Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThis article is part of a blog series that explores the newly redesigned Spring Cloud Stream applications based on Java Functions. In this episode, we are taking a deeper look into the file supplier and its Spring Cloud Stream file source counterpart. We will also see a MongoDB consumer and its corresponding Spring Cloud Stream sink. Finally, we will demonstrate how the File source and the MongoDB sink can be orchestrated together on Spring Cloud Data Flow as a pipeline.
Here are all the previous parts of this blog series.
File ingestion and reading data from those files is a classic enterprise use case. Many businesses have been relying on varying levels of file facilities for many decades to carry out mission-critical systems. Terabytes of data travel through the interwebs and enterprise intranets as files. For example, imagine a banking data center where it receives data from all its branches, ATMs, and POS transactions as files every second which then needs to be processed and placed into other systems. This is just one domain, but there are hundreds of thousands of examples out there in which file processing is on the critical path of many businesses. There are a lot of legacy systems in which many custom applications were written each employing its own ways of handling these use cases. Spring Integration has been providing file support as channel adapters for many years. These components can be realized as functions and in the case of reading from files, we can provide a generic Supplier function that is reusable and injected in end-user applications. In the following sections, we will see more details about this functional abstraction and it’s various usage scenarios.
File Supplier is a component that is implemented as java.util.function.Supplier bean which when invoked will deliver the contents of the files in a given directory. The file supplier has the following signature.
Supplier<Flux<Message<?>>>
The users of the supplier can subscribe to the returned Flux<Message<?>, which is a stream of messages or File objects in the directory themselves.
In order to invoke the file supplier, we need to specify a directory to poll for files. The directory information is required and must be provided through the configuration property file.supplier.directory. By default, the supplier will produce data as byte[], but it also supports two additional file consuming modes through the configuration property file.consumer.mode. The additional values supported are lines and ref. The file consuming mode lines will consume the file contents one line at a time. This is useful for reading text files such as CSV files and other structured textual data. The ref mode will provide the actual File object. By default, the file supplier also prevents reading the same file that it already read before. This is controlled through the property file.supplier.preventDuplicates.
File supplier is a reusable Spring bean that we can be injected in end-user custom applications. Once injected, this can be directly invoked and combined with custom processing of the data. Here is an example.
@Autowired
Supplier<Flux<Message<?>>> fileSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> data = fileSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
In the above pseudo-code, we are injecting the file supplier bean and then use it to invoke its get method to get a Flux. We then subscribe to that Flux and each time receive any data through the Flux, apply some filtering, and take actions based on that. This is just a simple illustration to show how we can reuse the file supplier. When you try this in a real application, you probably need to do more adjustments in your implementation, such as converting the default data type of the received data from byte[] into something else before doing the conditional check or changing the default file reading mode from content to lines etc.
File supplier becomes more powerful when it is combined with Spring Cloud Stream to make it a file source. As we have seen in the earlier blogs, this supplier is already prepackaged with both Kafka and RabbitMQ binders in Spring Cloud Stream to make them uber jars which are runnable as Spring Boot applications. Let’s see how we can take this uber jar and run it as standalone.
As a first step, go ahead and grab this file source with the Apache Kafa variant.
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/file-source-kafka/3.0.0-SNAPSHOT/file-source-kafka-3.0.0-SNAPSHOT.jar
Make sure that you have Kafka running at the default port.
Now it is time to run the file source standalone.
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data
By default, Spring Cloud Stream expects the output binding to be fileSupplier-out-0 (since fileSupplier is the supplier bean name). However, when these applications are generated, this output binding is overridden to output. This is done in order to accommodate some requirements when running this source application on Spring Cloud Data Flow.
We are also asking the application to read files landing in the /tmp/data-files directory and consume them as one line at a time (using the mode lines)..
Watch the kafka topic file-data. Using the kafkacat tool, you can do this:
kafkacat -b localhost:9092 -t file-data
Now, place some files in the /tmp/data-files directory. You will see data arrive in the file-data Kafka topic with each line in the files representing a Kafka record.
If you want to restrict the files to certain patterns, you can use a simple naming pattern using the property file.supplier.filenamePattern or a more complex regex based pattern using the property file.supplier.filenameRegex.
As we have seen in the second part of this blog series, all the out of the box Spring Cloud Stream source applications are already autoconfigured with several out of the box general-purpose processors. You can activate these processors as part of the File source. Here is an example, where we run the file source and receive the data and then transforms the consumed data before sending it out to the destination on middleware.
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data --spring.cloud.function.definition=fileSupplier|spelFunction --spel.function.expression=payload.toUpperCase()
By providing the value, fileSupplier|spelFunction for spring.cloud.function.definition property, we are activating the spel function composed with the file supplier. Then we provide a SpEL expression that we want to use to transform the data using spel.function.expression.
There are several other functions available to compose this way. Take a look here fore more details.
MongoDB consumer provides a function that allows one to receive data from external systems and then write that data into MongoDB. We can use the consumer bean directly in our custom applications to insert data into MongoDB collections. Here is the type signature of the MongoDB consumer bean.
Consumer<Message<?>> mongodbConsumer
Once injected into a custom application, users can directly invoke the accept method of the consumer and provide a Message<?> object to send it’s payload to a MongoDB collection.
When using the MongoDB consumer, the collection is a required property and it must be configured through mongodb.consumer.collection.
As in the case of File Source, Spring Cloud Stream out of the box applications already provide a MongoDB sink using the MongoDB consumer. The sink is available for both Kafka and RabbitMQ binder variants. When used as a Spring Cloud Stream sink, the MongoDB consumer is automatically configured to accept data from the respective middleware system, for example, from a Kafka topic or RabbitMQ exchange.
Let’s take a few minutes and verify that we can run the MongoDB sink standalone.
Perform the following commands on a terminal window.
docker run -d --name my-mongo \
-e MONGO_INITDB_ROOT_USERNAME=mongoadmin \
-e MONGO_INITDB_ROOT_PASSWORD=secret \
-p 27017:27017 \
mongo
docker exec -it my-mongo /bin/sh
This will get us into a shell session into the running docker container. Invoke the following commands within the shell.
# mongo
> use admin
> db.auth('mongoadmin','secret')
1
> db.createCollection('test_collection’')
{ "ok" : 1 }>
Now that we have our MongoDB setup, let’s run the sink standalone.
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/mongodb-sink-kafka/3.0.0-SNAPSHOT/mongodb-sink-kafka-3.0.0-SNAPSHOT.jar
java -jar mongodb-sink-kafka-3.0.0-SNAPSHOT.jar --mongodb.consumer.collection=test_collection --spring.data.mongodb.username=mongoadmin --spring.data.mongodb.password=secret --spring.data.mongodb.database=admin --spring.cloud.stream.bindings.input.destination=test-data-mongo
Insert some JSON data into the Kafka topic test-data-mongo. For instance, you can use the console producer script that comes with Kafka as below.
/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test-data-mongo
And then produce data like this:
{"hello":"mongo"}
Go to the MongoDB CLI on the terminal that we started on the Docker shell above.
db.test_collection.find()
The data that we entered through the Kafka topic should be displayed as output.
Running both File source and MongoDB standalone was fine, but Spring Cloud Data Flow makes it really easy to run them as a pipeline. Basically we want to orchestrate a flow that is equivalent to File Source | Filter | MongoDB.
One of the blogs in this series dedicated to all the details of how you can run Spring Cloud Data Flow and deploy applications as streams. Please review that blog if you are not familiar with running Spring Cloud Data Flow. Below, we are providing the steps involved in setting up Spring Cloud Data Flow briefly.
First, we need to get the docker-compose file for running Spring Cloud Data Flow.
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
Also, get this additional docker-compose file for running MongoDB.
wget -O mongodb.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/mongodb.yml
We need to set up a few environment variables in order to run Spring Cloud Data Flow properly.
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
Now that we have everything ready to go, it is time to start running Spring Cloud Data Flow and all the other ancillary components.
docker-compose -f docker-compose.yml -f mongo.yml up
Once SCDF is up and running go to http://localhost:9393/dashboard. Then go to Streams on the left-hand side and select Create Stream. Select File from the source applications, Filter from the processors, and MongoDB from the sink applications. Click on the options and select the following properties. Here is a screenshot of how it should look after all the properties are selected.
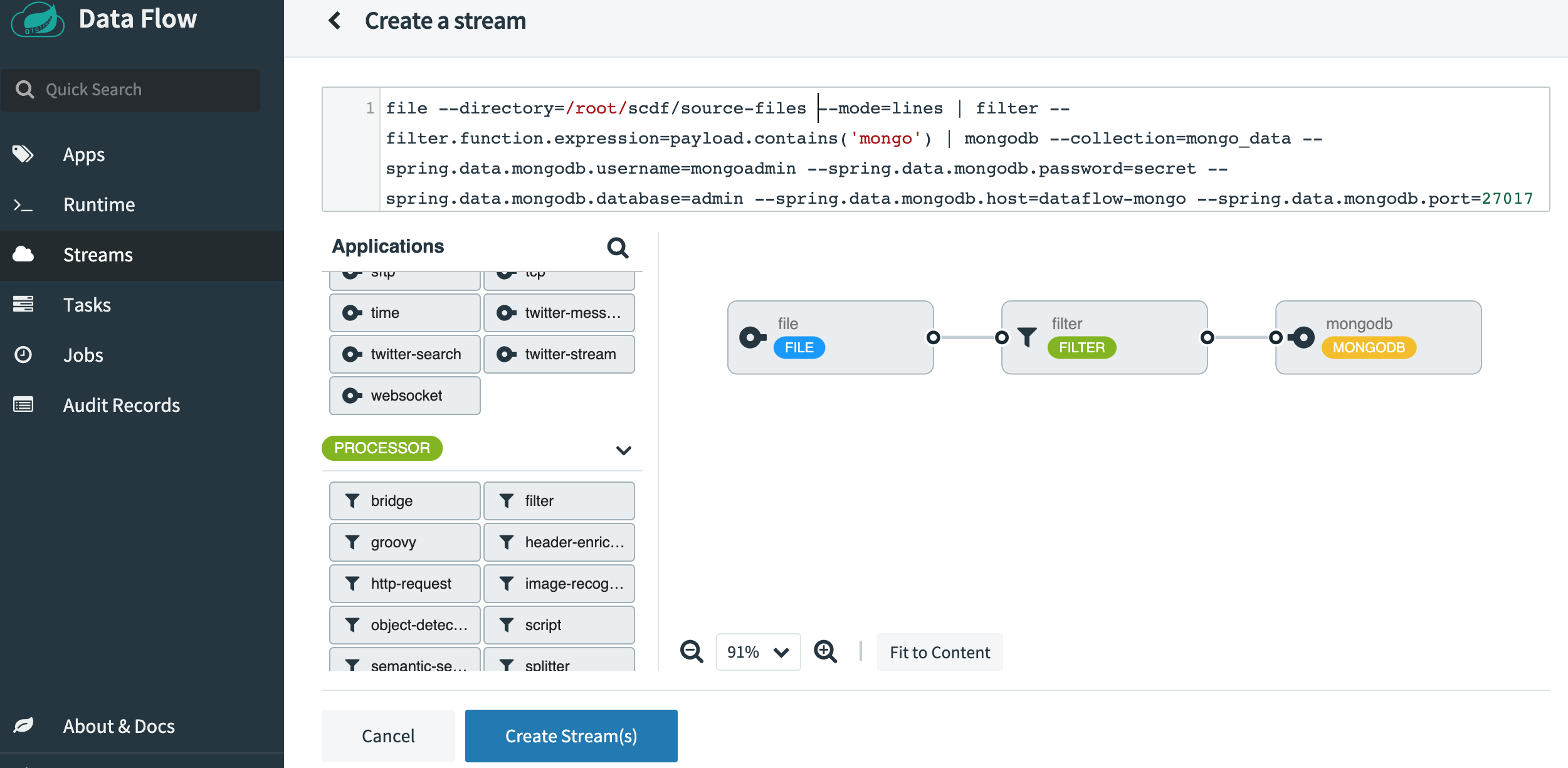
Name the stream as file-source-filter-mongo and then click on Create the Stream. Once it’s created, click on “Deploy the Stream”. Accept all the default options and click on “Deploy Stream” at the bottom of the screen.
Once the stream is deployed, go ahead and create a directory called source-files in the same directory where the Spring Cloud Data Flow docker-compose script was invoked. This directory is already mounted by the docker container that is running one of the Spring Cloud Data Flow components (Skipper) and seen by the container. Ensure that this source-files directory has the right access levels, especially, since the docker container will run the applications as root and you will most likely run as a non-root user on your local machine. Watch the file source application’s logs on the UI for any permission errors. If you see any, address those issues.
Prepare a new terminal session with mongo CLI tool.
docker exec -it dataflow-mongo /bin/sh
# mongo
> use admin
> db.auth(‘mongoadmin’,'secret')
1
> db.createCollection(‘mongo_data’')
{ "ok" : 1 }>
Place some files in the source-files directory with the following contents.
{"non-sql":"mongo"}
{"sql":"mysql"}
{"document":"mongo"}
{"log":"kafka"}
{"sink":"mongo"}
Go to the mongo cli terminal session.
db.mongo_data.find()
You will see that the filtering component we added in the pipeline filtered out all entries in the files that do not contain the word mongo in it. You should see the output similar to the following.
{ "_id" : ObjectId("5f4551c470e0373080fcd0b8"), "non-sql" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b2"), "sink" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b5"), "document" : "mongo" }
In this blog, we took a whirlwind tour through File Supplier and it’s Spring Cloud Stream source counterpart. We also saw the MongoDB consumer and the corresponding Spring Cloud Stream sink application. We looked at how the function components can be injected into custom applications. After that, we saw how to run the Spring Cloud Stream applications for both file source and MongoDB sink standalone. Finally, we delved into Spring Cloud Data Flow and orchestrated a pipeline that goes from File Source to MongoDB sink, on its way filtering some data out.
This blog series is going to continue. In the next coming weeks, we will look at more scenarios similar to what we described in this blog, but with different functions and applications.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all