Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreby Dr. Mark Pollack, Christian Tsolov, and Josh Long
Hi, Spring fans! Spring AI is live on the Spring Initializr and everywhere fine bytes might be had. Ask your doctor if AI is right for you! It's an amazing time to be a Java and Spring developer. There's never been a better time to be a Java and Spring developer, and this is doubly true in this unique AI moment. You see, 90% of what people talk about when they talk about AI engineering is just integration with models, most of which have HTTP APIs. And most of what these models take is just human-language Strings. This is integration code, and what place for these integrations to exist than hanging off the side of your Spring-based workloads? The same workloads who business logic drives your organizations and which guard data that feeds your organization.
AI is amazing, but it's not perfect. It has issues, as with all technologies! There are a few things to be on the watch for, and when you explore Spring AI, know that you're doing so in terms of the patterns that support you on your journey to production. Let's look at some of them.
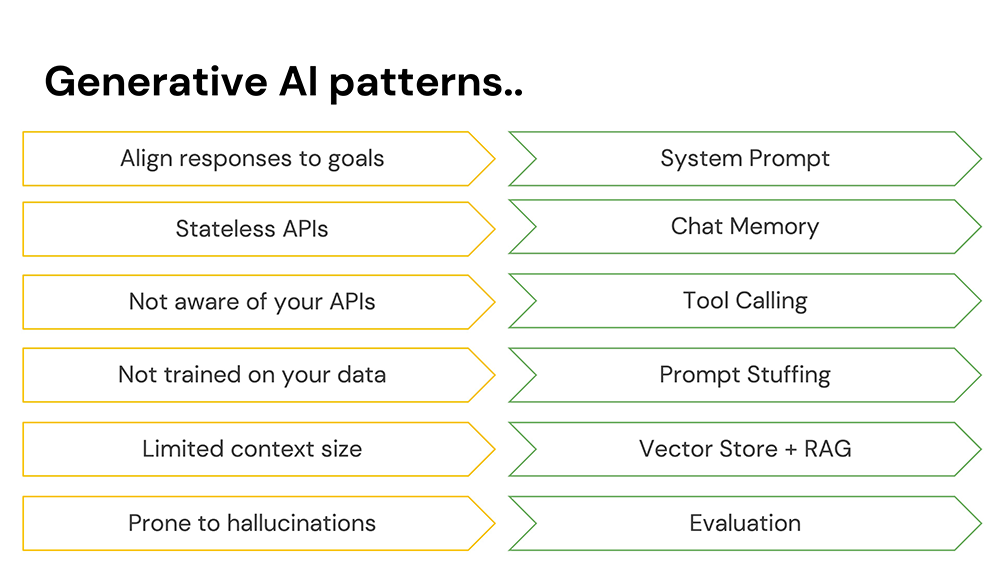
Chat models are amenable to just about anything, and will follow you down just about any rabbit hole. If you want it to stay focused on a particular mission, give it a system prompt.
Models are stateless. You might find that surprising if you've ever dealt with a model through ChatGPT or Claude Desktop, because they submit a transcript of everything that's been said on each subsequent request. This transcript reminds the model what's been said. The transcript is chat memory.
Models live in an isolated sandbox. This makes sense! We've all seen the documentary called The Terminator and know what can go wrong with unruly AI. But, they can do amazing things if you give them a bit of control, via tool calling.
Models are pretty darned smart, but they're not omniscient! You can give them data in the body of the request to help better inform their responses. This is called prompt stuffing.
But don't send too much data! Instead, send only that which might be germaine to the query at hand. You can do this by chucking the data into a vector store, to support finding records that are similar to one another. Then, do retrieval augmented generation (RAG), whereby you send the subselection of results from the vector store to the model for final analysis.
Chat models love to chat, even if they're wrong. This can sometimes produce interesting and incorrect results called hallucinations. Use evaluators to validate that the response is basically what you intended it to be.
Spring AI is a huge leap forward, but for Spring developers it'll feel like a natural next step. It works like any Spring project. It has portable service abstractions allowing you to work consistently and conveniently with any of a number of models. It provides Spring Boot starters, configuration properties, and autoconfiguration. And, Spring AI carries Spring Boot's production-minded ethic forward, supporting vritual threads, GraalVM native images, and observability through Micrometer. It also offers a great developer experience, integrating Spring Boot's DevTools, and provides rich support for Docker Compose and Testcontainers. As with all Spring projects, you can get started on the Spring Initializr.
And that's just what we're going to do! We're going to build an application to support adopting dogs! I'm inspired by a dog that went viral back in 2021. The dog, named Prancer, sounds like he'd be quite the handful! Here's my favorite excerpt from the ad:
"Ok, I’ve tried. I’ve tried for the last several months to post this dog for adoption and make him sound...palatable. The problem is, he’s just not. There’s not a very big market for neurotic, man-hating, animal-hating, children-hating dogs that look like gremlins. But I have to believe there’s someone out there for Prancer, because I am tired and so is my family. Every day we live in the grips of the demonic Chihuahua hellscape he has created in our home."
Sounds like quite a handful! But even spicy dogs deserve loving homes. So let's build a service to unite people with the dogs of their dreams (or nightmares?) Hit the Spring Initializr and add the following dependencies to your project: PgVector, GraalVM Native Support, Actuator, Data JDBC, JDBC Chat Memory, PostgresML, Devtools, and Web. Choose Java 24 (or later) and Apache Maven as the build tool. (Strictly speaking, there's no reason you could not use Gradle here, but the example will be in terms of Apache Maven) Make sure the artifact is named adoptions.
Make sure that in your pom.xml, you've also got: org.springframework.ai:spring-ai-advisors-vector-store.
Some of these things are familiar. Data JDBC just brings in Spring Data JDBC, which is just an ORM mapper that allows you to talk to a SQL database. Web brings in Spring MVC. Actuator brings in Spring Boot's observability stack, underpinned in part by Micrometer. Devtools is a development-time concern, allowing you to do live-reloads as you make changes. It'll automatically reload the code each time you do a "Save" operation in Visual Studio Code or Eclipse, and it'll automatically kick in each time you alt-tab away from IntelliJ IDEA. GraalVM Native Support brings in support for the OpenJDK fork, GraalVM, which provides, among other things, an ahead-of-time compiler (AOT) that produces lightweight, lighting fast binaries.
We said that Spring Data JDBC will make it easy to connect to a SQL database, but which one? In our application, we'll be using PostgreSQL, but not just vanilla PostgresSQL! We're going to load two very important extensions: vector and postgresml. The vector plugin allows PostgresSQL to act as a vector store. You'll need to turn arbitrary (text, image, audio) data into embeddings before they can be persisted. For this, you'll need an embedding model. PostgresML provides that capability here. These concerns are usually orthaganol—it's just very convenient that PostgreSQL can do both chores. A big part of building a Spring AI application is deciding upon which vector store, embedding model, and chat model you will use.
Claude is, of course, the chat model we're going to be using today. To connect to it, you'll need an API key. You can secure one from the Anthropic developer portal. Claude is an awesome fit for most enterprise workloads. It is often more polite, stable, and conservative in uncertain or sensitive contexts. This makes it a great choice for enterprise applications. Claude's also great at document comprehension and at following multistep instructions.
As I said before, we're going to use PostgreSQL. It's not too difficult to get a Docker image working that supports both vector and postgresml. I've included a file, adoptions/db/run.sh. Run that. It'll launch a Docker image. You'll then need to initialize it with an application user. Run adoptions/db/init.sh.
Now you're all set.
Specify your everything to do with your database connectivity in application.properties:
spring.sql.init.mode=always
#
spring.datasource.url=jdbc:postgresql://localhost:5433/postgresml
spring.datasource.username=myappuser
spring.datasource.password=mypassword
#
spring.ai.postgresml.embedding.create-extension=true
spring.ai.postgresml.embedding.options.vector-type=pg_vector
#
spring.ai.vectorstore.pgvector.dimensions=768
spring.ai.vectorstore.pgvector.initialize-schema=true
#
spring.ai.chat.memory.repository.jdbc.initialize-schema=always
Here we're specifying what kind of vector we want, whether we want Spring AI to initialize the PostgresML extension. We're specifying what dimensions we want for vectors stored in PostgreSQL, and whether we want Spring AI to initialize the schema required to use it as a vector store.
We also want to install some data (the dogs!) into the database, so we'll tell Spring Boot to run schema.sql and data.sql which creates a table and installs data in the database, respectively.
We'll need to talk to the just-created dog table, so we've got a Spring Data JDBC entity and repository. Add the following types to the bottom of AdoptionsApplication.java, after the last }.
interface DogRepository extends ListCrudRepository<Dog, Integer> {
}
record Dog(@Id int id, String name, String owner, String description ){
}
We're going to field questions from users via our HTTP controller. Here's the skeleton definition:
@Controller
@ResponseBody
class AdoptionsController {
private final ChatClient ai;
AdoptionsController (ChatClient.Builder ai ) {
this.ai = ai.build();
}
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.call()
.content();
}
}
So, basically, we can ask questions by making HTTP requests to :8080/youruser/assistant. Try it out.
http :8080/jlong/assistant question=="my name is Josh"
You should get an effusive response. We're friends, it sounds like!
Let's put that friendship to the test.
http :8080/jlong/assistant question=="what's my name?"
In my run, I was disappointed to learn that Claude had already forgotten about me. It has no memory of me whatsoever! Let's give our model some memory. We'll do this with an advisor, which pre- and post-processes requests to the model, called PromptChatMemoryAdvisor. Add its definition to the AdoptionsApplication.
@Bean
PromptChatMemoryAdvisor promptChatMemoryAdvisor(DataSource dataSource) {
var jdbc = JdbcChatMemoryRepository
.builder()
.dataSource(dataSource)
.build();
var chatMessageWindow = MessageWindowChatMemory
.builder()
.chatMemoryRepository(jdbc)
.build();
return PromptChatMemoryAdvisor
.builder(chatMessageWindow)
.build();
}
Advisors are like filters or interceptors. They're a great way to add to the body of a request or handle the response in a generic, cross-cutting kind of way. Sort of like Spring's aspect-oriented programming support.
This advisor will persist the messages for you. In this instance, it'll persist it to our PostgreSQL database, using schema we've already told Spring AI to initialize (spring.ai.chat.memory.repository.jdbc.initialize-schema=always).
Change the configuration for the ChatClient:
// ..
AdoptionsController (PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai ) {
this.ai = ai
.defaultAdvisors(promptChatMemoryAdvisor)
.build();
}
// ..
In order for the PromptChatMemoryAdvisor to do its work, it needs to some way to correlate the request from you with a given conversation. You can do this by assigning a conversation ID on the request. Modify the inquire method:
@GetMapping("/{user}/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
return ai
.prompt()
.user(question)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, user)) // new
.call()
.content();
}
In this instance, we're simply using the path variable from the URL to create distinct conversations. Naturally, a much more suitable approach might be to use the Spring Security authenticated Principal#getName() call, instead. If you have Spring Security installed, you could inject the authenticated principal as a parameter of the controller method.
Relaunch the program and then re-run the same HTTP interactions, and this time you should find the model remembers you. NB: you can always reset the memory by deleting the data in that particular table.
Nice! If you just built a quick UI, you'd have—in effect—your own Claude Desktop. Which is not exactly what we want. Remember, we're trying to help people adopt dog from our fictitious dog adoption agency Pooch Palace. We don't want people doing their homework or getting coding help from our assistant. Let's give out model a mission statement by configuring a system priompt. Change the configuration again:
// ..
AdoptionsController (PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai ) {
var system = """
You are an AI powered assistant to help people adopt a dog from the adoption agency named Pooch Palace with locations in Rio de Janeiro, Mexico City, Seoul, Tokyo, Singapore, New York City, Amsterdam, Paris, Mumbai, New Delhi, Barcelona, London, and San Francisco. Information about the dogs available will be presented below. If there is no information, then return a polite response suggesting we don't have any dogs available.
""";
this.ai = ai
.defaultSystem(system)
// ..
.build();
}
// ..
Let's try asking a question more on point:
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
We're hoping the model will know about our friend Prancer. It will return, alas, that it does not.
We haven't extended access to our SQL database to the model (yet). We could read all the database in and then just concatenate it all into the body of the request. Conceptually, assuming we have a small enough data set and a large enough token count, that would work. But it's the principle of the thing! Remember, all interactions with the model incur a token cost. This cost may be born in dollars and cents, such as when using hosted multitenant LLMs like Claude, or at the very least its born in complexity (CPU and GPU resource consumption) costs. Either way: we want to reduce those costs, whenever possible.
You can and should keep an eye on the token consumption thanks to the Spring AI integration with the Actuator module. In your application.properties, add the following:
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
Restart the application and then drive some requests to the model. Then navigate to localhost:8080/actuator/metrics in your browser and you should see metrics starting with gen_ai, e.g.: gen_ai.client.token.usage. Get the details about that metric here: localhost:8080/actuator/metrics/gen_ai.client.token.usage. The metrics integration is powered by the fabulous Micrometer project, which integrates with darn near every time series database under the sun, including Prometheus, Graphite, Netflix Atlas, DataDog, Dynatrace, etc. So, you could also have these metrics published to those TSDBs to help build out that all important single pane of glass experience for operations.
Read all the data from the SQL database using the newly minted DogRepository and then write out Spring AI Documents to the VectorStore in the constructor.
//...
AdoptionsController(JdbcClient db,
PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
var count = db
.sql("select count(*) from vector_store")
.query(Integer.class)
.single();
if (count == 0) {
repository.findAll().forEach(dog -> {
var dogument = new Document("id: %s, name: %s, description: %s".formatted(
dog.id(), dog.name(), dog.description()
));
vectorStore.add(List.of(dogument));
});
}
// ... same as before
}
There's no particular scheme here. We're writing a Document with some string data. It doesn't matter what's in the string.
This will use PostgresML behind the scenes to do the work. We must configure a QuestionAnswerAdvisor so that the ChatClient will know to consult the vector store for supporting documents ("doguments"?) the requests before sending the request off to the model for final analysis. Modify the definition of the ChatClient later on in the constructor accordingly:
this.ai = ai
// ...
.defaultAdvisors(promptChatMemoryAdvisor,
new QuestionAnswerAdvisor(vectorStore))
// ...
.build();
Re-run the request asking about neurotic dogs and you should find that, indeed, there's a neurotic dog who might just be what the dogtor ordered, and his name is Prancer! Nice!
NB: We've been getting the response as a String, but that's no foundation on which to build an abstraction! We need a strongly typed object we can pass around our codebase. You could have the model map the return data to such a strongly-typed object, if you wanted. Suppose you had the following record:
record DogAdoptionSuggestion(int id,String name, String description) {}
We could use the entity(Class<?>) method instead of the content() method:
//
@GetMapping("/{user}/assistant")
DogAdoptionSuggestion inquire (...) {
return ai
.prompt()
.user(..) //
.entity(DogAdoptionSuggestion.class);
}
You'd get a strongly typed object back instead. How? Magic! (I guess.) Anyway, you could do that, but we're going to carry on with our content(), since after all we're building a chatbot.
So, we've been reunited with the dog of our dreams! What now? Well, the natural next step for any red-blood human being would be to want to adopt that doggo, surely! But there's scheduling to be done. Let's allow the model to integrate with our patent-pending, class-leading scheduling algorithm by giving it access to tools.
Add the following type to the bottom of the code page:
@Component
class DogAdoptionScheduler {
@Tool(description = "schedule an appointment to pickup or adopt a " +
"dog from a Pooch Palace location")
String schedule(int dogId, String dogName) {
System.out.println("Scheduling adoption for dog " + dogName);
return Instant
.now()
.plus(3, ChronoUnit.DAYS)
.toString();
}
}
This is just a Spring bean like any other. We're announcing that this method has been called, and then returning a date hard-coded to be three days in the future. The important bit is that we've got a method made available for consumption by the model annotated as @Tools. Importantly, the tools have descriptions in human language prose that are as descriptive as possible. Remember when your mother said, "use your words!" This is what she meant! It'll help you be a better AI engineer (not to mention a better teammate, but that discussion is a totally different Oprah for another day...).
Make sure to update the ChatClient configuration by pointing it to the tools:
AdoptionsController(
JdbcClient db,
DogAdoptionScheduler scheduler,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
// ...
this.ai = ai
.defaultTools(scheduler)
// ..
.build();
}
Now let's try the two step interaction:
http :8080/jlong/assistant question=="do you have any neurotic dogs?"
Once it confirms that there's a dog named Prancer, inquire about scheduling a pickup from the New York City location:
http :8080/jlong/assistant question=="fantastic. when can i schedule an appointment to pickup Prancer from the New York City location?"
You should see the confirmation on the console that the method was called and you should see that the date is three days in the future. Nice.
Already, we've opened up a ton of possibilities! Spring AI is a concise and powerful component model, and Claude is a very brilliant chat model, with which we've integrated our data and our tools. Ideally, though, we should be able to consume tools in a uniform fashion, without being coupled so much to a particular programming model. In November 2025, Anthropic released an update to Claude Desktop that featured a new network protocol called Model Context Protocol (MCP). MCP provides a convenient way for the model to benefit from tools regardless of the language in which they were written. There are two flavors of MCP: STDIO and HTTP streaming over server-sent events (SSE).
The result has been very positive! Since its launch we've witnessed a Cambrian explosion of new MCP services - . There are countless MCP sercices. There are countless directories of MCP services. And now, we're starting to see a proliferation of directories of directories of new MCP services! And it all redounds to our benefit; each MCP service is a new trick you can teach your model. There are MCP services for Spring Batch, Spring Cloud Config Server, Cloud Foundry, Heroku, AWS, Google Cloud, Azure, Microsoft Office, Github, Adobe, etc. There are MCP services that let you render 3D scenes in Blender3D. There are MCP services which in turn connect any number of other integrations and services, including those in Zapier, for example.
And now, we're going to add one more to the mix. Let's extract out the scheduling algorithm as an MCP service and reuse it thusly. Hit the Spring Initializr and select GraalVM Native Support, Web and Model Context Protocol Server. Choose Java 24 (or later) and Apache Maven. Name the project scheduler. Hit Generate and then open the project inside the resulting .zip file in your favorite IDE.
Cut and paste the DogAdoptionScheduler to the bottom of the new project. Add the following definition to the main class (SchedulerApplication.java):
@Bean
MethodToolCallbackProvider methodToolCallbackProvider(DogAdoptionScheduler scheduler) {
return MethodToolCallbackProvider
.builder()
.toolObjects(scheduler)
.build();
}
Change application.properties to ensure the new service starts on a different port.
# ...
server.port=8081
Start the scheduler. Return to the adoptions module and let's rework it to point instead to this new, remote HTTP-based MCP service.
Delete all references in the code to the DogAdoptionScheduler . Define a bean of type McpSyncClient in the configuration.
@Bean
McpSyncClient mcpSyncClient() {
var mcp = McpClient
.sync(HttpClientSseClientTransport.builder("http://localhost:8081").build()).build();
mcp.initialize();
return mcp;
}
Now, in the constructor, specify a tool callback, pointing to this:
AdoptionsController(JdbcClient db,
McpSyncClient mcpSyncClient,
PromptChatMemoryAdvisor promptChatMemoryAdvisor,
ChatClient.Builder ai,
DogRepository repository,
VectorStore vectorStore) {
// ...
this.ai = ai
// ..
.defaultToolCallbacks(new SyncMcpToolCallbackProvider(mcpSyncClient))
// ..
.build();
}
Restart the process and ask the same two questions again and this time you should see that the MCP service ends up printing out the confirmation of the schedule, and that the proposed date is indeed still three days ahead in the future.
Claude Desktop has supported configuring MCP services using a .json configuration file since the beginning and to ease interoperability, Spring AI also supports this configuration format. Here's the .json configuration for the GitHub MCP service, for example:
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "...."
}
}
}
}
NB: you'd need to specify your own GitHub personal access token there. It's a breeze to tell Spring AI to include that MCP definition as a tool. You would only need to add the following to the application.properties file, for example:
spring.ai.mcp.client.stdio.servers-configuration=classpath:/github-mcp.json
Now, you could ask the assistant to help you with scheduling and then have it write the proposed date to a file in GitHub, all without any intervention. Nice!
MCP debuted in Claude Desktop, and at the time of its launch it only supported STDIO-based services on the same host. Recently, that's changed. Claude Desktop just added support for HTTP remote MCP services, such as our scheduler. You'll need to upgrade your Anthropic Account as, at least at the time of this writing, it's only available behind a Max plan. (for which I could not wait to pay!) You can repurpose our scheduler service as a tool that you wield directly from Claude Desktop itself. Assuming you have Claude Desktop installed (it works on macOS and Windows as of this writing), you'd go through the following steps to configure the remote integration.
First, you'll need top open up Claude's Settings screen.
Then, open up the Integrations section of the Settings screen.
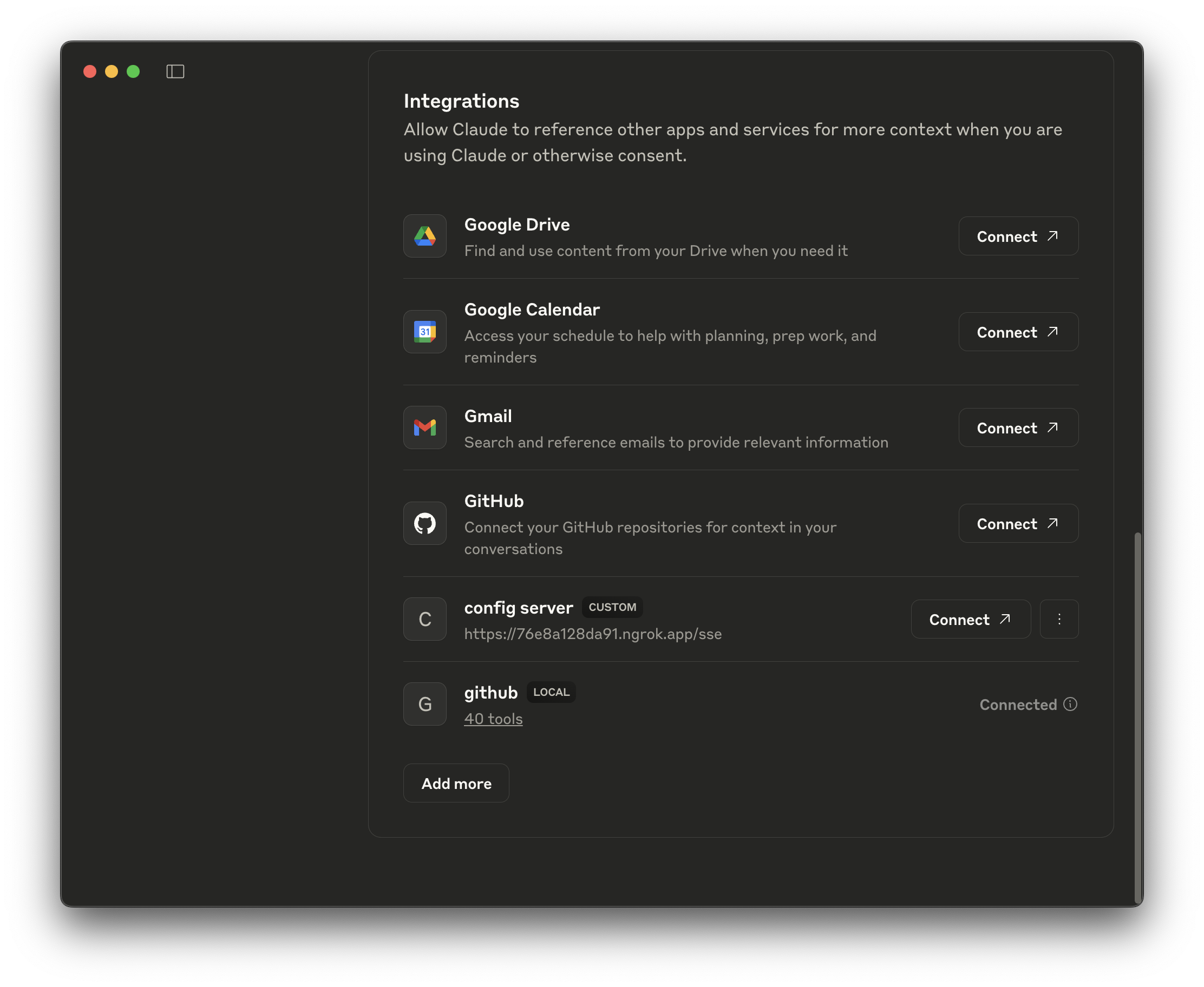
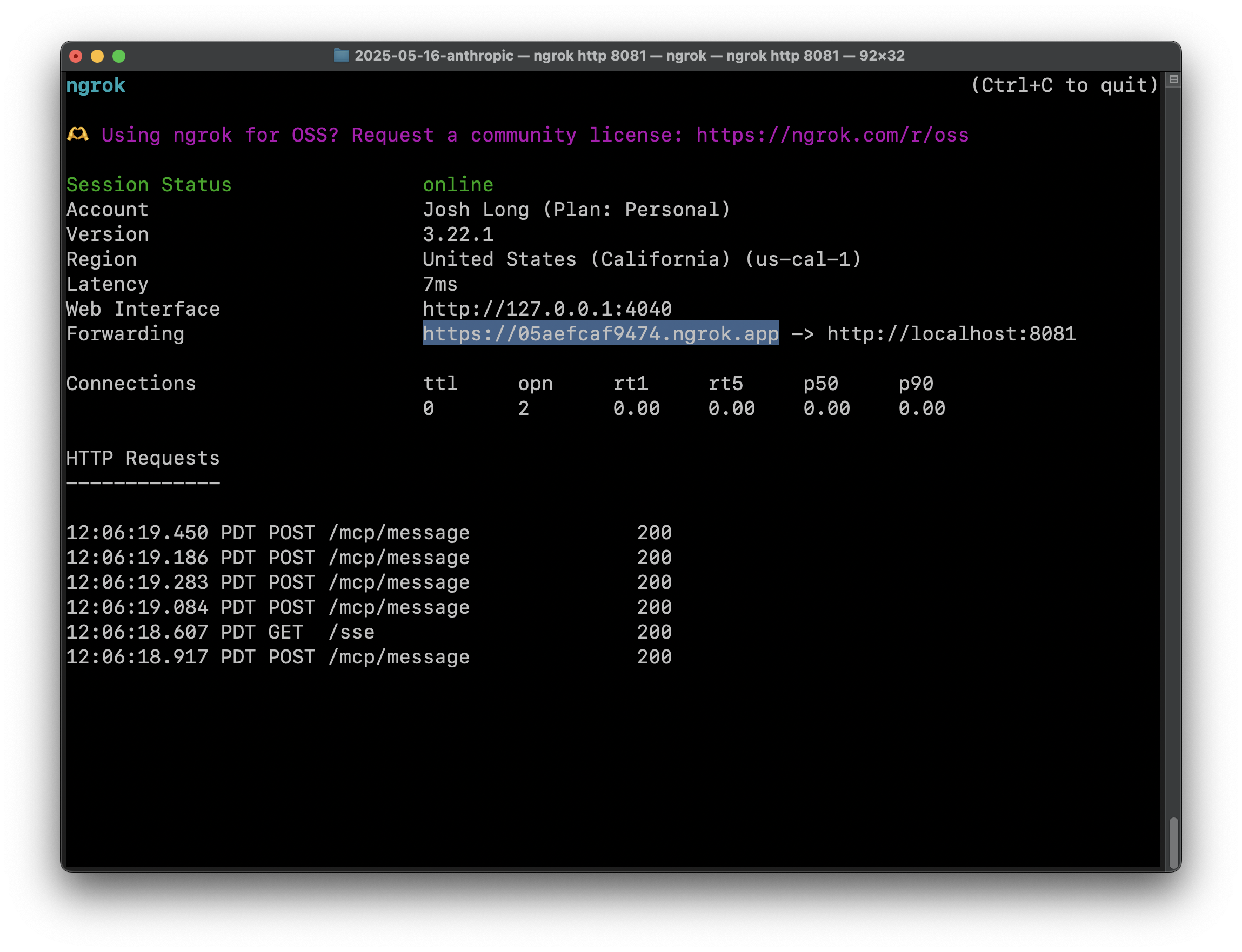
In order for you to test this service, it'll need to have a publicly available URL. Obviously, there are a ton of places you could run your application (CloudFoundry, AWS, Google Cloud, Azure, etc.), but to make development a little easier, may we recommend ngrok? It'll make your local service(s) available on a dynamic public URL. We had to pay to upgrade to get it to stop showing an interstitial page. It was maybe $8 USD, if memory serves, which isn't too bad. Run:
ngrok http 8081
This will set up a tunnel to whatever service is running on port 8081, allowing you to access it via a dynamic URL printed to the console.
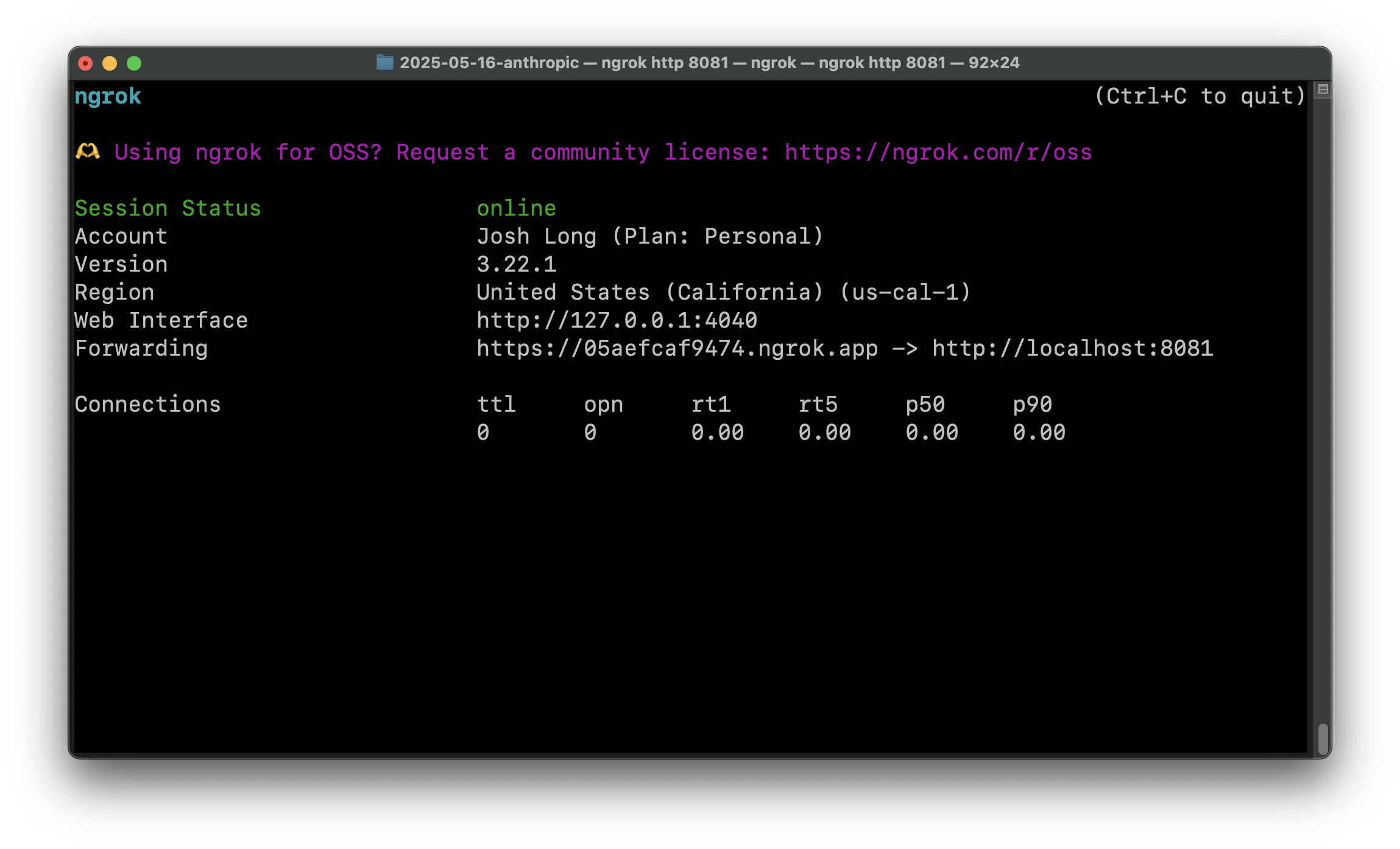
Now we need to tell Claude Desktop about the service back in the Integrations section of the Settings page.

Hit Add and then Connect on the main screen. You should see confirmation of the connection between Claude Desktop and the scheduler service on port 8081 in the ngrok console.
Ask Claude Desktop the same question as above: "when can i schedule an appointment to pickup Prancer from the New York City location?" In our run, it also asked us to specify the ID of the dog, which we did: 45. It'll eventually prompt you to permit it to invoke the tool you just gave it:
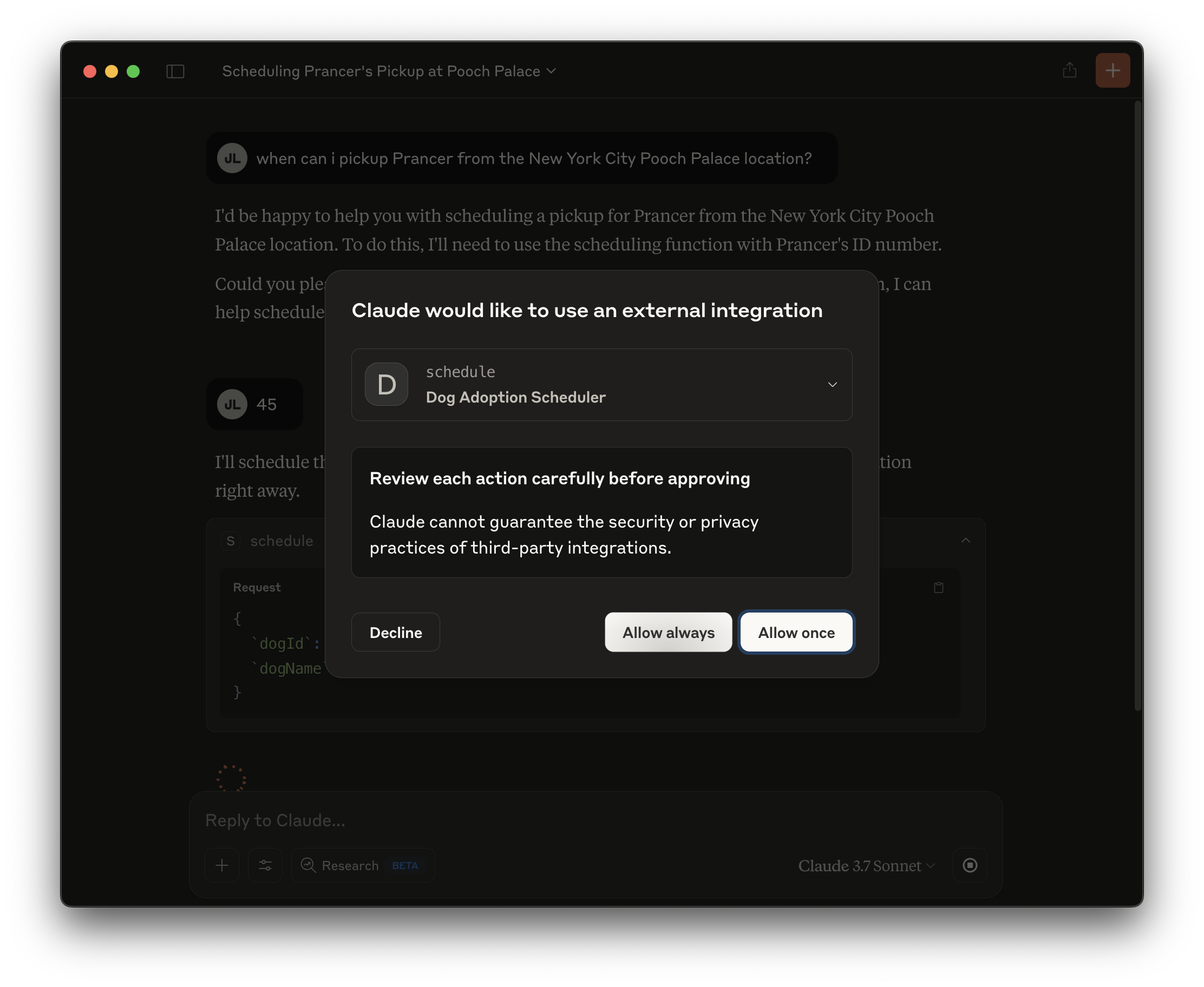
Oblige it and then off it goes!
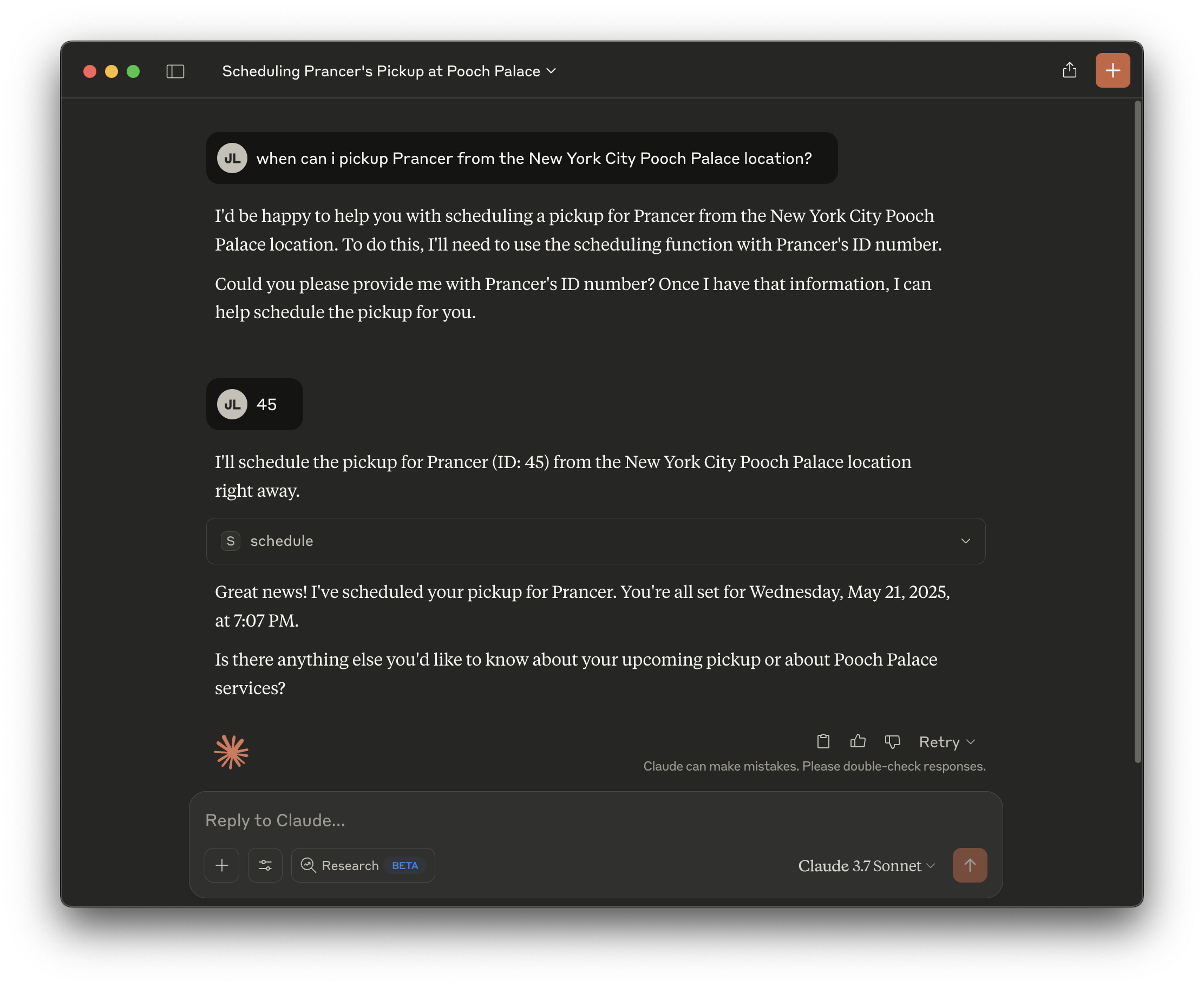
It should give you a date three days hence. Neat!
Now, it’s time to turn our eyes toward production.
It’s trivial to use Spring Security to lock down this web application. You could use the authenticated Principal#getName to use as the conversation ID too. What about the data stored in the database, like the conversations? Well, you have a few options here. Many databases support encryption at rest as a passive capability.
We want this code to be scalable. Remember, each time you make an HTTP request to a model (or many relational databases), you’re doing blocking IO. IO that sits on a thread and makes that thread unavailable to any other demand in the system until the IO has completed. This is a waste of a perfectly good thread! Threads aren't meant to just sit idle, waiting. Java 21 gives us virtual threads, which - for sufficiently IO bound services - can dramatically improve scalability. That’s why you should (almost?) always set up spring.threads.virtual.enabled=true in the application.properties file.
GraalVM is an AOT compiler, led by Oracle, that you can consume through the GraalVM Community Edition open source project or through the very powerful (and free) Oracle GraalVM distribution. If you're using SDKMAN, it's trivial to install either: sdk install java 24-graalce or sdk install java 24-graal. Then, make sure to use one of those JDK distributions, e.g.: sdk use java 24-graal or even make it your default system-wide sdk default java 24-graalce.
Remember, we configured both of our Spring AI services with GraalVM Native Support, which adds a build plugin which will allow us to create turn this application into an operating system and architecture-specific native binary:
./mvnw -DskipTests -Pnative native:compile
Stand back. You might even have time enough to get a cup of coffee.. This takes a minute or so on most machines, but once it’s done, you can run the binary with ease.
./target/scheduler
This program will start up in a fraction of the time that it did on the JVM. On my machine it starts up in less than a tenth of a second. Even better, you should observe that the application takes a very small fraction of the RAM it would've otherwise taken on the JVM. When the application starts up, it prints out its process identifier (PID) towards the top of the logs. Note that then run:
ps -o rss <PID>
The number is measured in kilobytes, do divide by 1,000 to get the number inf megabytes. Whatever number you get, I'm sure you will recognize it as being far lower than what you might've gotten on the JVM.
That’s all very well and good, you might day, but I need to get this running on my cloud platform and that means getting it into the shape of a Docker image. Easy!
./mvnw -DskipTests -Pnative spring-boot:build-image
Stand back. This might take another minute still. When it finishes, you’ll see its printed out the name of the Docker image that’s been generated. You can run it, remembering to override the hosts and ports of things it would've referenced on your host. Interestingly: we’re on macOS, and amazingly, this application when run in a macOS virtual machine emulating Linux, runs even faster—and right from the jump, too!—then it would’ve on macOS directly! Amazing!
This application’s so darn good; I’ll bet it’ll make headlines, just like Prancer, in no time. And when that happens, you’d be well advised to keep an eye on your system resources and - importantly - the token count. All requests to an LLM have a cost - at least one of complexity, if not dollars and cents. As we explored earlier, the Spring Boot observability story is ideal here.
You've just built a production-worthy AI application powered by Claude, PostgresSQL, and Spring AI. We hope you'll get started today on the Spring Initializr

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all