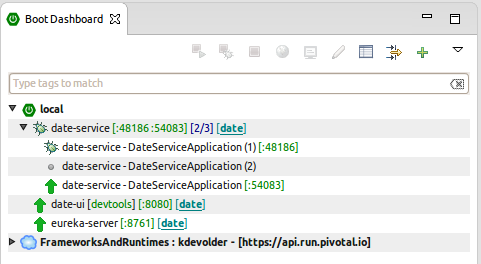
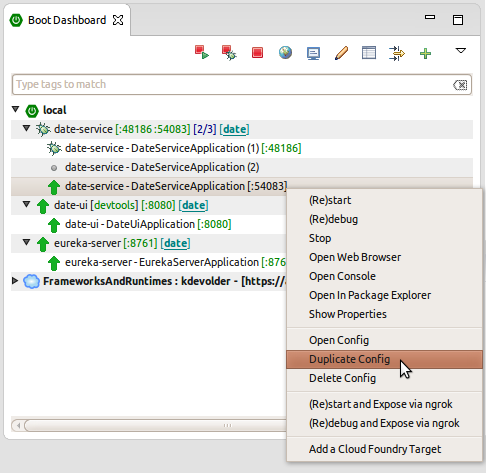
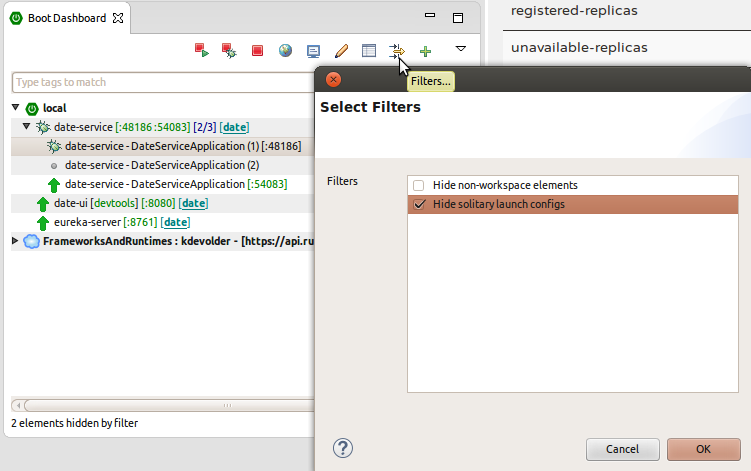
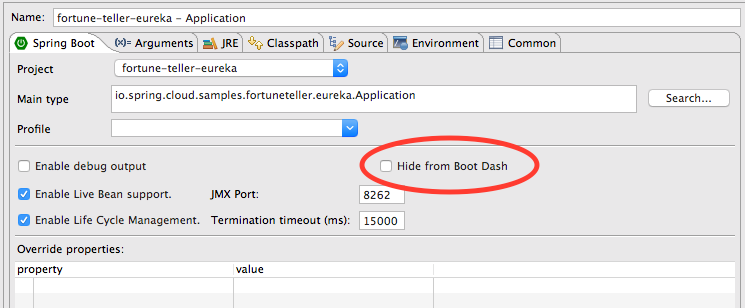
Welcome back Spring community,
the latest release 3.7.3 of the Spring Tool Suite introduces a number of new features around the Spring Boot Dashboard. Therefore we continue the blog post series that started last year and introduced you to the new way of working with Spring Boot based microservice projects in your IDE (you can find links to the previous parts at the bottom).
Cloud Foundry manifest files
In this new part of the series we take a closer look at Cloud Foundry manifest files. They are a Cloud Foundry concept used as a shortcut to define configurations for applications on Cloud Foundry. Instead of passing every argument and configuration to the command line when doing a “cf push”, you can put all your configuration data into a YAML file and pass that to the push command instead. More detailed information about Cloud Foundry Manifest files can be found here.
The early versions of the Spring Boot Dashboard already used the manifest files for deploying an app to CF if a file called “manifest.yml” existed in the project. This was done “under the hood” for your convenience. That was nice and useful. But it also caused confusion due to the “hidden nature” of this support.
Choose a manifest file when deploying an app
The new version of the Spring Boot Dashboard supports Cloud Foundry manifest files as a first-class citizen. This starts to show up when you deploy an application from within the Boot Dashboard to a Cloud Foundry target for the first time. A dialog comes up and asks you which manifest file should be used for this deployment operation.
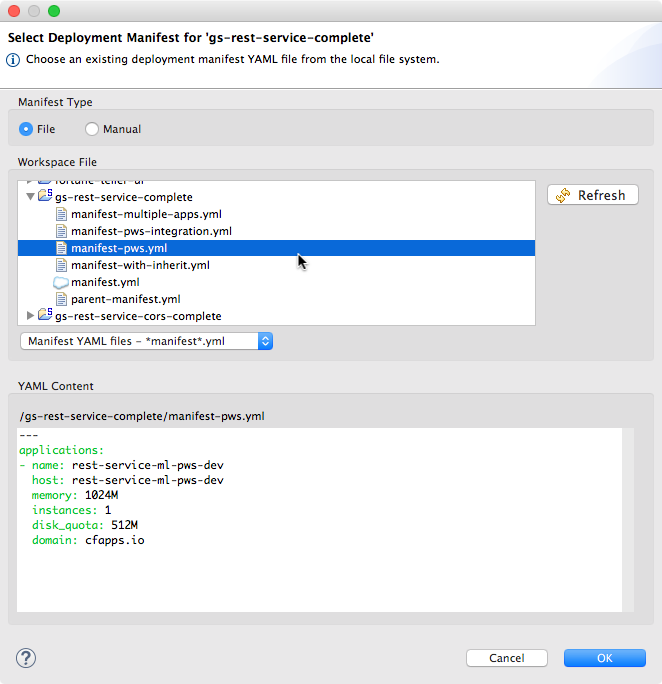
This dialog allows you to select the manifest file you would like to use to deploy the app. This also allows you to have multiple manifest files in your projects - for example for different spaces on Cloud Foundry or different deployment environments. You can also deploy the same app multiple times to the same Cloud Foundry target by choosing a different manifest file for each deploy operation.
The dialog shows the content of the selected manifest file, so that you can verify that you selected the correct one. And if something is wrong inside of the manifest file, you don’t need to go back to the main IDE workbench, open the file, edit it, save it, and go back to the deploy operation. Instead edit the manifest file content directly within the dialog. This makes deploying an app to Cloud Foundry really easy.
The boot dashboard will remember your choice and use the same manifest file again if you update your project on Cloud Foundry. That also means that changes to the manifest file will be taken into account the next time the app is re-deployed to Cloud Foundry (during a boot dashboard restart operation, for example).
Of course you can change your mind and decide to choose a different manifest file. An action in the context menu allows you to open the same “choose the manifest file” dialog and make a different choice. The next redeploy of the app will take that change into account. You can also use this dialog to quickly check which manifest file is currently associated with the project.

Deploying without a manifest file
Sometimes you don’t already have a manifest file or you don’t want to use an existing manifest file. In that case you can choose the “manual mode” in the dialog.
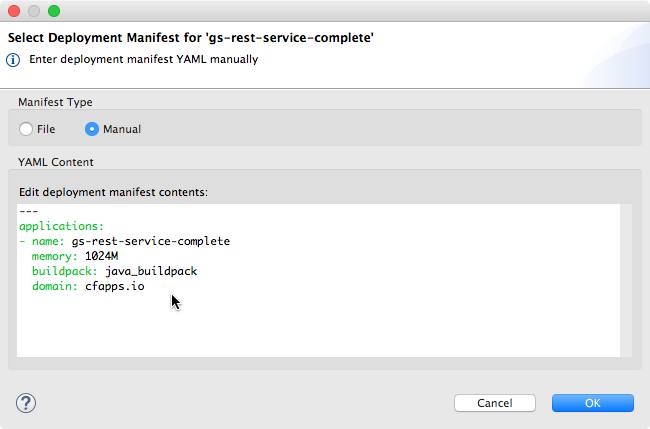
It opens up an editor area for a temporary manifest file and fills that with some default content. You can edit this temporary manifest content, add properties or change existing ones. This allows you to completely define the way the app should be deployed to Cloud Foundry.
The content of that temporary manifest is not stored anywhere (we may add a convenience option to quickly save the manually entered manifest content to a new file) and the IDE doesn’t remember it for the next time you update the application on Cloud Foundry. Instead the existing configuration on Cloud Foundry will be kept and used while updating the application.
This is also true if you have used a manifest file in the past and then decided to switch to the manual mode. Subsequent updates to the application will keep the configuration on Cloud Foundry untouched.
Changed configurations on CF
Let’s imagine you have used a manifest file to deploy your application from within the boot dashboard to Cloud Foundry. Then you go to the web console and add a service to the already deployed app - or change the memory settings, scale it up, or do similar changes to the configuration. If you go back to the boot dashboard, maybe change some code of the app, and restart (and therefore update) the app on Cloud Foundry, the boot dashboard would use the manifest file again - and trash all the changes to the configuration that you made on CF. To avoid this, the boot dashboard checks for configuration changes on Cloud Foundry when re-deploying an application that uses a manifest file. If a configuration mismatch is found, it opens up a diff and merge dialog - and displays the detailed changes.

This feature prevents you from override configuration changes by accident. And it is a powerful dialog that lets you merge configuration changes on CF to your local manifest file. You can merge individual changes as well as all changes at once. That makes it easy to update the local manifest file with those changes and you can continue to use the manifest file when updating the application in the future.
In case you don’t want those configuration changes on CF to be reflected in your local manifest file, select the “forget manifest” button and the boot dashboard will keep the configuration on Cloud Foundry as it is. It switches the application to the “manual mode” deployment.
Again, if you would like to explicitly change those settings, go to the context menu and choose the “select manifest” operation.
Editing manifest files
While the Cloud Foundry manifest files are a nice and clean way to configure your application for Cloud Foundry, it can be cumbersome to edit those files. Luckily the new version of the Spring Tool Suite comes with a specialized editor for Cloud Foundry manifest files.

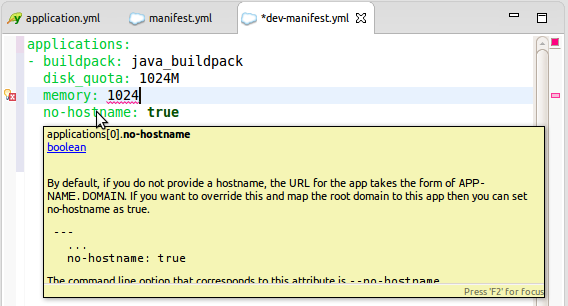
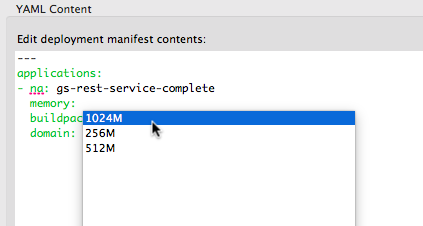
It provides nice content-assist for property names and selected property values.

If you hover over the properties, you get additional help about the property and examples how and when to use it.
The file is also validated while typing. Reconcile errors are showing up directly in the editor in the same way they do in Spring Boot property files or when editing Java code.
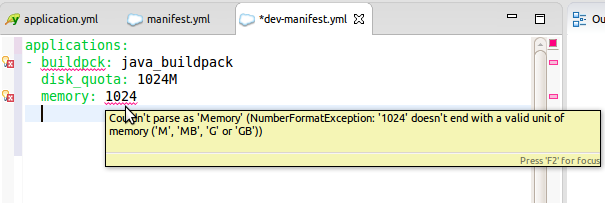
And the good news is: this advanced editing support is available in the “select the manifest file” dialog, too (for example when working on the manual manifest or changing the selected manifest file content):
Coming up
The next part of this blog series will cover the new support for working with multiple launch configurations for local Spring Boot applications. Stay tuned.
The Spring Boot Dashboard blog series:
If you happen to be in Barcelona mid May (never a bad time to be in Barcelona anyway!), don't miss the chance to join the Spring I/O conference where I'll be presenting on the latest and greatest in Spring in general. Also, the registration for SpringOne Platform (early August, Las Vegas) has opened recently, in case you want to benefit from early bird ticket pricing.