Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreIn this two-parts blog post, I will discuss the modifications I made to Spring Petclinic to incorporate an AI assistant that allows users to interact with the application using natural language.
Spring Petclinic serves as the primary reference application within the Spring ecosystem. According to GitHub, the repository was created on January 9, 2013. Since then, it has become the model application for writing simple, developer-friendly code using Spring Boot. As of this writing, it has garnered over 7,600 stars and 23,000 forks.
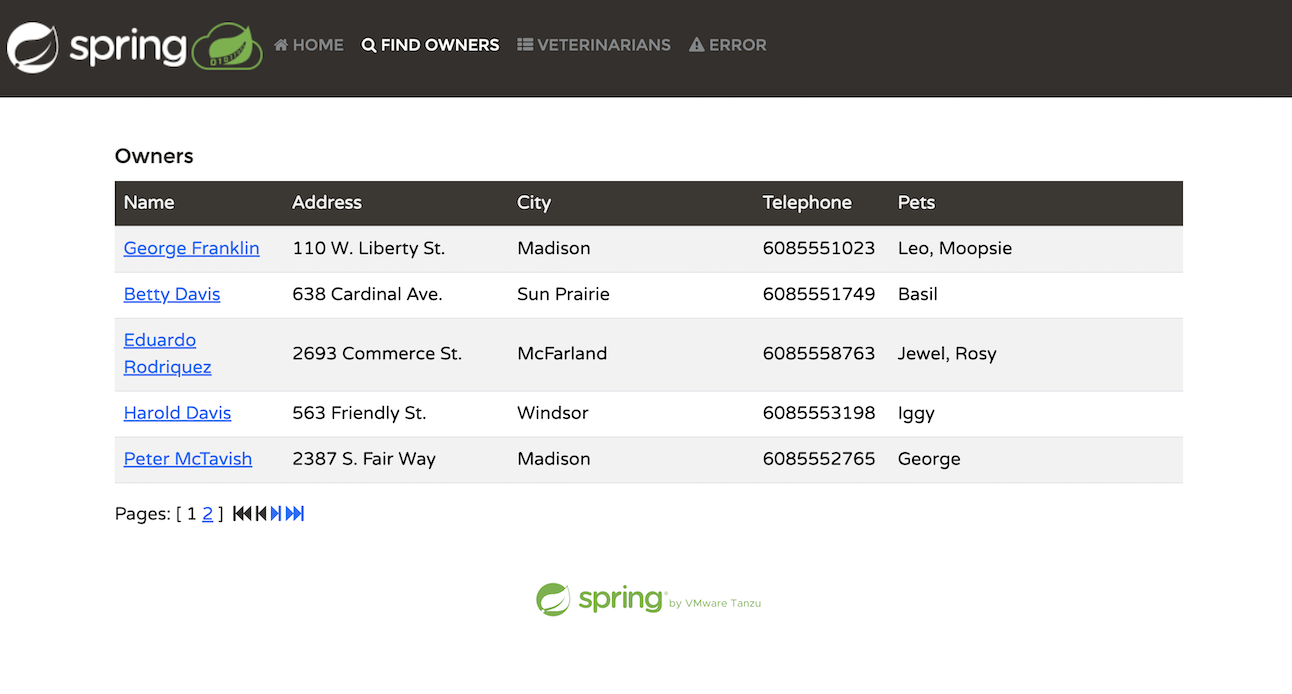
The application simulates a management system for a veterinarian’s pet clinic. Within the application, users can perform several activities:
List pet owners
Add a new owner
Add a pet to an owner
Document a visit for a specific pet
List the veterinarians in the clinic
Simulate a server-side error
While the application is simple and straightforward, it effectively showcases the ease of use associated with developing Spring Boot applications.
Additionally, the Spring team has continuously updated the app to support the latest versions of the Spring Framework and Spring Boot.
Spring Petclinic is developed using Spring Boot, specifically version 3.3 as of this publication.
The frontend UI is built using Thymeleaf. Thymeleaf's templating engine facilitates seamless backend API calls within the HTML code, making it easy to understand. Below is the code that retrieves the list of pet owners:
<table id="vets" class="table table-striped">
<thead>
<tr>
<th>Name</th>
<th>Specialties</th>
</tr>
</thead>
<tbody>
<tr th:each="vet : ${listVets}">
<td th:text="${vet.firstName + ' ' + vet.lastName}"></td>
<td><span th:each="specialty : ${vet.specialties}"
th:text="${specialty.name + ' '}"/> <span
th:if="${vet.nrOfSpecialties == 0}">none</span></td>
</tr>
</tbody>
</table>
The key line here is ${listVets}, which references a model in the Spring backend that contains the data to be populated. Below is the relevant code block from the Spring @Controller that populates this model:
private String addPaginationModel(int page, Page<Vet> paginated, Model model) {
List<Vet> listVets = paginated.getContent();
model.addAttribute("currentPage", page);
model.addAttribute("totalPages", paginated.getTotalPages());
model.addAttribute("totalItems", paginated.getTotalElements());
model.addAttribute("listVets", listVets);
return "vets/vetList";
}
Petclinic interacts with the database using the Java Persistence API (JPA). It supports H2, PostgreSQL, or MySQL, depending on the selected profile. Database communication is facilitated through @Repository interfaces, such as OwnerRepository. Here’s an example of one of the JPA queries within the interface:
/**
* Returns all the owners from data store
**/
@Query("SELECT owner FROM Owner owner")
@Transactional(readOnly = true)
Page<Owner> findAll(Pageable pageable);
JPA significantly simplifies your code by automatically implementing default queries for your methods based on naming conventions. It also allows you to specify a JPQL query using the @Query annotation when needed.
Spring AI is one of the most exciting new projects in the Spring ecosystem in recent memory. It enables interaction with popular large language models (LLMs) using familiar Spring paradigms and techniques. Much like Spring Data provides an abstraction that allows you to write your code once, delegating implementation to the provided spring-boot-starter dependency and property configuration, Spring AI offers a similar approach for LLMs. You write your code once to an interface, and a @Bean is injected at runtime for your specific implementation.
Spring AI supports all the major large language models, including OpenAI, Azure’s OpenAI implementation, Google Gemini, Amazon Bedrock, and many more.
Spring Petclinic is over 10 years old and was not originally designed with AI in mind. It serves as a classic candidate for testing the integration of AI into a “legacy” codebase. In approaching the challenge of adding an AI assistant to Spring Petclinic, I had to consider several important factors.
The first consideration was determining the type of API I wanted to implement. Spring AI offers a variety of capabilities, including support for chat, image recognition and generation, audio transcription, text-to-speech, and more. For Spring Petclinic, a familiar “chatbot” interface made the most sense. This would allow clinic employees to communicate with the system in natural language, streamlining their interactions instead of navigating through UI tabs and forms. I would also need embedding capabilities, which will be used for Retrieval-Augmented Generation (RAG) later in the article.

Possible interactions with the AI assistant may include:
How can you assist me?
Please list the owners that come to our clinic.
Which vets specialize in radiology?
Is there a pet owner named Betty?
Which of the owners have dogs?
Add a dog for Betty; its name is Moopsie.
These examples illustrate the range of queries the AI can handle. The strength of LLMs lies in their ability to comprehend natural language and provide meaningful responses.
The tech world is currently experiencing a gold rush with large language models (LLMs), with new models emerging every few days, each offering enhanced capabilities, larger context windows, and advanced features such as improved reasoning.
Some of the popular LLMs include:
OpenAI and its Azure-based service, Azure OpenAI
Google Gemini
Amazon Bedrock, a managed AWS service that can run various LLMs, including Anthropic and Titan
Llama 3.1, along with many other open-source LLMs available through Hugging Face
For our Petclinic application, I required a model that excels in chat capabilities, can be tailored to my application’s specific needs, and supports function calling (more on that later!).
One of the great advantages of Spring AI is the ease of conducting A/B testing with various LLMs. You simply change a dependency and update a few properties. I tested several models, including Llama 3.1, which I ran locally. Ultimately, I concluded that OpenAI remains the leader in this space, as it provides the most natural and fluent interactions while avoiding common pitfalls encountered by other LLMs.
Here’s a basic example: when greeting the model powered by OpenAI, the response is as follows:
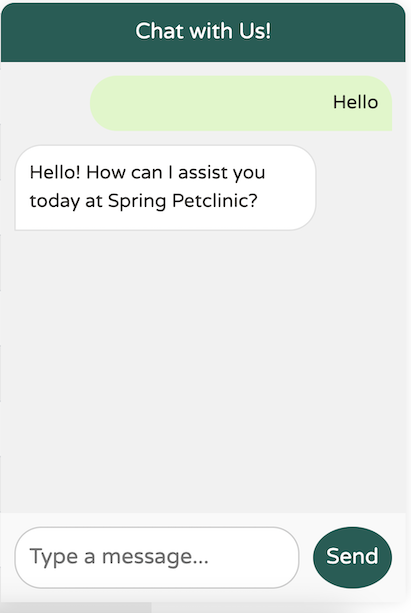
Perfect. Just what I wanted. Simple, concise, professional and user friendly.
Here’s the result using Llama3.1:
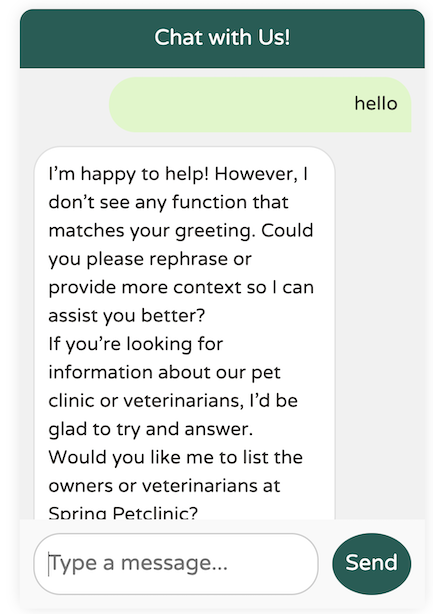
You get the point. It’s just not there yet.
Setting the desired LLM provider is straightforward - simply set its dependency in the pom.xml (or build.gradle) and provide the necessary configuration properties in application.yaml or application.properties:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId>
</dependency>
Here, I opted for Azure’s implementation of OpenAI, but I could easily switch to Sam Altman’s OpenAI by changing the dependency:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
Since I’m using a publicly hosted LLM provider, I need to provide the URL and API key to access the LLM. This can be configured in application.yaml:
spring:
ai:
#These parameters apply when using the spring-ai-azure-openai-spring-boot-starter dependency:
azure:
openai:
api-key: "the-api-key"
endpoint: "https://the-url/"
chat:
options:
deployment-name: "gpt-4o"
#These parameters apply when using the spring-ai-openai-spring-boot-starter dependency:
openai:
api-key: ""
endpoint: ""
chat:
options:
deployment-name: "gpt-4o"
Our goal is to create a WhatsApp/iMessage-style chat client that integrates with the existing UI of Spring Petclinic. The frontend UI will make calls to a backend API endpoint that accepts a string as input and returns a string as output. The conversation will be open to any questions the user may have, and if we can't assist with a particular request, we'll provide an appropriate response.
Here’s the implementation for the chat endpoint in the class PetclinicChatClient:
@PostMapping("/chatclient")
public String exchange(@RequestBody String query) {
//All chatbot messages go through this endpoint and are passed to the LLM
return
this.chatClient
.prompt()
.user(
u ->
u.text(query)
)
.call()
.content();
}
The API accepts a string query and passes it to the Spring AI ChatClient bean as user text. The ChatClient is a Spring Bean provided by Spring AI that manages sending the user text to the LLM and returning the results in the content().
All the Spring AI code operates under a specific
@Profilecalledopenai. An additional class,PetclinicDisabledChatClient, runs when using the default profile or any other profile. This disabled profile simply returns a message indicating that chat is not available.
Our implementation primarily delegates responsibility to the ChatClient. But how do we create the ChatClient bean itself? There are several configurable options that can influence the user experience. Let’s explore them one by one and examine their impact on the final application:
Here’s a barebones, unaltered ChatClient bean definition:
public PetclinicChatClient(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
Here, we simply request an instance of the ChatClient from the builder, based on the currently available Spring AI starter in the dependencies. While this setup works, our chat client lacks any knowledge of the Petclinic domain or its services:
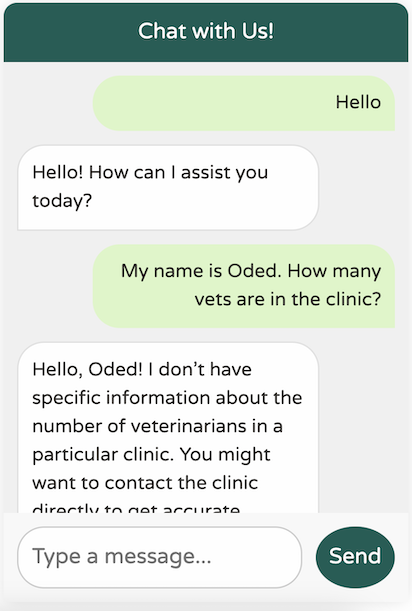
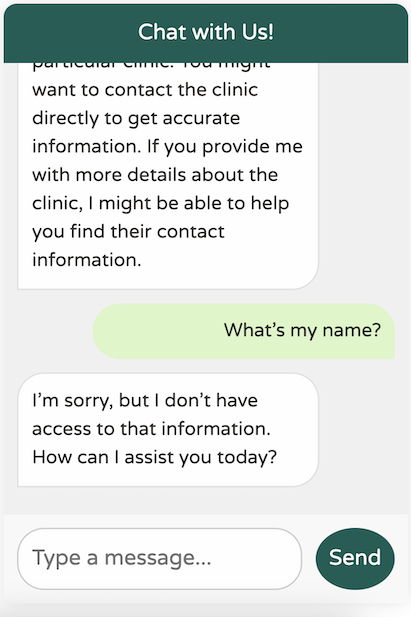
It’s certainly polite, but it lacks any understanding of our business domain. Additionally, it seems to suffer from a severe case of amnesia—it can't even remember my name from the previous message!
As I reviewed this article, I realized I’m not following the advice of my good friend and colleague Josh Long. I should probably be more polite to our new AI overlords!
You might be accustomed to ChatGPT's excellent memory, which makes it feel conversational. In reality, however, LLM APIs are entirely stateless and do not retain any of the past messages you send. This is why the API forgot my name so quickly.
You may be wondering how ChatGPT maintains conversational context. The answer is simple: ChatGPT sends past messages as content along with each new message. Every time you send a new message, it includes the previous conversations for the model to reference. While this might seem wasteful, it’s just how the system operates. This is also why larger token windows are becoming increasingly important—users expect to revisit conversations from days ago and pick up right where they left off.
Let’s implement a similar “chat memory” functionality in our application. Fortunately, Spring AI provides an out-of-the-box Advisor to help with this. You can think of advisors as hooks that run before invoking the LLM. It’s helpful to consider them as resembling Aspect-Oriented Programming advice, even if they aren’t implemented that way.
Here’s our updated code:
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new SimpleLoggerAdvisor()
)
.build();
}
In this updated code, we added the MessageChatMemoryAdvisor, which automatically chains the last 10 messages into any new outgoing message, helping the LLM understand the context.
We also included an out-of-the-box SimpleLoggerAdvisor, which logs the requests and responses to and from the LLM.
The result:

Our new chatbot has significantly better memory!
However, it’s still not entirely clear on what we’re really doing here:
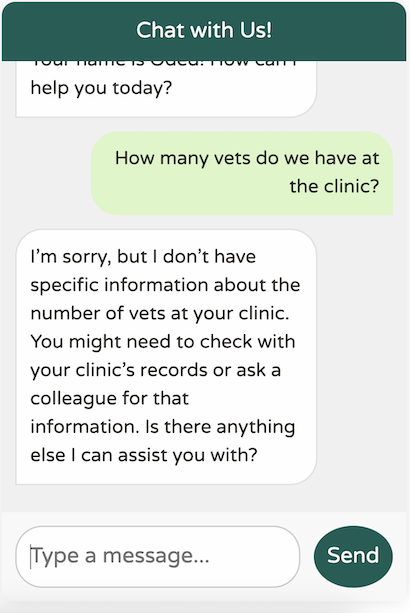
This response is decent for a generic world-knowledge LLM. However, our clinic is very domain-specific, with particular use cases. Additionally, our chatbot should focus solely on assisting us with our clinic. For example, it should not attempt to answer a question like this:

If we allowed our chatbot to answer any question, users might start using it as a free alternative to services like ChatGPT to access more advanced models like GPT-4. It’s clear that we need to teach our LLM to “impersonate” a specific service provider. Our LLM should focus solely on assisting with Spring Petclinic; it should know about vets, owners, pets, and visits—nothing more.
Spring AI offers a solution for this as well. Most LLMs differentiate between user text (the chat messages we send) and system text, which is general text that instructs the LLM to function in a specific manner. Let’s add the system text to our chat client:
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultSystem("""
You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
""")
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new LoggingAdvisor()
)
.build();
}
That's quite a verbose default system prompt! But trust me, it’s necessary. In fact, it’s probably not enough, and as the system is used more frequently, I’ll likely need to add more context. The process of prompt engineering involves designing and optimizing input prompts to elicit specific, accurate responses for a given use case.
LLMs are quite chatty; they enjoy responding in natural language. This tendency can make it challenging to get machine-to-machine responses in formats like JSON. To address this, Spring AI offers a feature set dedicated to structured output, known as the Structured Output Converter. The Spring team had to identify optimal prompt engineering techniques to ensure that LLMs respond without unnecessary “chattiness.” Here’s an example from Spring AI’s MapOutputConverter bean:
@Override
public String getFormat() {
String raw = """
Your response should be in JSON format.
The data structure for the JSON should match this Java class: %s
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Remove the ```json markdown surrounding the output including the trailing "```".
""";
return String.format(raw, HashMap.class.getName());
}
Whenever a response from an LLM needs to be in JSON format, Spring AI appends this entire string to the request, urging the LLM to comply.
Recently, there have been positive advancements in this area, particularly with OpenAI’s Structured Outputs initiative. As is often the case with such advancements, Spring AI has embraced it wholeheartedly.
Now, back to our chatbot—let’s see how it performs!
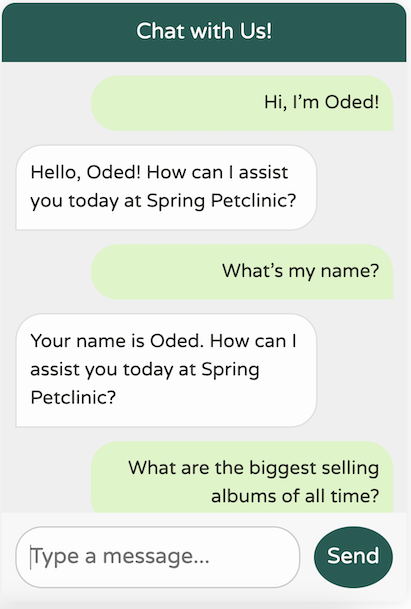
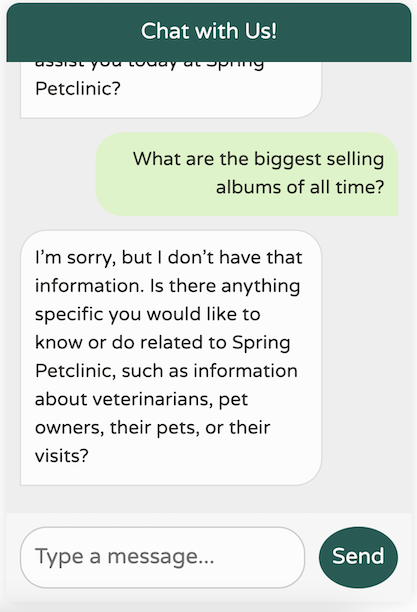
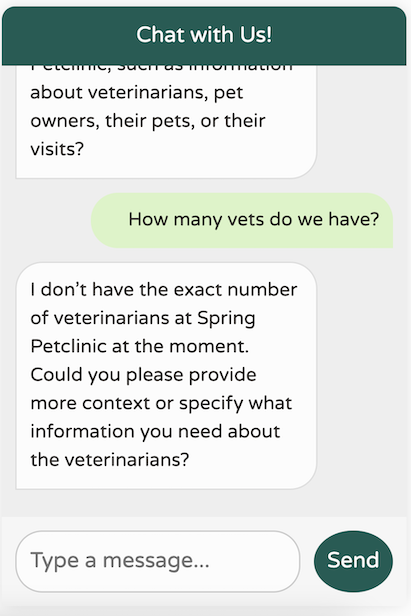
That’s a significant improvement! We now have a chatbot that’s tuned to our domain, focused on our specific use cases, remembers the last 10 messages, doesn’t provide any irrelevant world knowledge, and avoids hallucinating data it doesn’t possess. Additionally, our logs print the calls we’re making to the LLM, making debugging much easier.
2024-09-21T21:55:08.888+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@5cdd90c4, userText="Hi! My name is Oded.", systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
, chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@c4c74d4, media=[], functionNames=[], functionCallbacks=[], messages=[], userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1e561f7, org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@79348b22], advisorParams={}]
2024-09-21T21:55:10.594+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {"result":{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}},"metadata":{"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","model":"gpt-4o-2024-05-13","rateLimit":{"requestsLimit":0,"requestsRemaining":0,"requestsReset":0.0,"tokensRemaining":0,"tokensLimit":0,"tokensReset":0.0},"usage":{"promptTokens":633,"generationTokens":17,"totalTokens":650},"promptMetadata":[{"contentFilterMetadata":{"sexual":null,"violence":null,"hate":null,"selfHarm":null,"profanity":null,"customBlocklists":null,"error":null,"jailbreak":null,"indirectAttack":null},"promptIndex":0}],"empty":false},"results":[{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}}]}
Our chatbot behaves as expected, but it currently lacks knowledge about the data in our application. Let’s focus on the core features that Spring Petclinic supports and map them to the functions we might want to enable with Spring AI:
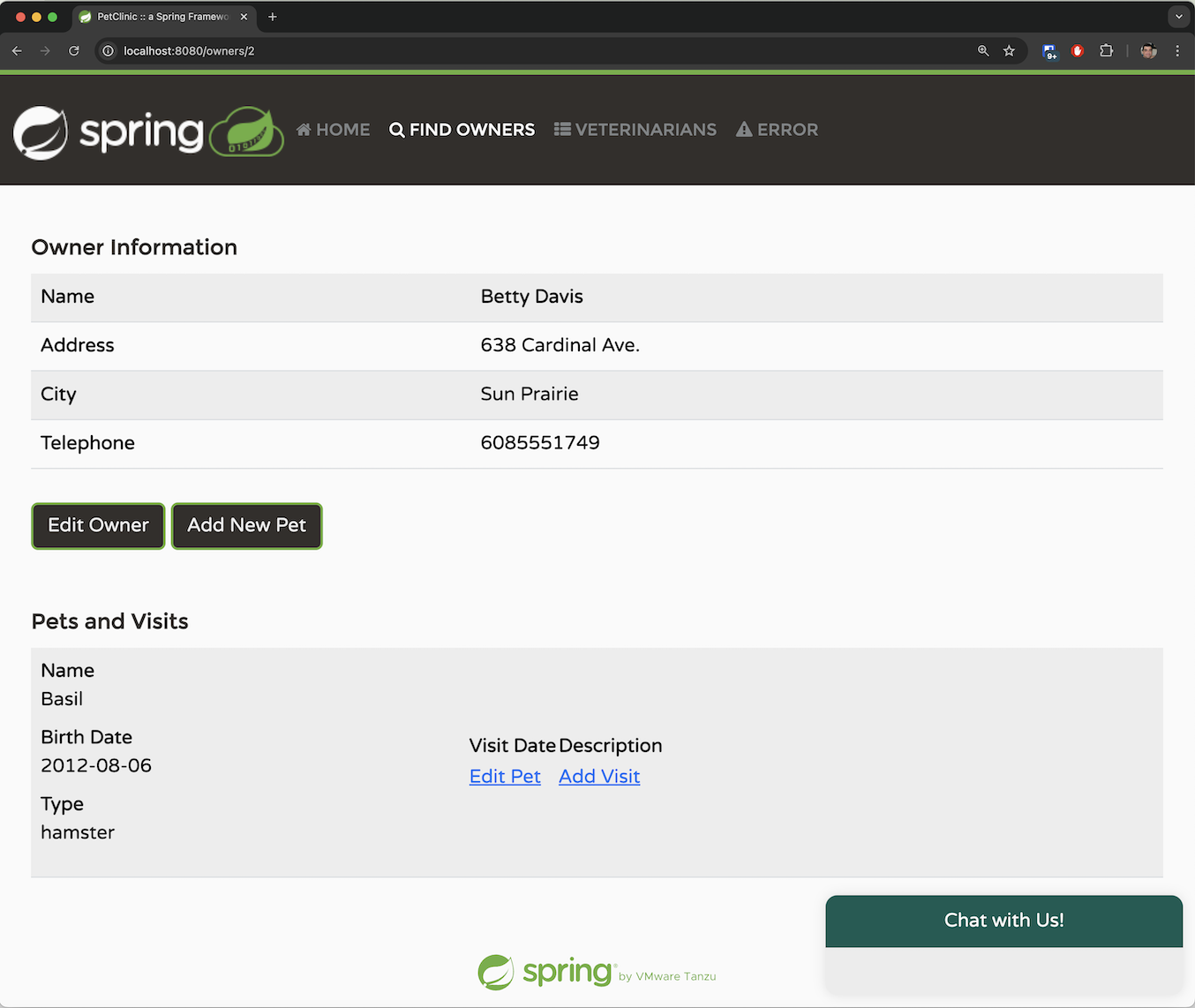
In the Owners tab, we can search for an owner by last name or simply list all owners. We can obtain detailed information about each owner, including their first and last names, as well as the pets they own and their types:
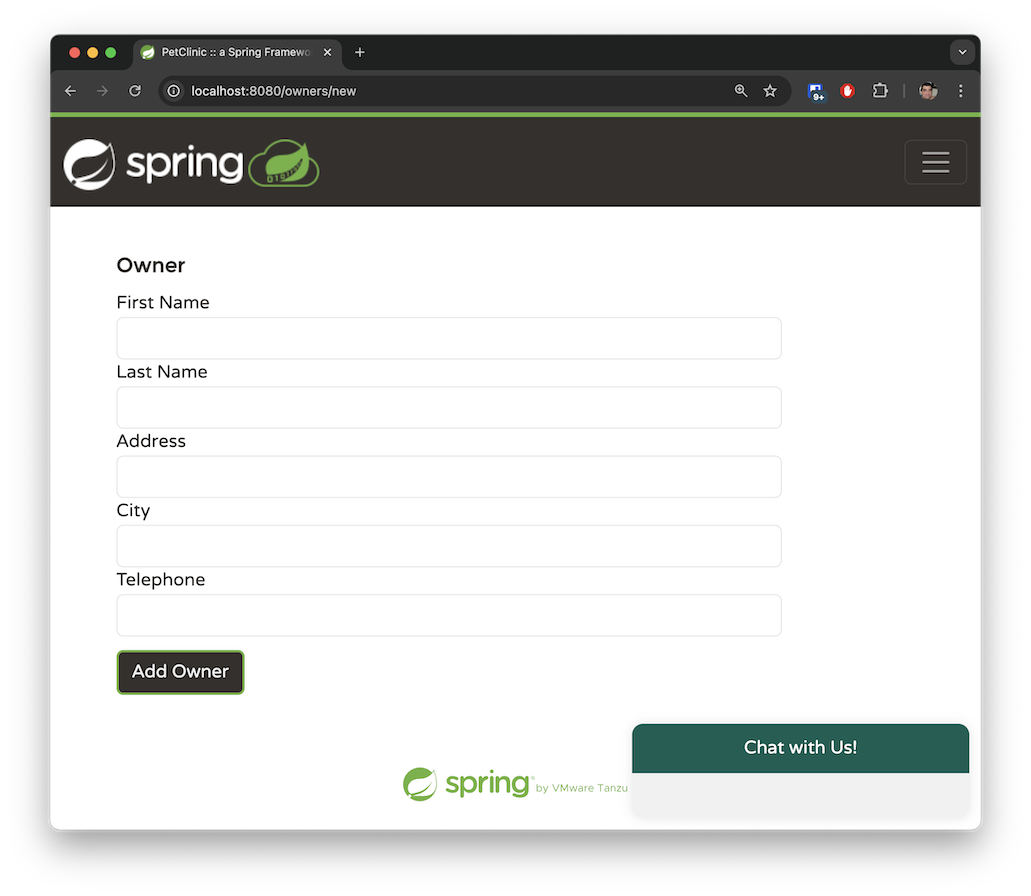
The application allows you to add a new owner by providing the required parameters dictated by the system. An owner must have a first name, a last name, an address, and a 10-digit phone number.
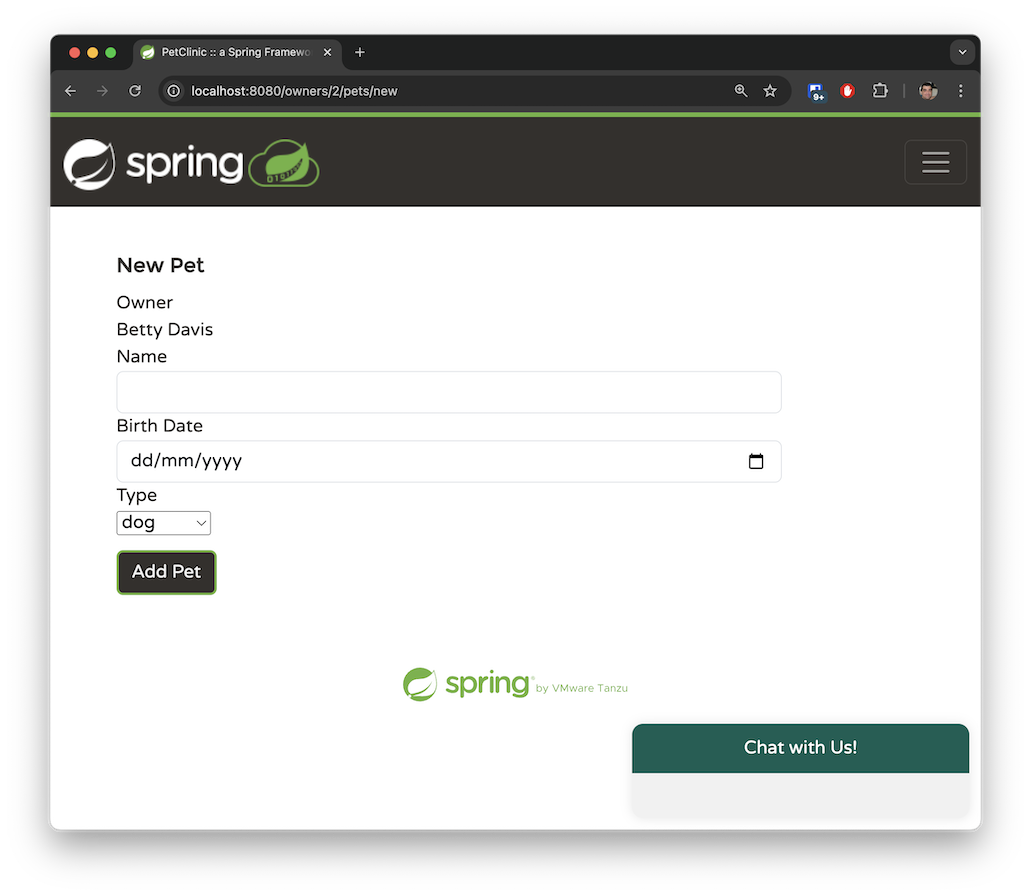
An owner can have multiple pets. The pet types are limited to the following: cat, dog, lizard, snake, bird, or hamster.
The Veterinarians tab displays the available veterinarians in a paginated view, along with their specialties. There is currently no search capability in this tab. While the main branch of Spring Petclinic features a handful of vets, I generated hundreds of mock vets in the spring-ai branch to simulate an application that handles a substantial amount of data. Later, we will explore how we can use Retrieval-Augmented Generation (RAG) to manage large datasets such as this.
These are the main operations we can perform in the system. We’ve mapped our application to its basic functions, and we’d like OpenAI to infer requests in natural language corresponding to these operations.
In the previous section, we described four different functions. Now, let’s map them to functions we can use with Spring AI by specifying specific java.util.function.Function beans.
The following java.util.function.Function is responsible for returning the list of owners in Spring Petclinic:
@Configuration
@Profile("openai")
class AIFunctionConfiguration {
// The @Description annotation helps the model understand when to call the function
@Bean
@Description("List the owners that the pet clinic has")
public Function<OwnerRequest, OwnersResponse> listOwners(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.getAllOwners();
};
}
}
record OwnerRequest(Owner owner) {
};
record OwnersResponse(List<Owner> owners) {
};
We’re creating a @Configuration class in the openai profile, where we register a standard Spring @Bean.
The bean must return a java.util.function.Function.
We use Spring's @Description annotation to explain what this function does. Notably, Spring AI will pass this description to the LLM to help it determine when to call this specific function.
The function accepts an OwnerRequest record, which holds the existing Spring Petclinic Owner entity class. This demonstrates how Spring AI can leverage components you've already developed in your application without requiring a complete rewrite.
OpenAI will decide when to invoke the function with a JSON object representing the OwnerRequest record. Spring AI will automatically convert this JSON into an OwnerRequest object and execute the function. Once a response is returned, Spring AI will convert the resulting OwnerResponse record—which holds a List<Owner>—back to JSON format for OpenAI to process. When OpenAI receives the response, it will craft a reply for the user in natural language.
The function calls an AIDataProvider @Service bean that implements the actual logic. In our simple use case, the function merely queries the data using JPA:
public OwnersResponse getAllOwners() {
Pageable pageable = PageRequest.of(0, 100);
Page<Owner> ownerPage = ownerRepository.findAll(pageable);
return new OwnersResponse(ownerPage.getContent());
}
The existing legacy code of Spring Petclinic returns paginated data to keep the response size manageable and facilitate processing for the paginated view in the UI. In our case, we expect the total number of owners to be relatively small, and OpenAI should be able to handle such traffic in a single request. Therefore, we return the first 100 owners in a single JPA request.
You may be thinking that this approach isn't optimal, and in a real-world application, you would be correct. If there were a large amount of data, this method would be inefficient—it's likely we’d have more than 100 owners in the system. For such scenarios, we would need to implement a different pattern, as we will explore in the listVets function. However, for our demo use case, we can assume our system contains fewer than 100 owners.
Let’s use a real example along with the SimpleLoggerAdvisor to observe what happens behind the scenes:
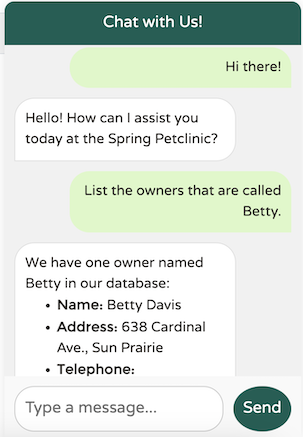
What happened here? Let’s review the output from the SimpleLoggerAdvisor log to investigate:
request:
AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@18e69455,
userText=
"List the owners that are called Betty.",
systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job...
chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@3d6f2674,
media=[],
functionNames=[],
functionCallbacks=[],
messages=[UserMessage{content='"Hi there!"',
properties={messageType=USER},
messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[],
textContent=Hello! How can I assist you today at Spring Petclinic?,
metadata={choiceIndex=0, finishReason=stop, id=chatcmpl-A99D20Ql0HbrpxYc0LIkWZZLVIAKv,
messageType=ASSISTANT}]],
userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1d04fb8f,
org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@2fab47ce], advisorParams={}]
The request contains interesting data about what is sent to the LLM, including the user text, historical messages, an ID representing the current chat session, the list of advisors to trigger, and the system text.
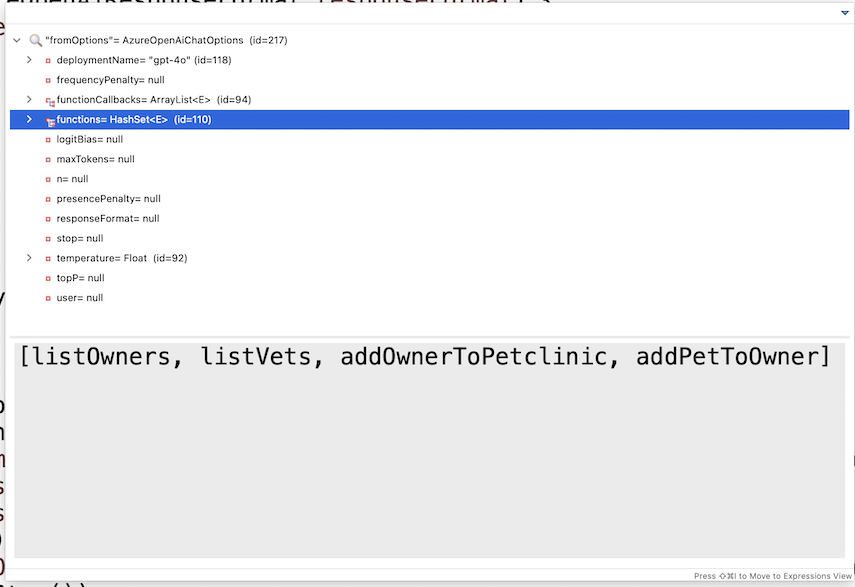
You might be wondering where the functions are in the logged request above. The functions are not explicitly logged; they are encapsulated within the contents of AzureOpenAiChatOptions. Examining the object in debug mode reveals the list of functions available to the model:
OpenAI will process the request, determine that it requires data from the list of owners, and return a JSON reply to Spring AI requesting additional information from the listOwners function. Spring AI will then invoke that function using the provided OwnersRequest object from OpenAI and send the response back to OpenAI, maintaining the conversation ID to assist with session continuity over the stateless connection. OpenAI will generate the final response based on the additional data provided. Let’s review that response as it is logged:
response: {
"result": {
"metadata": {
"finishReason": "stop",
"contentFilterMetadata": {
"sexual": {
"severity": "safe",
"filtered": false
},
"violence": {
"severity": "safe",
"filtered": false
},
"hate": {
"severity": "safe",
"filtered": false
},
"selfHarm": {
"severity": "safe",
"filtered": false
},
"profanity": null,
"customBlocklists": null,
"error": null,
"protectedMaterialText": null,
"protectedMaterialCode": null
}
},
"output": {
"messageType": "ASSISTANT",
"metadata": {
"choiceIndex": 0,
"finishReason": "stop",
"id": "chatcmpl-A9oKTs6162OTut1rkSKPH1hE2R08Y",
"messageType": "ASSISTANT"
},
"toolCalls": [],
"content": "The owner named Betty in our records is:\n\n- **Betty Davis**\n - **Address:** 638 Cardinal Ave., Sun Prairie\n - **Telephone:** 608-555-1749\n - **Pet:** Basil (Hamster), born on 2012-08-06\n\nIf you need any more details or further assistance, please let me know!"
}
},
...
]
}
We see the response itself in the content section. Most of the returned JSON consists of metadata—such as content filters, the model being used, the chat ID session in the response, the number of tokens consumed, how the response completed, and more.
This illustrates how the system operates end-to-end: it starts in your browser, reaches the Spring backend, and involves a B2B ping-pong interaction between Spring AI and the LLM until a response is sent back to the JavaScript that made the initial call.
Now, let’s review the remaining three functions.
The addPetToOwner method is particularly interesting because it demonstrates the power of the model’s function calling.
When a user wants to add a pet to an owner, it’s unrealistic to expect them to input the pet type ID. Instead, they are likely to say the pet is a "dog" rather than simply providing a numeric ID like "2”.
To assist the LLM in determining the correct pet type, I utilized the @Description annotation to provide hints about our requirements. Since our pet clinic only deals with six types of pets, this approach is manageable and effective:
@Bean
@Description("Add a pet with the specified petTypeId, " + "to an owner identified by the ownerId. "
+ "The allowed Pet types IDs are only: " + "1 - cat" + "2 - dog" + "3 - lizard" + "4 - snake" + "5 - bird"
+ "6 - hamster")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
The AddPetRequest record includes the pet type in free text, reflecting how a user would typically provide it, along with the complete Pet entity and the referenced ownerId.
record AddPetRequest(Pet pet, String petType, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
Here’s the business implementation: we retrieve the owner by their ID and then add the new pet to their existing list of pets.
public AddedPetResponse addPetToOwner(AddPetRequest request) {
Owner owner = ownerRepository.findById(request.ownerId());
owner.addPet(request.pet());
this.ownerRepository.save(owner);
return new AddedPetResponse(owner);
}
While debugging the flow for this article, I noticed an interesting behavior: in some cases, the Pet entity in the request was already prepopulated with the correct pet type ID and name.
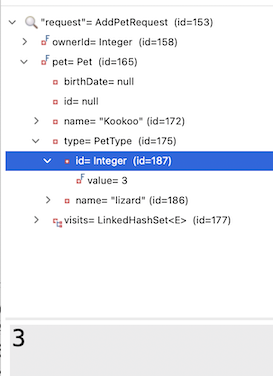
I also noticed that I wasn't really using the petType String in my business implementation. Is it possible that Spring AI simply "figured out" the correct mapping of the PetType name to the correct ID on its own?
To test this, I removed the petType from my request object and simplified the @Description as well:
@Bean
@Description("Add a pet with the specified petTypeId, to an owner identified by the ownerId.")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
record AddPetRequest(Pet pet, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
I found that in most prompts, the LLM remarkably figured out how to perform the mapping on its own. I eventually did keep the original description in the PR, because I noticed some edge cases where the LLM struggled and failed to understand the correlation.
Still, even for 80% of the use cases, this was very impressive. These are the sort of things that make Spring AI and LLMs almost feel like magic. The interaction between Spring AI and OpenAI managed to understand that the PetType in the @Entity of Pet needed the mapping of the String "lizard" to its corresponding ID value in the database. This kind of seamless integration showcases the potential of combining traditional programming with AI capabilities.
// These are the original insert queries in data.sql
INSERT INTO types VALUES (default, 'cat'); //1
INSERT INTO types VALUES (default, 'dog'); //2
INSERT INTO types VALUES (default, 'lizard'); //3
INSERT INTO types VALUES (default, 'snake'); //4
INSERT INTO types VALUES (default, 'bird'); //5
INSERT INTO types VALUES (default, 'hamster'); //6
@Entity
@Table(name = "pets")
public class Pet extends NamedEntity {
private static final long serialVersionUID = 622048308893169889L;
@Column(name = "birth_date")
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate birthDate;
@ManyToOne
@JoinColumn(name = "type_id")
private PetType type;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "pet_id")
@OrderBy("visit_date ASC")
private Set<Visit> visits = new LinkedHashSet<>();
It even works if you make some typos in the request. In the example below, the LLM identified that I misspelled "hamster" as "hamstr," corrected the request, and successfully matched it with the correct Pet ID:
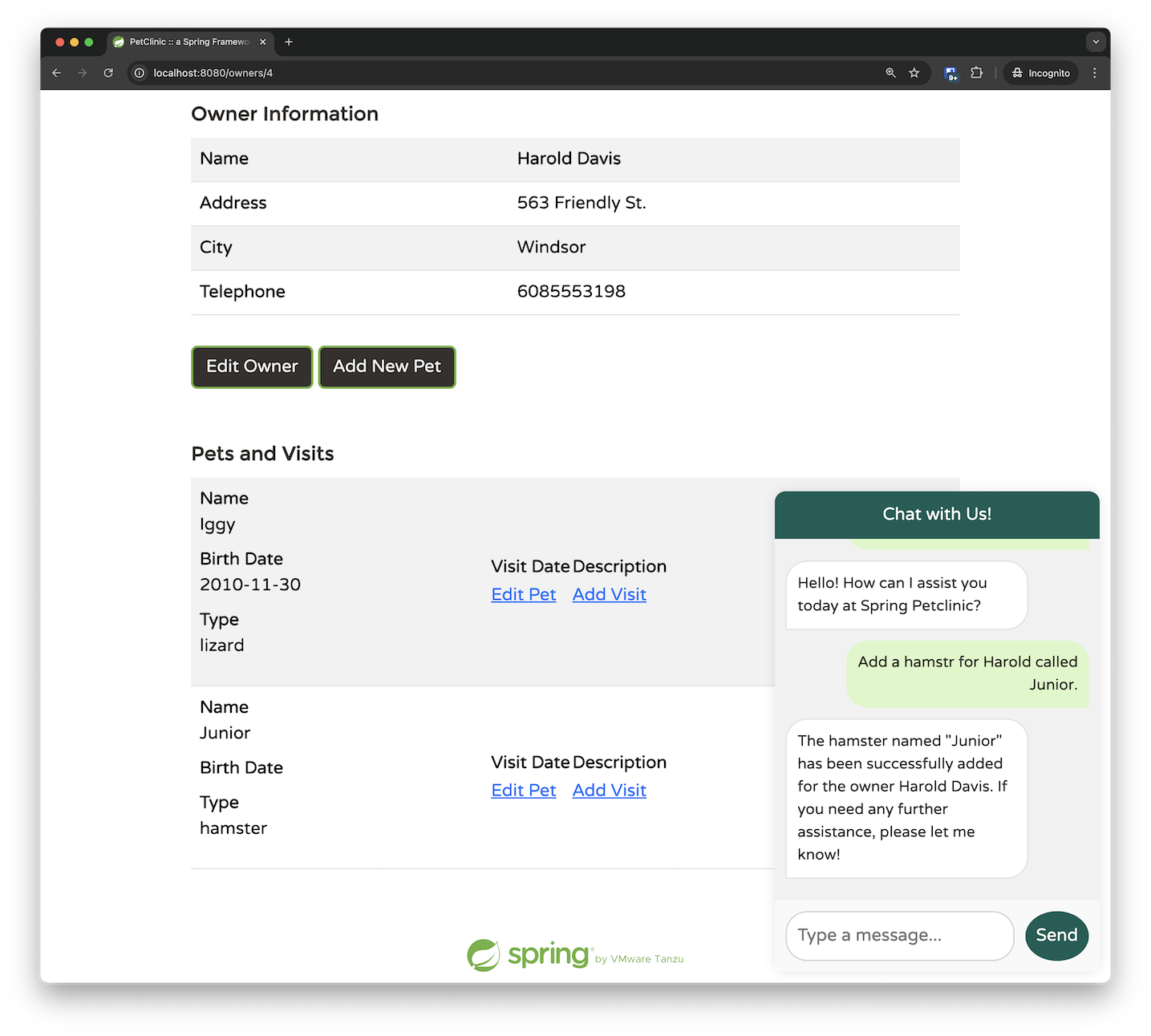
If you dig deeper, you'll find things become even more impressive. The AddPetRequest only passes the ownerId as a parameter; I provided the owner's first name instead of their ID, and the LLM managed to determine the correct mapping on its own. This indicates that the LLM chose to call the listOwners function before invoking the addPetToOwner function. By adding some breakpoints, we can confirm this behavior. Initially, we hit the breakpoint for retrieving the owners:

Only after the owner data is returned and processed do we invoke the addPetToOwner function:

My conclusion is this: with Spring AI, start simple. Provide the essential data you know is required and use short, concise bean descriptions. It’s likely that Spring AI and the LLM will "figure out" the rest. Only when issues arise should you begin adding more hints to the system.
The addOwner function is relatively straightforward. It accepts an owner and adds him/her to the system. However, in this example, we can see how to perform validation and ask follow-up questions using our chat assistant:
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include first and last name, "
+ "an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
record OwnerRequest(Owner owner) {
};
record OwnerResponse(Owner owner) {
};
The business implementation is straightforward:
public OwnerResponse addOwnerToPetclinic(OwnerRequest ownerRequest) {
ownerRepository.save(ownerRequest.owner());
return new OwnerResponse(ownerRequest.owner());
}
Here, we guide the model to ensure that the Owner within the OwnerRequest meets certain validation criteria before it can be added. Specifically, the owner must include a first name, a last name, an address, and a 10-digit phone number. If any of this information is missing, the model will prompt us to provide the necessary details before proceeding with the addition of the owner:
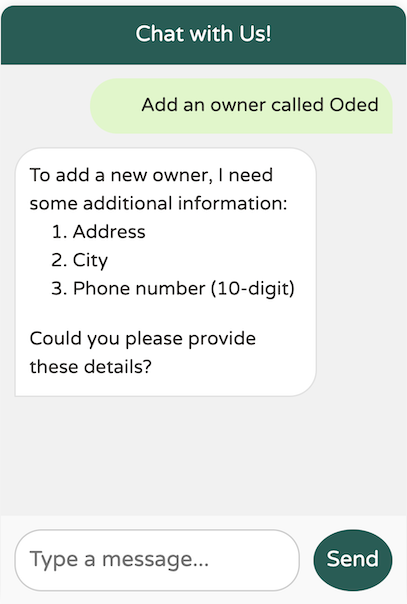
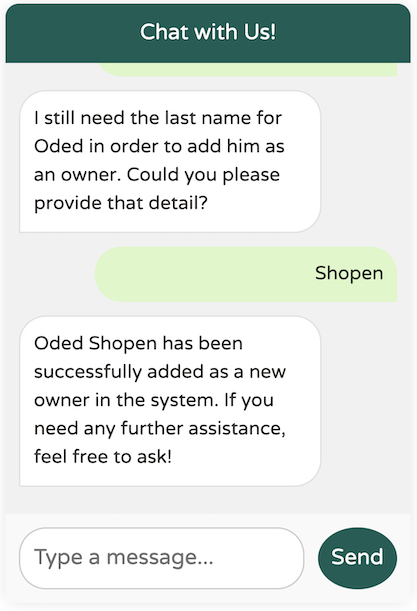
The model didn't create the new owner before requesting the necessary additional data, such as the address, city, and phone number. However, I don't recall providing the required last name. Will it still work?

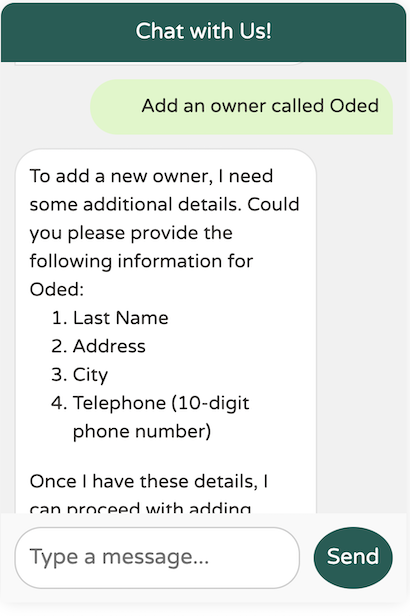
We've identified an edge case in the model: it doesn't seem to enforce the requirement for a last name, even though the @Description specifies that it is mandatory. How can we address this? Prompt engineering to the rescue!
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include a first name and a last name as two separate words, "
+ "plus an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
By adding the hint "as two separate words" to our description, the model gained clarity on our expectations, allowing it to correctly enforce the requirement for the last name.
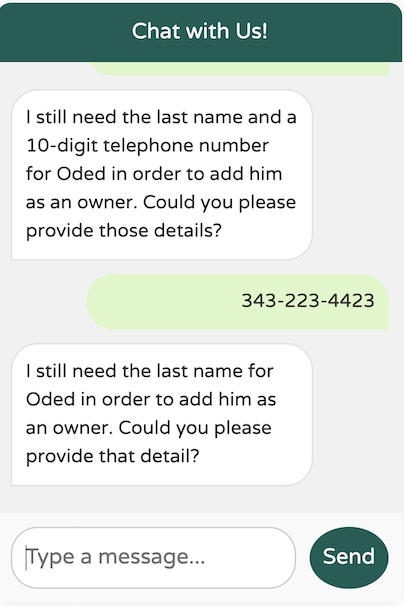
In the first part of this article, we explored how to harness Spring AI to work with large language models. We built a custom ChatClient, utilized Function Calling, and refined prompt engineering for our specific needs.
In Part II, we’ll dive into the power of Retrieval-Augmented Generation (RAG) to integrate the model with large, domain-specific datasets that are too extensive to fit within the Function Calling approach.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all