze/workspace/jspecify-nullway-demo/src/main/java/org/example/Main.java:7: error: [NullAway] dereferenced expression token is @Nullable
System.out.println("The token has a length of " + token.length());
^
(see http://t.uber.com/nullaway )
1 error
See https://github.com/sdeleuze/jspecify-nullway-demo if you want to try it by yourself or to see an example of a related Gradle build.
Those nullness errors enforce that the developer using those APIs handles the null references explicitly:
String token = extractor.extractToken("...");
if (token == null) {
System.out.println("No token found");
}
else {
System.out.println("The token has a length of " + token.length());
}
You may object that java Optional<T> has been designed to express the presence or absence of value. But in practice, Optional<T> is not usable in a lot of use cases because it introduces a runtime overhead (at least until Project Valhalla value classes are available), it increases the code and API complexity, it is not a good fit for parameters and it breaks existing API signatures.
Spring Framework 7 (currently in milestone phase) has already switched to JSpecify its whole codebase. You can find related documentation here. A key improvement compared to the previous incarnation is that the nullness is now also specified for arrays/varargs elements, as well as generic types. That's great for Java developers, but also for Kotlin ones who will see idiomatic null-safe APIs like if Spring was written in Kotlin.
But the biggest improvement is that the whole Spring team currently works on tentatively provide null-safe APIs across the whole Spring portfolio with related build-time checks to ensure consistency. This is an ongoing process, and no promise yet we will be able to complete it when Spring Boot 4.0 will be released in November, but we try to come as close as possible of a complete coverage. Project Reactor and Micrometer are also in the scope.
When Spring Boot 4 will be released and used in your applications, especially if you enable those nullness checks at application level as well, the risk of NullPointerException on production will be very significantly reduced if not removed, as it will only be possible for types coming from 3rd party libraries. By specifying where null references may happen explicitly, handling those code paths, and introducing related automatic checks, we turn "the billion dollar mistake" into a zero cost abstraction allowing to express the potential absence of value, increasing significantly the safety of Spring applications.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all