Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThis blog post demonstrates practical implementations of Prompt Engineering techniques using Spring AI.

The examples and patterns in this article are based on the comprehensive Prompt Engineering Guide that covers the theory, principles, and patterns of effective prompt engineering.
The blog shows how to translate those concepts into working Java code using Spring AI's fluent ChatClient API.
For convenience, the examples are structured to follow the same patterns and techniques outlined in the original guide.
The demo source code used in this article is available at: https://github.com/spring-projects/spring-ai-examples/tree/main/prompt-engineering/prompt-engineering-patterns
The configuration section outlines how to set up and tune your Large Language Model (LLM) with Spring AI. It covers selecting the right LLM provider for your use case and configuring important generation parameters that control the quality, style, and format of model outputs.
For prompt engineering, you will start by choosing a model.
Spring AI supports multiple LLM providers (such as OpenAI, Anthropic, Google Vertex AI, AWS Bedrock, Ollama, and more), letting you switch providers without changing application code—just update your configuration.
Just add the selected starter dependency spring-ai-starter-model-<MODEL-PROVIDER-NAME>.
For example, here is how to enable Anthropic Claude API:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-anthropic</artifactId>
</dependency>
along with some connection properties:
spring.ai.anthropic.api-key=${ANTHROPIC_API_KEY}
You can specify a particular LLM model name like this:
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest") // Use Anthropic's Claude model
.build())
Find detailed information for enabling and configuring the preferred AI model in the reference docs.
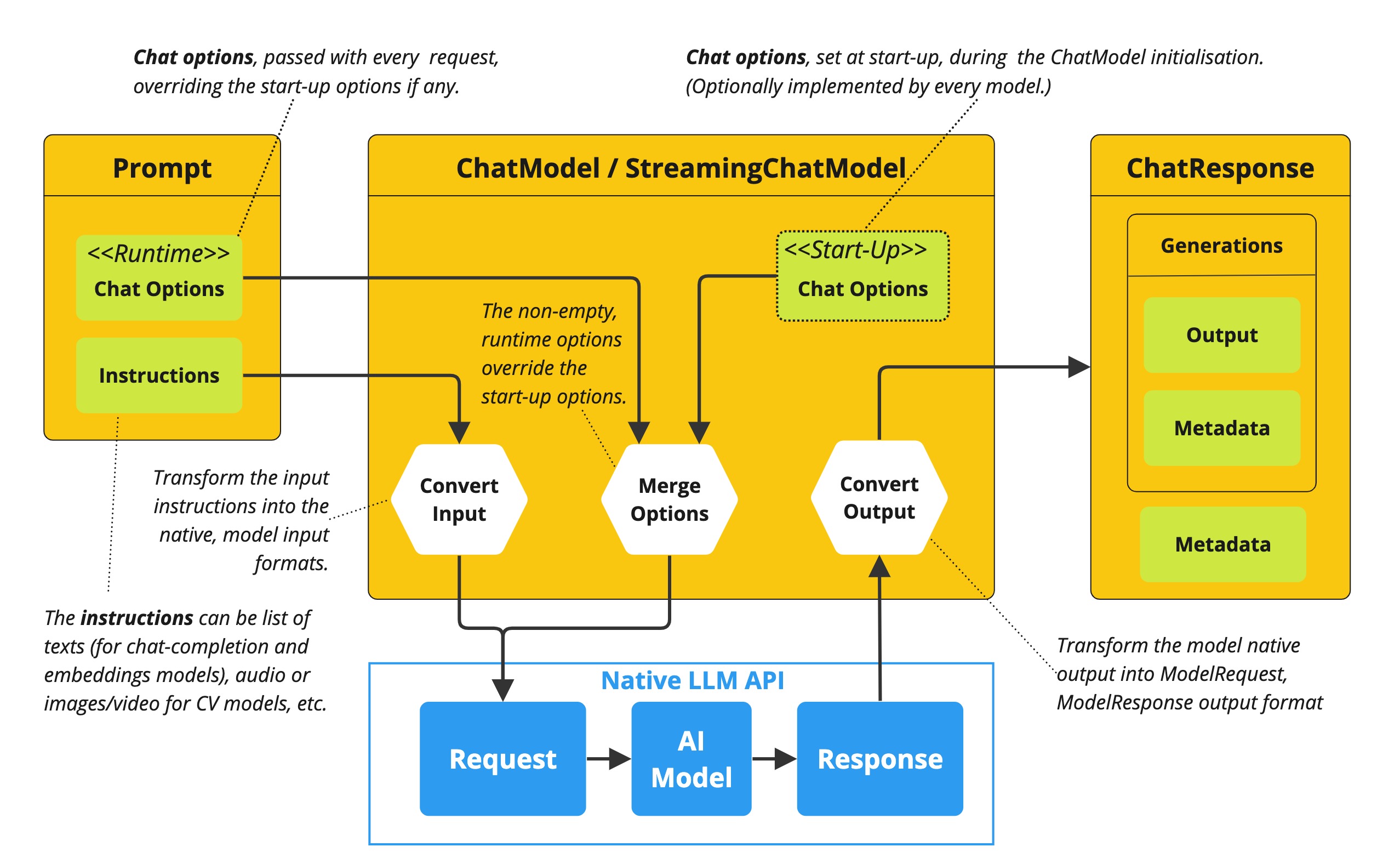
Before we dive into prompt engineering techniques, it's essential to understand how to configure the LLM's output behavior. Spring AI provides several configuration options that let you control various aspects of generation through the ChatOptions builder.
All configurations can be applied programmatically as demonstrated in the examples below or through Spring application properties at start time.
Temperature controls the randomness or "creativity" of the model's response.
.options(ChatOptions.builder()
.temperature(0.1) // Very deterministic output
.build())
Understanding temperature is crucial for prompt engineering as different techniques benefit from different temperature settings.
The maxTokens parameter limits how many tokens (word pieces) the model can generate in its response.
.options(ChatOptions.builder()
.maxTokens(250) // Medium-length response
.build())
Setting appropriate output length is important to ensure you get complete responses without unnecessary verbosity.
These parameters give you fine-grained control over the token selection process during generation.
.options(ChatOptions.builder()
.topK(40) // Consider only the top 40 tokens
.topP(0.8) // Sample from tokens that cover 80% of probability mass
.build())
These sampling controls work in conjunction with temperature to shape response characteristics.
Along with the plain text response (using .content()), Spring AI makes it easy to directly map LLM responses to Java objects using the .entity() method.
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment result = chatClient.prompt("...")
.call()
.entity(Sentiment.class);
This feature is particularly powerful when combined with system prompts that instruct the model to return structured data.
While the portable ChatOptions provides a consistent interface across different LLM providers, Spring AI also offers model-specific options classes that expose provider-specific features and configurations. These model-specific options allow you to leverage the unique capabilities of each LLM provider.
// Using OpenAI-specific options
OpenAiChatOptions openAiOptions = OpenAiChatOptions.builder()
.model("gpt-4o")
.temperature(0.2)
.frequencyPenalty(0.5) // OpenAI-specific parameter
.presencePenalty(0.3) // OpenAI-specific parameter
.responseFormat(new ResponseFormat("json_object")) // OpenAI-specific JSON mode
.seed(42) // OpenAI-specific deterministic generation
.build();
String result = chatClient.prompt("...")
.options(openAiOptions)
.call()
.content();
// Using Anthropic-specific options
AnthropicChatOptions anthropicOptions = AnthropicChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.2)
.topK(40) // Anthropic-specific parameter
.thinking(AnthropicApi.ThinkingType.ENABLED, 1000) // Anthropic-specific thinking configuration
.build();
String result = chatClient.prompt("...")
.options(anthropicOptions)
.call()
.content();
Each model provider has its own implementation of chat options (e.g., OpenAiChatOptions, AnthropicChatOptions, MistralAiChatOptions) that exposes provider-specific parameters while still implementing the common interface. This approach gives you the flexibility to use portable options for cross-provider compatibility or model-specific options when you need access to unique features of a particular provider.
Note that when using model-specific options, your code becomes tied to that specific provider, reducing portability. It's a trade-off between accessing advanced provider-specific features versus maintaining provider independence in your application.
Each section below implements a specific prompt engineering technique from the guide. By following both the "Prompt Engineering" guide and these implementations, you'll develop a thorough understanding of not just what prompt engineering techniques are available, but how to effectively implement them in production Java applications.
Zero-shot prompting involves asking an AI to perform a task without providing any examples. This approach tests the model's ability to understand and execute instructions from scratch. Large language models are trained on vast corpora of text, allowing them to understand what tasks like "translation," "summarization," or "classification" entail without explicit demonstrations.
Zero-shot is ideal for straightforward tasks where the model likely has seen similar examples during training, and when you want to minimize prompt length. However, performance may vary depending on task complexity and how well the instructions are formulated.
// Implementation of Section 2.1: General prompting / zero shot (page 15)
public void pt_zero_shot(ChatClient chatClient) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment reviewSentiment = chatClient.prompt("""
Classify movie reviews as POSITIVE, NEUTRAL or NEGATIVE.
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. I wish there were more movies like this masterpiece.
Sentiment:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(5)
.build())
.call()
.entity(Sentiment.class);
System.out.println("Output: " + reviewSentiment);
}
This example shows how to classify a movie review sentiment without providing examples. Note the low temperature (0.1) for more deterministic results and the direct .entity(Sentiment.class) mapping to a Java enum.
Reference: Brown, T. B., et al. (2020). "Language Models are Few-Shot Learners." arXiv:2005.14165. https://arxiv.org/abs/2005.14165
Few-shot prompting provides the model with one or more examples to help guide its responses, particularly useful for tasks requiring specific output formats. By showing the model examples of desired input-output pairs, it can learn the pattern and apply it to new inputs without explicit parameter updates.
One-shot provides a single example, which is useful when examples are costly or when the pattern is relatively simple. Few-shot uses multiple examples (typically 3-5) to help the model better understand patterns in more complex tasks or to illustrate different variations of correct outputs.
// Implementation of Section 2.2: One-shot & few-shot (page 16)
public void pt_ones_shot_few_shots(ChatClient chatClient) {
String pizzaOrder = chatClient.prompt("""
Parse a customer's pizza order into valid JSON
EXAMPLE 1:
I want a small pizza with cheese, tomato sauce, and pepperoni.
JSON Response:
```
{
"size": "small",
"type": "normal",
"ingredients": ["cheese", "tomato sauce", "pepperoni"]
}
```
EXAMPLE 2:
Can I get a large pizza with tomato sauce, basil and mozzarella.
JSON Response:
```
{
"size": "large",
"type": "normal",
"ingredients": ["tomato sauce", "basil", "mozzarella"]
}
```
Now, I would like a large pizza, with the first half cheese and mozzarella.
And the other tomato sauce, ham and pineapple.
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(250)
.build())
.call()
.content();
}
Few-shot prompting is especially effective for tasks requiring specific formatting, handling edge cases, or when the task definition might be ambiguous without examples. The quality and diversity of the examples significantly impact performance.
Reference: Brown, T. B., et al. (2020). "Language Models are Few-Shot Learners." arXiv:2005.14165. https://arxiv.org/abs/2005.14165
System prompting sets the overall context and purpose for the language model, defining the "big picture" of what the model should be doing. It establishes the behavioral framework, constraints, and high-level objectives for the model's responses, separate from the specific user queries.
System prompts act as a persistent "mission statement" throughout the conversation, allowing you to set global parameters like output format, tone, ethical boundaries, or role definitions. Unlike user prompts which focus on specific tasks, system prompts frame how all user prompts should be interpreted.
// Implementation of Section 2.3.1: System prompting
public void pt_system_prompting_1(ChatClient chatClient) {
String movieReview = chatClient
.prompt()
.system("Classify movie reviews as positive, neutral or negative. Only return the label in uppercase.")
.user("""
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. It's so disturbing I couldn't watch it.
Sentiment:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(1.0)
.topK(40)
.topP(0.8)
.maxTokens(5)
.build())
.call()
.content();
}
System prompting is particularly powerful when combined with Spring AI's entity mapping capabilities:
// Implementation of Section 2.3.1: System prompting with JSON output
record MovieReviews(Movie[] movie_reviews) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
record Movie(Sentiment sentiment, String name) {
}
}
MovieReviews movieReviews = chatClient
.prompt()
.system("""
Classify movie reviews as positive, neutral or negative. Return
valid JSON.
""")
.user("""
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. It's so disturbing I couldn't watch it.
JSON Response:
""")
.call()
.entity(MovieReviews.class);
System prompts are especially valuable for multi-turn conversations, ensuring consistent behavior across multiple queries, and for establishing format constraints like JSON output that should apply to all responses.
Reference: OpenAI. (2022). "System Message." https://platform.openai.com/docs/guides/chat/introduction
Role prompting instructs the model to adopt a specific role or persona, which affects how it generates content. By assigning a particular identity, expertise, or perspective to the model, you can influence the style, tone, depth, and framing of its responses.
Role prompting leverages the model's ability to simulate different expertise domains and communication styles. Common roles include expert (e.g., "You are an experienced data scientist"), professional (e.g., "Act as a travel guide"), or stylistic character (e.g., "Explain like you're Shakespeare").
// Implementation of Section 2.3.2: Role prompting
public void pt_role_prompting_1(ChatClient chatClient) {
String travelSuggestions = chatClient
.prompt()
.system("""
I want you to act as a travel guide. I will write to you
about my location and you will suggest 3 places to visit near
me. In some cases, I will also give you the type of places I
will visit.
""")
.user("""
My suggestion: "I am in Amsterdam and I want to visit only museums."
Travel Suggestions:
""")
.call()
.content();
}
Role prompting can be enhanced with style instructions:
// Implementation of Section 2.3.2: Role prompting with style instructions
public void pt_role_prompting_2(ChatClient chatClient) {
String humorousTravelSuggestions = chatClient
.prompt()
.system("""
I want you to act as a travel guide. I will write to you about
my location and you will suggest 3 places to visit near me in
a humorous style.
""")
.user("""
My suggestion: "I am in Amsterdam and I want to visit only museums."
Travel Suggestions:
""")
.call()
.content();
}
This technique is particularly effective for specialized domain knowledge, achieving a consistent tone across responses, and creating more engaging, personalized interactions with users.
Reference: Shanahan, M., et al. (2023). "Role-Play with Large Language Models." arXiv:2305.16367. https://arxiv.org/abs/2305.16367
Contextual prompting provides additional background information to the model by passing context parameters. This technique enriches the model's understanding of the specific situation, enabling more relevant and tailored responses without cluttering the main instruction.
By supplying contextual information, you help the model understand the specific domain, audience, constraints, or background facts relevant to the current query. This leads to more accurate, relevant, and appropriately framed responses.
// Implementation of Section 2.3.3: Contextual prompting
public void pt_contextual_prompting(ChatClient chatClient) {
String articleSuggestions = chatClient
.prompt()
.user(u -> u.text("""
Suggest 3 topics to write an article about with a few lines of
description of what this article should contain.
Context: {context}
""")
.param("context", "You are writing for a blog about retro 80's arcade video games."))
.call()
.content();
}
Spring AI makes contextual prompting clean with the param() method to inject context variables. This technique is particularly valuable when the model needs specific domain knowledge, when adapting responses to particular audiences or scenarios, and for ensuring responses are aligned with particular constraints or requirements.
Reference: Liu, P., et al. (2021). "What Makes Good In-Context Examples for GPT-3?" arXiv:2101.06804. https://arxiv.org/abs/2101.06804
Step-back prompting breaks complex requests into simpler steps by first acquiring background knowledge. This technique encourages the model to first "step back" from the immediate question to consider the broader context, fundamental principles, or general knowledge relevant to the problem before addressing the specific query.
By decomposing complex problems into more manageable components and establishing foundational knowledge first, the model can provide more accurate responses to difficult questions.
// Implementation of Section 2.4: Step-back prompting
public void pt_step_back_prompting(ChatClient.Builder chatClientBuilder) {
// Set common options for the chat client
var chatClient = chatClientBuilder
.defaultOptions(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(1.0)
.topK(40)
.topP(0.8)
.maxTokens(1024)
.build())
.build();
// First get high-level concepts
String stepBack = chatClient
.prompt("""
Based on popular first-person shooter action games, what are
5 fictional key settings that contribute to a challenging and
engaging level storyline in a first-person shooter video game?
""")
.call()
.content();
// Then use those concepts in the main task
String story = chatClient
.prompt()
.user(u -> u.text("""
Write a one paragraph storyline for a new level of a first-
person shooter video game that is challenging and engaging.
Context: {step-back}
""")
.param("step-back", stepBack))
.call()
.content();
}
Step-back prompting is particularly effective for complex reasoning tasks, problems requiring specialized domain knowledge, and when you want more comprehensive and thoughtful responses rather than immediate answers.
Reference: Zheng, Z., et al. (2023). "Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models." arXiv:2310.06117. https://arxiv.org/abs/2310.06117
Chain of Thought prompting encourages the model to reason step-by-step through a problem, which improves accuracy for complex reasoning tasks. By explicitly asking the model to show its work or think through a problem in logical steps, you can dramatically improve performance on tasks requiring multi-step reasoning.
CoT works by encouraging the model to generate intermediate reasoning steps before producing a final answer, similar to how humans solve complex problems. This makes the model's thinking process explicit and helps it arrive at more accurate conclusions.
// Implementation of Section 2.5: Chain of Thought (CoT) - Zero-shot approach
public void pt_chain_of_thought_zero_shot(ChatClient chatClient) {
String output = chatClient
.prompt("""
When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner?
Let's think step by step.
""")
.call()
.content();
}
// Implementation of Section 2.5: Chain of Thought (CoT) - Few-shot approach
public void pt_chain_of_thought_singleshot_fewshots(ChatClient chatClient) {
String output = chatClient
.prompt("""
Q: When my brother was 2 years old, I was double his age. Now
I am 40 years old. How old is my brother? Let's think step
by step.
A: When my brother was 2 years, I was 2 * 2 = 4 years old.
That's an age difference of 2 years and I am older. Now I am 40
years old, so my brother is 40 - 2 = 38 years old. The answer
is 38.
Q: When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step
by step.
A:
""")
.call()
.content();
}
The key phrase "Let's think step by step" triggers the model to show its reasoning process. CoT is especially valuable for mathematical problems, logical reasoning tasks, and any question requiring multi-step reasoning. It helps reduce errors by making intermediate reasoning explicit.
Reference: Wei, J., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." arXiv:2201.11903. https://arxiv.org/abs/2201.11903
Self-consistency involves running the model multiple times and aggregating results for more reliable answers. This technique addresses the variability in LLM outputs by sampling diverse reasoning paths for the same problem and selecting the most consistent answer through majority voting.
By generating multiple reasoning paths with different temperature or sampling settings, then aggregating the final answers, self-consistency improves accuracy on complex reasoning tasks. It's essentially an ensemble method for LLM outputs.
// Implementation of Section 2.6: Self-consistency
public void pt_self_consistency(ChatClient chatClient) {
String email = """
Hi,
I have seen you use Wordpress for your website. A great open
source content management system. I have used it in the past
too. It comes with lots of great user plugins. And it's pretty
easy to set up.
I did notice a bug in the contact form, which happens when
you select the name field. See the attached screenshot of me
entering text in the name field. Notice the JavaScript alert
box that I inv0k3d.
But for the rest it's a great website. I enjoy reading it. Feel
free to leave the bug in the website, because it gives me more
interesting things to read.
Cheers,
Harry the Hacker.
""";
record EmailClassification(Classification classification, String reasoning) {
enum Classification {
IMPORTANT, NOT_IMPORTANT
}
}
int importantCount = 0;
int notImportantCount = 0;
// Run the model 5 times with the same input
for (int i = 0; i < 5; i++) {
EmailClassification output = chatClient
.prompt()
.user(u -> u.text("""
Email: {email}
Classify the above email as IMPORTANT or NOT IMPORTANT. Let's
think step by step and explain why.
""")
.param("email", email))
.options(ChatOptions.builder()
.temperature(1.0) // Higher temperature for more variation
.build())
.call()
.entity(EmailClassification.class);
// Count results
if (output.classification() == EmailClassification.Classification.IMPORTANT) {
importantCount++;
} else {
notImportantCount++;
}
}
// Determine the final classification by majority vote
String finalClassification = importantCount > notImportantCount ?
"IMPORTANT" : "NOT IMPORTANT";
}
Self-consistency is particularly valuable for high-stakes decisions, complex reasoning tasks, and when you need more confident answers than a single response can provide. The trade-off is increased computational cost and latency due to multiple API calls.
Reference: Wang, X., et al. (2022). "Self-Consistency Improves Chain of Thought Reasoning in Language Models." arXiv:2203.11171. https://arxiv.org/abs/2203.11171
Tree of Thoughts (ToT) is an advanced reasoning framework that extends Chain of Thought by exploring multiple reasoning paths simultaneously. It treats problem-solving as a search process where the model generates different intermediate steps, evaluates their promise, and explores the most promising paths.
This technique is particularly powerful for complex problems with multiple possible approaches or when the solution requires exploring various alternatives before finding the optimal path.
NOTE: The original "Prompt Engineering" guide doesn't provide implementation examples for ToT, likely due to its complexity. Below is a simplified example that demonstrates the core concept.
Game Solving ToT Example:
// Implementation of Section 2.7: Tree of Thoughts (ToT) - Game solving example
public void pt_tree_of_thoughts_game(ChatClient chatClient) {
// Step 1: Generate multiple initial moves
String initialMoves = chatClient
.prompt("""
You are playing a game of chess. The board is in the starting position.
Generate 3 different possible opening moves. For each move:
1. Describe the move in algebraic notation
2. Explain the strategic thinking behind this move
3. Rate the move's strength from 1-10
""")
.options(ChatOptions.builder()
.temperature(0.7)
.build())
.call()
.content();
// Step 2: Evaluate and select the most promising move
String bestMove = chatClient
.prompt()
.user(u -> u.text("""
Analyze these opening moves and select the strongest one:
{moves}
Explain your reasoning step by step, considering:
1. Position control
2. Development potential
3. Long-term strategic advantage
Then select the single best move.
""").param("moves", initialMoves))
.call()
.content();
// Step 3: Explore future game states from the best move
String gameProjection = chatClient
.prompt()
.user(u -> u.text("""
Based on this selected opening move:
{best_move}
Project the next 3 moves for both players. For each potential branch:
1. Describe the move and counter-move
2. Evaluate the resulting position
3. Identify the most promising continuation
Finally, determine the most advantageous sequence of moves.
""").param("best_move", bestMove))
.call()
.content();
}
Reference: Yao, S., et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv:2305.10601. https://arxiv.org/abs/2305.10601
Automatic Prompt Engineering uses the AI to generate and evaluate alternative prompts. This meta-technique leverages the language model itself to create, refine, and benchmark different prompt variations to find optimal formulations for specific tasks.
By systematically generating and evaluating prompt variations, APE can find more effective prompts than manual engineering, especially for complex tasks. It's a way of using AI to improve its own performance.
// Implementation of Section 2.8: Automatic Prompt Engineering
public void pt_automatic_prompt_engineering(ChatClient chatClient) {
// Generate variants of the same request
String orderVariants = chatClient
.prompt("""
We have a band merchandise t-shirt webshop, and to train a
chatbot we need various ways to order: "One Metallica t-shirt
size S". Generate 10 variants, with the same semantics but keep
the same meaning.
""")
.options(ChatOptions.builder()
.temperature(1.0) // High temperature for creativity
.build())
.call()
.content();
// Evaluate and select the best variant
String output = chatClient
.prompt()
.user(u -> u.text("""
Please perform BLEU (Bilingual Evaluation Understudy) evaluation on the following variants:
----
{variants}
----
Select the instruction candidate with the highest evaluation score.
""").param("variants", orderVariants))
.call()
.content();
}
APE is particularly valuable for optimizing prompts for production systems, addressing challenging tasks where manual prompt engineering has reached its limits, and for systematically improving prompt quality at scale.
Reference: Zhou, Y., et al. (2022). "Large Language Models Are Human-Level Prompt Engineers." arXiv:2211.01910. https://arxiv.org/abs/2211.01910
Code prompting refers to specialized techniques for code-related tasks. These techniques leverage LLMs' ability to understand and generate programming languages, enabling them to write new code, explain existing code, debug issues, and translate between languages.
Effective code prompting typically involves clear specifications, appropriate context (libraries, frameworks, style guidelines), and sometimes examples of similar code. Temperature settings tend to be lower (0.1-0.3) for more deterministic outputs.
// Implementation of Section 2.9.1: Prompts for writing code
public void pt_code_prompting_writing_code(ChatClient chatClient) {
String bashScript = chatClient
.prompt("""
Write a code snippet in Bash, which asks for a folder name.
Then it takes the contents of the folder and renames all the
files inside by prepending the name draft to the file name.
""")
.options(ChatOptions.builder()
.temperature(0.1) // Low temperature for deterministic code
.build())
.call()
.content();
}
// Implementation of Section 2.9.2: Prompts for explaining code
public void pt_code_prompting_explaining_code(ChatClient chatClient) {
String code = """
#!/bin/bash
echo "Enter the folder name: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "Folder does not exist."
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "Files renamed successfully."
""";
String explanation = chatClient
.prompt()
.user(u -> u.text("""
Explain to me the below Bash code:
```
{code}
```
""").param("code", code))
.call()
.content();
}
// Implementation of Section 2.9.3: Prompts for translating code
public void pt_code_prompting_translating_code(ChatClient chatClient) {
String bashCode = """
#!/bin/bash
echo "Enter the folder name: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "Folder does not exist."
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "Files renamed successfully."
""";
String pythonCode = chatClient
.prompt()
.user(u -> u.text("""
Translate the below Bash code to a Python snippet:
{code}
""").param("code", bashCode))
.call()
.content();
}
Code prompting is especially valuable for automated code documentation, prototyping, learning programming concepts, and translating between programming languages. The effectiveness can be further enhanced by combining it with techniques like few-shot prompting or chain-of-thought.
Reference: Chen, M., et al. (2021). "Evaluating Large Language Models Trained on Code." arXiv:2107.03374. https://arxiv.org/abs/2107.03374
Spring AI provides an elegant Java API for implementing all major prompt engineering techniques. By combining these techniques with Spring's powerful entity mapping and fluent API, developers can build sophisticated AI-powered applications with clean, maintainable code.
The most effective approach often involves combining multiple techniques—for example, using system prompts with few-shot examples, or chain-of-thought with role prompting. Spring AI's flexible API makes these combinations straightforward to implement.
For production applications, remember to:
With these techniques and Spring AI's powerful abstractions, you can create robust AI-powered applications that deliver consistent, high-quality results.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all