Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreIn the past couple of years we have seen heavy investment throughout the Java ecosystem to reduce application startup times. The main focus gravitates around Ahead-of-Time optimizations. May it be condensing code into a GraalVM native executable, capturing already optimized bytecode with Coordinated Restore at Checkpoint (CRaC), Class Data Sharing (CDS) or its more recent successor AOT cache (part of project Leyden). While barriers to entry vary between the different approaches, all of them move performance optimizations away from runtime into an earlier phase, such as build time or a separate packaging step.
The Spring portfolio has you covered: It supports you in whichever direction you want to take it:
With Spring Data 4.0 (or the 2025.1 release train if you prefer calver) we are taking your repositories to AOT. We are shifting all the Repository preparations that are done at application startup to build time.
In short, when setting the spring.aot.repositories.enabled=true configuration property, our AOT processing turns your repository query methods into actual source code by relying on the store-specific nature of the repository.
Generated query methods contain the exact same code you would write if you would not use Spring Data to run your query.
The generated source is then compiled together with your application and backing the repository interface.
Imagine a repository of pet owners as outlined below.
The repository itself does not inherit any functionality from one of the base repositories like CrudRepository to keep the exposed functionality at a minimum.
Still the save method matches the signature of one of the predefined methods, while the two listed query methods are using a derived as well as explicitly annotated approach.
interface OwnerRepository extends Repository<Owner, Integer> {
Owner save(Owner owner);
List<OwnerSummary> findAllByLastName(String lastName);
@Transactional(readOnly = true)
@Query("SELECT DISTINCT owner FROM Owner owner left join owner.pets WHERE owner.lastName LIKE :lastName%")
Page<Owner> findByLastName(@Param("lastName") String lastName, Pageable pageable);
// ...
}
During the AOT phase the infrastructure will only consider relevant parts for the code generation.
Take the before mentioned save method for example: Since we are using JPA here, SimpleJpaRepository already holds a default implementation for the save method, allowing the code generation to skip the method.
The same is true for any of your custom implementations.
The remaining two methods for OwnerRepository however are of course subject to AOT optimizations and end up in OwnerRepositoryImpl__Aot located in the same package as the source OwnerRepository.
@Generated
public class OwnerRepositoryImpl__Aot extends AotRepositoryFragmentSupport {
private final EntityManager entityManager;
public OwnerRepositoryImpl__Aot(EntityManager entityManager,
RepositoryFactoryBeanSupport.FragmentCreationContext context) {
// ...
}
/**
* AOT generated implementation of {@link OwnerRepository#findAllByLastName(String)}.
*/
public List<OwnerSummary> findAllByLastName(String lastName) {
String queryString = "SELECT o.firstName AS firstName, o.lastName AS lastName, o.city AS city FROM org.springframework.samples.petclinic.owner.Owner o WHERE o.lastName = :lastName";
Query query = this.entityManager.createQuery(queryString, Tuple.class);
query.setParameter("lastName", lastName);
return (List<OwnerSummary>) convertMany(query.getResultList(), false, OwnerSummary.class);
}
/**
* AOT generated implementation of {@link OwnerRepository#findByLastName(String,Pageable)}.
*/
public Page<Owner> findByLastName(String lastName, Pageable pageable) {
String queryString = "SELECT DISTINCT owner FROM Owner owner left join owner.pets WHERE owner.lastName LIKE :lastName";
String countQueryString = "SELECT count(DISTINCT owner) FROM Owner owner left join owner.pets WHERE owner.lastName LIKE :lastName";
if (pageable.getSort().isSorted()) {
DeclaredQuery declaredQuery = DeclaredQuery.jpqlQuery(queryString);
queryString = rewriteQuery(declaredQuery, pageable.getSort(), Owner.class);
}
Query query = this.entityManager.createQuery(queryString);
query.setParameter("lastName", "%s%%".formatted(lastName));
if (pageable.isPaged()) {
query.setFirstResult(Long.valueOf(pageable.getOffset()).intValue());
query.setMaxResults(pageable.getPageSize());
}
LongSupplier countAll = () -> {
Query countQuery = this.entityManager.createQuery(countQueryString);
countQuery.setParameter("lastName", "%s%%".formatted(lastName));
return (Long) countQuery.getSingleResult();
};
return PageableExecutionUtils.getPage((List<Owner>) query.getResultList(), pageable, countAll);
}
}
As you can see the generated code can be rather simple or grow in complexity depending on the query, parameter binding or the requested data and its representation. On application startup, the AOT-generated classes are wired into the repository composition that is backing the proxy created for the repository interface. So for the first time you can actually see and step into the code that is run when calling a method on a repository interface.
Debugability aside, pre-generated code helps with parsing queries and exploring assumptions. It shortens code paths during repository bootstrap leading to faster overall application startup and less memory.
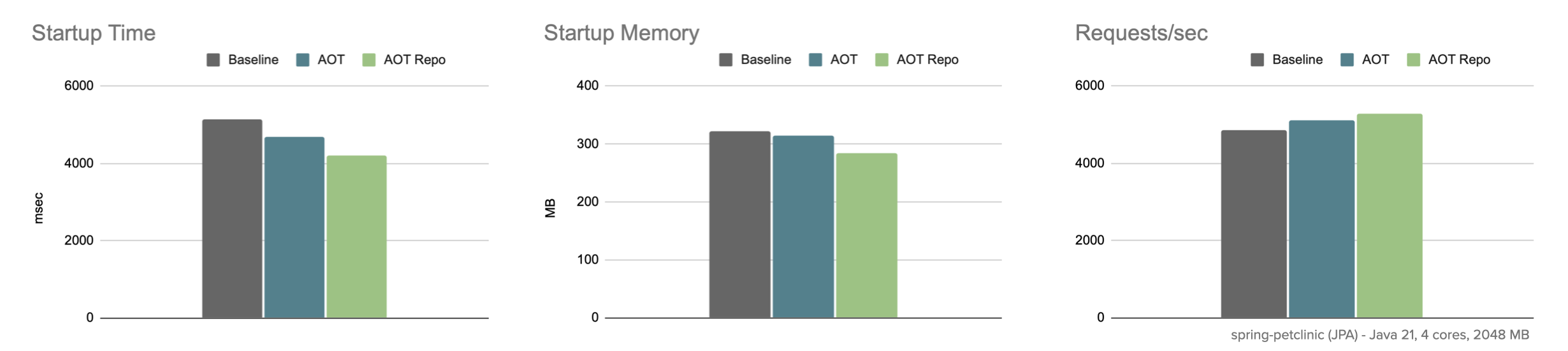
Depending on the underlying data store the reduction can be rather significant, like for Spring Data JPA leading to an additional startup boost and less memory on top of already more efficient AOT optimizations.
Ahead-of-Time repositories are currently a preview feature that in their first incarnation being available for JPA (via Hibernate only) and MongoDB, with more modules to follow with upcoming milestones.
Please give this new feature a try and do not hesitate to get in touch with us to let us know what you think.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all