Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreSpring AI now supports NVIDIA's Large Language Model API, offering integration with a wide range of models. By leveraging NVIDIA's OpenAI-compatible API, Spring AI allows developers to use NVIDIA's LLMs through the familiar Spring AI API.
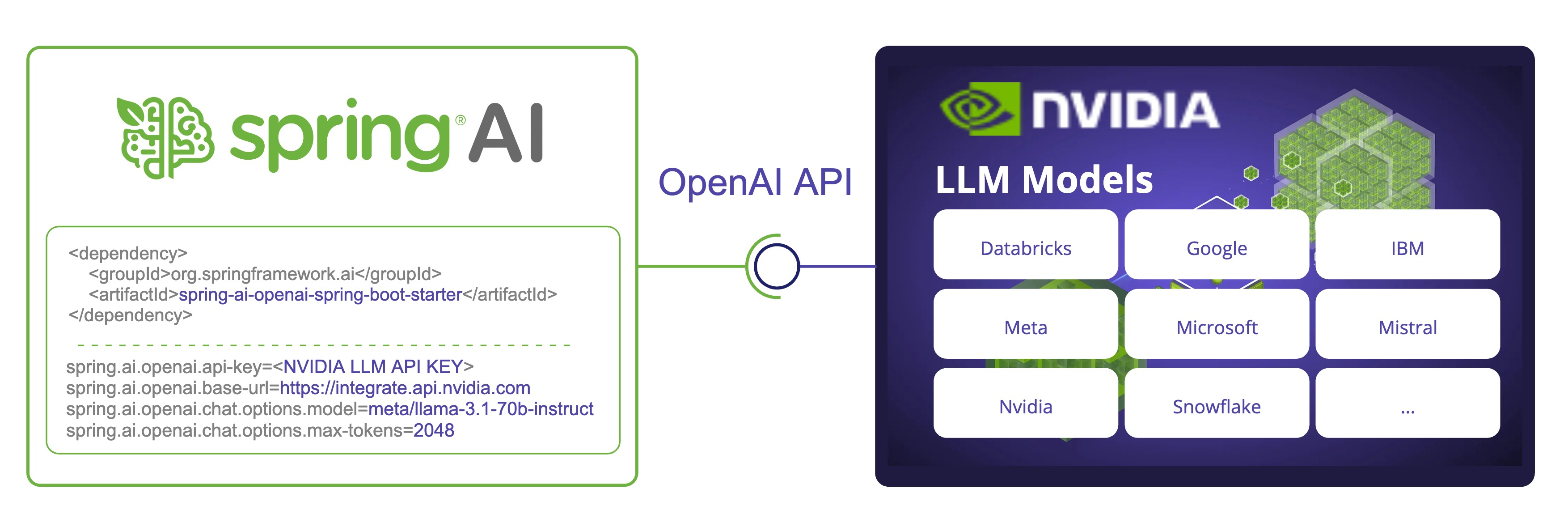
We'll explore how to configure and use the Spring AI OpenAI chat client to connect with NVIDIA LLM API.
meta/llama-3.1-70b-instruct in the screenshot below.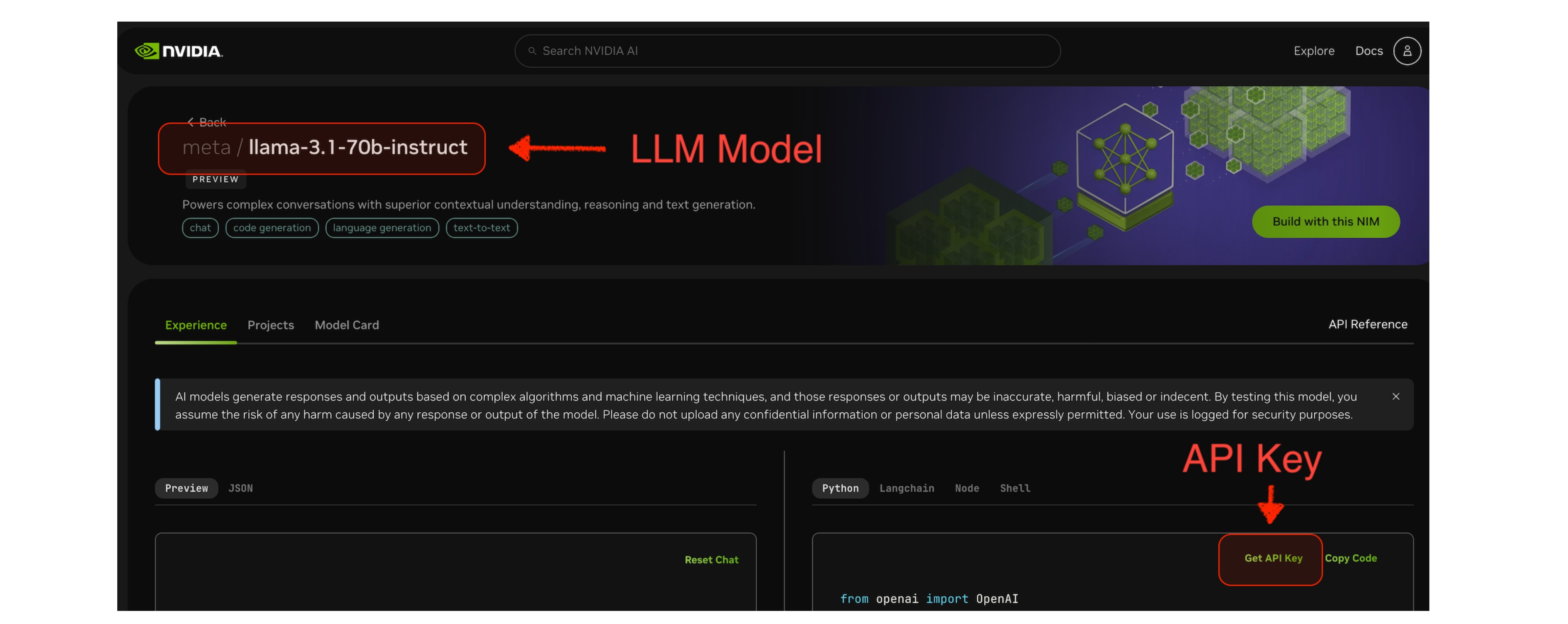
To get started, add the Spring AI OpenAI starter to your project. For Maven, add this to your pom.xml:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
For Gradle, add this to your build.gradle:
gradleCopydependencies {
implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter'
}
Ensure you've added the Spring Milestone and Snapshot repositories and add the Spring AI BOM.
To use NVIDIA LLM API with Spring AI, we need to configure the OpenAI client to point to the NVIDIA LLM API endpoint and use NVIDIA-specific models.
Add the following environment variables to your project:
export SPRING_AI_OPENAI_API_KEY=<NVIDIA_API_KEY>
export SPRING_AI_OPENAI_BASE_URL=https://integrate.api.nvidia.com
export SPRING_AI_OPENAI_CHAT_OPTIONS_MODEL=meta/llama-3.1-70b-instruct
export SPRING_AI_OPENAI_EMBEDDING_ENABLED=false
export SPRING_AI_OPENAI_CHAT_OPTIONS_MAX_TOKENS=2048
Alternatively, you can add these to your application.properties file:
spring.ai.openai.api-key=<NVIDIA_API_KEY>
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings.
spring.ai.openai.embedding.enabled=false
# The NVIDIA LLM API requires this parameter to be set explicitly or error will be thrown.
spring.ai.openai.chat.options.max-tokens=2048
Key points:
api-key is set to your NVIDIA API key.base-url is set to NVIDIA's LLM API endpoint: https://integrate.api.nvidia.commodel is set to one of the models available on NVIDIA's LLM API.max-tokens to be explicitly set or a server error will be thrown.embedding.enabled=false.Check the reference documentation for the complete list of configuration properties.
Now that we've configured Spring AI to use NVIDIA LLM API, let's look at a simple example of how to use it in your application.
@RestController
public class ChatController {
private final ChatClient chatClient;
@Autowired
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/ai/generate")
public String generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).call().content();
}
@GetMapping("/ai/generateStream")
public Flux<String> generateStream(
@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).stream().content();
}
}
In the ChatController.java example, we've created a simple REST controller with two endpoints:
/ai/generate: Generates a single response to a given prompt./ai/generateStream: Streams the response, which can be useful for longer outputs or real-time interactions.NVIDIA LLM API endpoints support tool/function calling when selecting one of the Tool/Function supporting models.
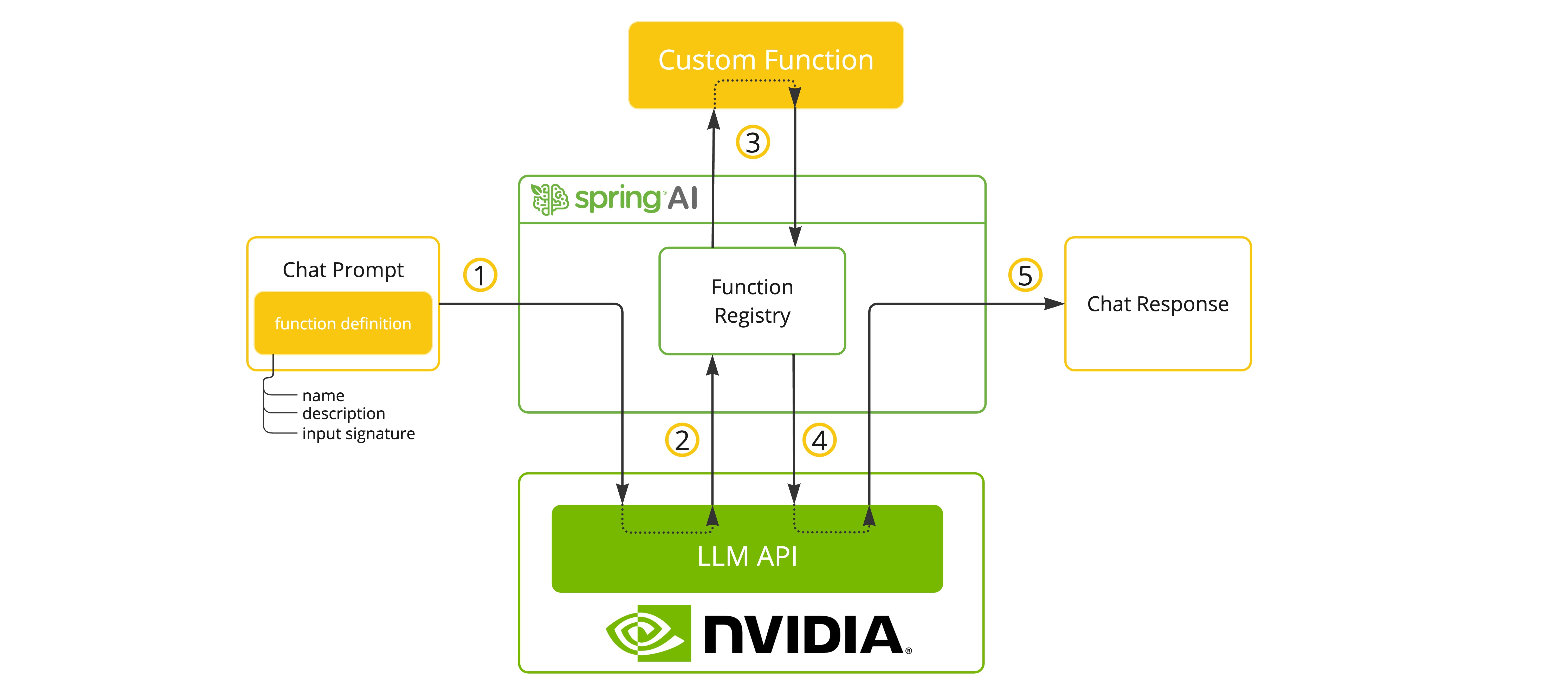
You can register custom Java functions with your ChatModel and have the provided LLM model intelligently choose to output a JSON object containing arguments to call one or many of the registered functions. This is a powerful technique to connect the LLM capabilities with external tools and APIs.
Find more about SpringAI/OpenAI Function Calling support.
Here's a simple example of how to use too/function calling with Spring AI:
@SpringBootApplication
public class NvidiaLlmApplication {
public static void main(String[] args) {
SpringApplication.run(NvidiaLlmApplication.class, args);
}
@Bean
CommandLineRunner runner(ChatClient.Builder chatClientBuilder) {
return args -> {
var chatClient = chatClientBuilder.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.functions("weatherFunction") // reference by bean name.
.call()
.content();
System.out.println(response);
};
}
@Bean
@Description("Get the weather in location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return new MockWeatherService();
}
public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> {
public record WeatherRequest(String location, String unit) {}
public record WeatherResponse(double temp, String unit) {}
@Override
public WeatherResponse apply(WeatherRequest request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new WeatherResponse(temperature, request.unit);
}
}
}
In the NvidiaLlmApplication.java example, when the model needs weather information, it will automatically call the weatherFunction bean, which can then fetch real-time weather data.
The expected response looks like this:
The weather in Amsterdam is currently 20 degrees Celsius, and the weather in Paris is currently 25 degrees Celsius.
When using NVIDIA LLM API with Spring AI, keep the following points in mind:
For further information check the Spring AI and OpenAI reference documentations.
Integrating NVIDIA LLM API with Spring AI opens up new possibilities for developers looking to leverage high-performance AI models in their Spring applications. By repurposing the OpenAI client, Spring AI makes it straightforward to switch between different AI providers, allowing you to choose the best solution for your specific needs.
As you explore this integration, remember to stay updated with the latest documentation from both Spring AI and NVIDIA LLM API, as features and model availability may evolve over time.
We encourage you to experiment with different models and compare their performance and outputs to find the best fit for your use case.
Happy coding, and enjoy the speed and capabilities that NVIDIA LLM API brings to your AI-powered Spring applications!

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all